云边协同的 RTC 如何助力即构全球实时互动业务实践
作者:即构科技
由 51 CTO 主办的“WOT 全球技术创新大会 2023·深圳站”于 11 月 24 日 - 25 日召开,即构科技后台技术总监肖潇以“边缘容器在全球音视频场景的探索与实践”为主题进行分享。 边缘计算作为中心云计算的补充,通过边缘容器架构和云边协同,为音视频、云游戏、元宇宙等场景带来了更好的用户体验和业务价值。

讲师现场风采
肖潇提到,即构这种实时互动的业务场景,天然就是边缘计算很契合的方式,原因就是边缘计算在降低时延、成本优化、提升并发、降低故障影响等方面有十分明显的优势。即构科技基于在实时互动领域的多年技术积累与实践,落地了云边协同的全球音视频云架构:多云基础设施、边缘容器、全球多中心、MSDN (Massive Serial Data Network)海量有序数据网络全球传输网络。这也帮助即构建立了 “生于云、长于云”的云原生音视频云服务,提升实时音视频云服务质量和运维效率,通过多云 serverless 做好容灾, 并进一步优化成本。
下面是肖潇在现场演讲的内容回顾:
边缘计算遇到的问题及落地挑战
即构使用边缘计算多年,在最开始我们的主要策略是租赁全球各种大规模的虚拟机和物理机。不同业务、不同的客户集群各自独占边缘算力,进行自己系统内部的资源冗余,导致边缘整体的利用率不高,成本压力大。其次,面向边缘没有统一的运维体系,各业务建设自己的业务支持系统,容量管理、扩缩容不统一效率比较低下。另外,中心部署的服务已经全面云原生化,运维团队在管理中心和边缘的服务需要在两种思维方式以及在两套运维设施中切换,这很割裂,期待有一些新的变化。
我们希望云原生的边缘容器能带来三方面的变化:
- 通过底层计算资源复用最大化的利用算力和带宽实现成本的极致优化;
- 通过云原生的弹性伸缩、多容器管理、版本更新机制大幅提升运维效率和可靠性;
- 通过边缘容器的落地,构建一个统一的云边一体化的云原生基础设施。
然而,企业在落地边缘容器时会面临诸多挑战,首先,业界没有统一的边缘容器标准,从产品维度,他们都拥有相同的产品关键字:云边协同、边缘自治、单元化部署。我们预研梳理落地边缘容器的一些挑战,例如,音视频业务是强有状态服务,如何云原生化?不同服务规格差异较大,如何调度?音视频服务经常是两个进程协同完成工作,如何做到 pod 多进程完全独立的灰度发布?云边网络中断业务如何处理?云边通信的流量成本能否降到很低?如何提升运维效率等等挑战。
实时互动业务的落地实践
带着这些挑战进行思考,即构基于在实时互动领域的多年技术积累与实践,落地了云边协同的全球音视频云架构:多云基础设施、边缘容器、全球多中心、MSDN 全球传输网络。即构没有做成完全分布式去中心化的架构,是因为我们的业务是全球实时互动场景,500+ 机房之间 full mesh 进行同步效率太低,有中心的参与能大幅提升信息同步效率。
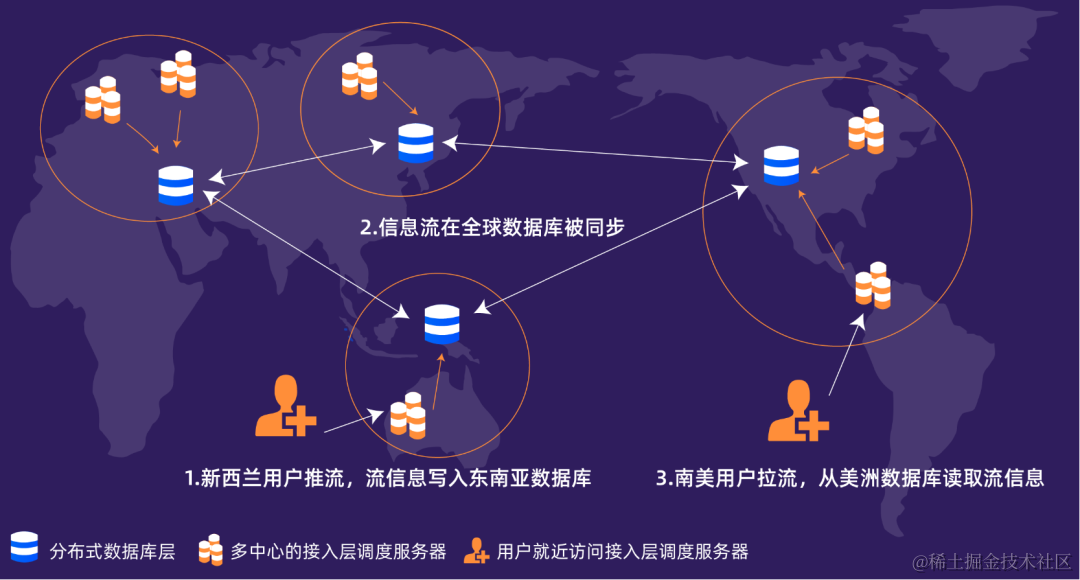
云边协同的全球音视频云架构
1、音视频服务云原生化
音视频服务是强有状态业务
音视频服务有点类似游戏服务器,有玩家在玩游戏,不能轻易更新和缩容。音视频服务器除了有海量的用户接入,还有服务器之间的级联。服务器级联形成了一个流的分发网络,服务器节点的变化会导致分发网络的重建。虽然会通过 SDK 重试等策略降低这个网络重建的成本和对用户体验的影响,但是还是希望发布、扩缩容这些运维操作能尽量降低对音视频业务的影响。
具体来看,希望做到 IP 端口固定的无损直连;镜像更新,pod 不重建,降低 pod 重建重新调度耗时对业务影响;希望容器更新过程中,镜像拉取耗时是极短的,来降低推拉流的中断。有状态业务的扩容需要有多种业务指标来触发,缩容需要很精确的控制。一个 pod 内有两个容器,引擎容器和配套业务处理容器,希望这两个容器能够做到各自独立发布。有一些定向运维操作的需求。
主机网络减少网络损耗
我们选择主机网络模式来减少网络损耗,这样的好处是不需要经过容器额外的网络虚拟化层,但是也带来了端口冲突的问题。我们新建了一个 Daemonset,端口管理的服务,在节点上 pod 启动的时候负责进行端口的分配。
工作负载的选择、更新策略
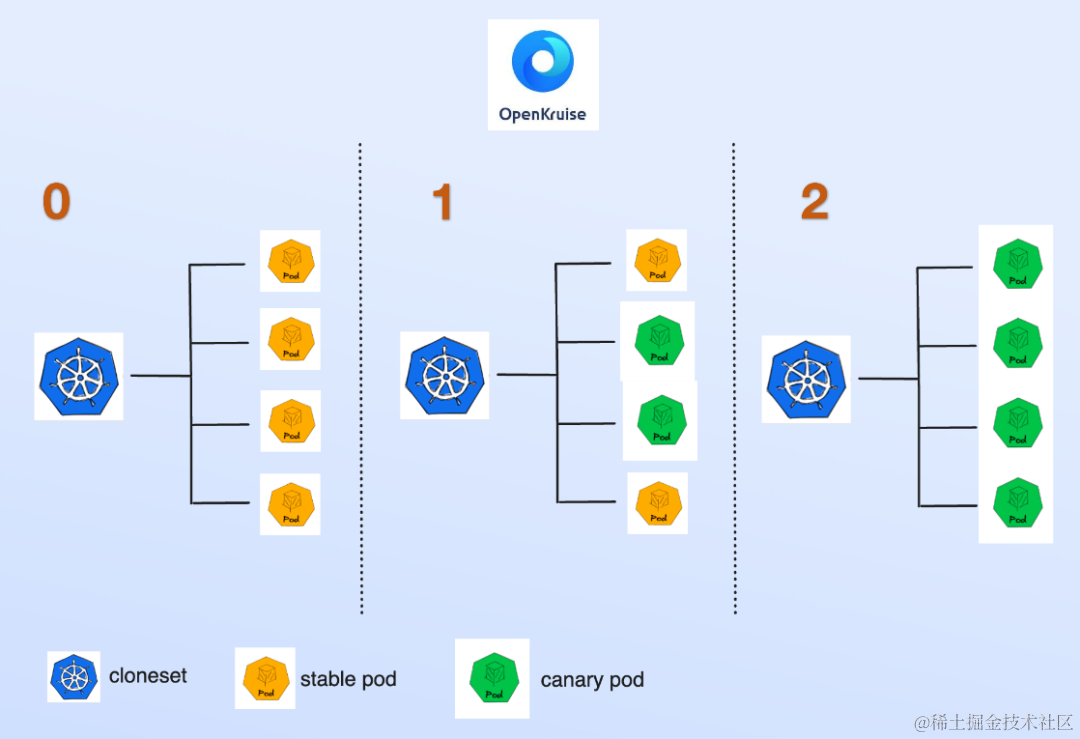
前面我们提到 K8s 自带的 workload 不满足音视频业务的生命周期管理,在这里我们选择了 openKruise 的 cloneset 作为我们的工作负载,关注它主要是看中它如下几块的能力:原地升级、指定 pod 缩容、sidecarset 实现 sidecar 容器部署的能力、镜像预热的能力。
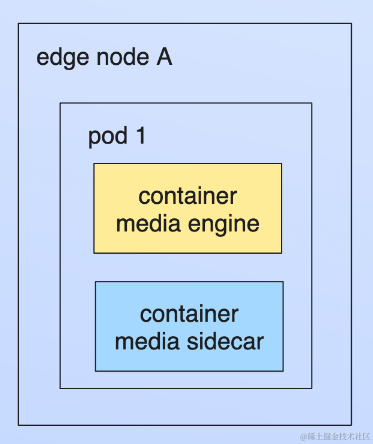
如上图所示,音视频引擎作为主容器、配套业务处理容器作为 sidecar 容器 ,sidecar 容器通过 webhook 注入到 pod 中,通过 cloneset 和 sidecarset 两种资源实现两个容器的独立灰度发布。社区的版本 sidecarset 并不支持 env from metadata 的原地升级,我们完善了这个能力,后续也会提 PR 贡献给到社区。基于 cloneset 和 sidecarset,我们能进行下图所示的基于 partition 的百分比多阶段灰度发布。
原地升级不能解决所有的更新问题
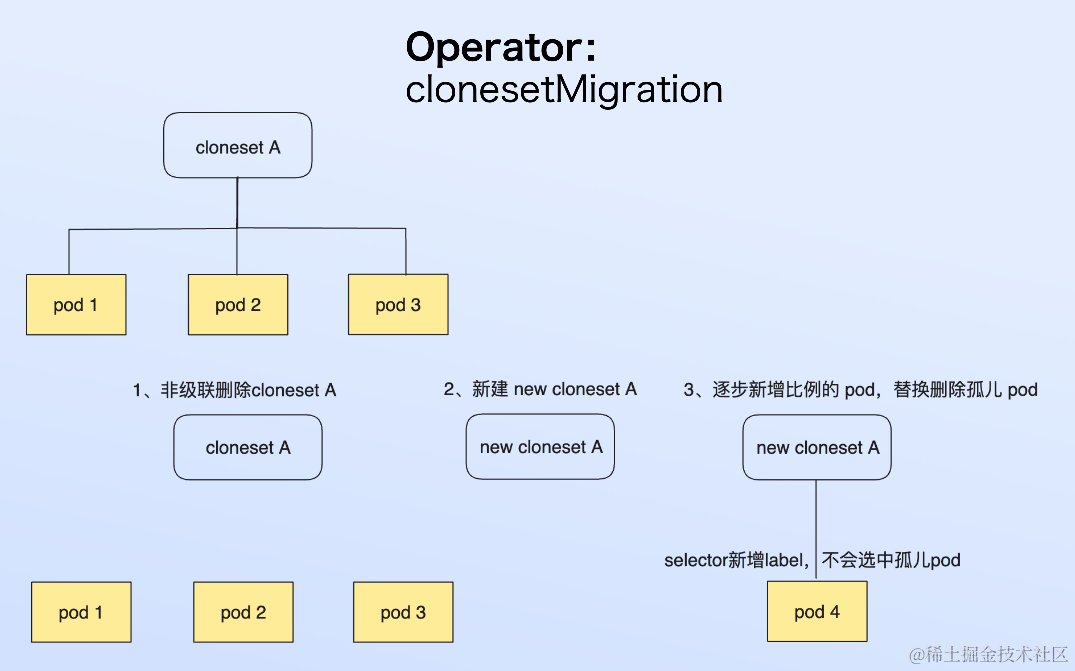
我们知道原地升级的触发条件主要是 spec container 的镜像变化以及 env from metadata 中 label 和注解的变化,但是 cloneset yaml 的其他字段需要修改的时候我们怎么能做到避免 pod 的重建从而使对业务的影响接近于零呢,即还能保持 IP 端口的稳定?对这种情况我们实现了一个 clonesetmigration 的 operator 来协调这个过程。
镜像预热
我们在方案选型的时候对比分析了镜像预热和边缘 P2P 镜像分发这两种方式。对比的过程中我们发现 dragonfly 这种 P2P 镜像分发对于边缘场景运维还是偏复杂,因为它要求一个 P2P 网络中服务网络必须是互通的,那对于较大的边缘机房 P2P 网络是内网能有很好的效果,但对于多个较小的边缘机房又需要分区域组成一个外网的 P2P 网络,但是音视频又是高带宽的服务,为了不影响业务在节点和任务的维度都会要求有限速,明显的限速又影响到 P2P 镜像的拉取效果。于是回到了我们的核心诉求,原地升级时镜像拉取的耗时足够低,那 OpenKruise 每一阶段灰度发布时 node 的提前镜像预热+镜像仓库多地域部署已经能满足我们的诉求。
音视频场景下的弹性伸缩
音视频场景下弹性伸缩我们区别于社区的 HPA 方案,我们做的是带音视频业务状态的伸缩方案,扩容会多维度指标综合评估,从带宽、PPS、推拉流数、CPU、内存等多指标进行计算,缩容有点特殊,在有用户在推拉流的时候不能直接进行缩容操作,需要做业务的无损清理,不然容易带来用户的黑屏、卡顿。如果我们设计了 pod 业务状态的状态机,有初始化、已分配、墓碑态和等待被删除几种状态。其中墓碑态是关键的状态,进入这个状态会从业务层面不进行新请求和流量被调度进来等待流量的自然消亡,以及超时后的接近无损的驱赶和清理,当然如果墓碑态的过程中流量上涨会将业务状态回退到已分配状态继续服务业务。
2、质量和运维效率提升
在边缘容器的质量和运维效率提升方面,即构在成立之初就自研了“海量有序数据网络 MSDN”,实时探测网络质量,可以实现全球范围内优质的智能调度及路由,链路故障秒级恢复,大幅降低云边断网概率,提升数据传输速度及可靠性。即构还基于机器学习算法预测边缘机房未来利用率,生成扩容、缩容资源 node 数,然后基于这个推荐数据自动进行边缘节点购买/纳管、cordon/drain/节点退订,实现边缘资源池的智能化推荐、扩缩。此外,即构通过全球边缘容器控制面的多集群管理,实现全球资源统一管理。
肖潇还提到,关于云边协同的另一种有趣的方式——多云 Serverless 容灾。
当边缘容器控制面所在的中心 region 故障的时候,因为边缘自治的原因,边缘容器依旧可以正常运转,但是会影响到服务的扩容能力和容量水位。这个时候我们的一种容灾方式是通过在多云商不同中心机房的 serverless 集群的扩容进行这部分弹性容量的补齐。其次,用中心机房 Serverless 承载边缘资源池的突发溢出流量也非常有价值。这种溢出往往是临时性的突然打高,通过边缘带宽承载日常流量加 Serverless 流量计费承载突发流量,可以实现网络成本的最优组合。这里也充分用到了中心机房 Serverless 极致的弹性能力。
3、成本优化
边缘资源的最大化共享。使用边缘容器的边缘资源池能够做到不同的业务集群或业务角色能共享相同的资源池,通过整个资源池的资源冗余来避免在业务集群和服务维度各自的资源冗余。其次我们有全局多级资源池调度,上一级满了会溢出到下一级,实现在资源池全局资源的复用,和任意区域 N-2 机房资源的冗余。
资源调度策略。基于实时音视频场景思考,我们把默认的 Spread 调度策略改成 Binpack 调度策略,它会优先将 pod 调度到资源消耗较多的节点,多个 pod 会优先使用同一节点来提高整个资源的利用率,相较于虚拟机和物理机时代工作负载提升了一倍。
关于成本,即构关注如何大幅降低云边通信的流量的成本。以 OpenYurt 为例,首先要尽量减少 Service 和 EndpointSlice 的使用;第二,kubelet、daemonset list-watch 资源要 label 筛选本节点的数据,减少关注度;第三,以 Openyurt 为例,通过 Pool-Coordinator 和 Yurthub 的协同,实现单一节点池内云边只有一份 pool scope data 数据通信,当然 pool-coordinator 机制带来的好处,能区分出云边断网和节点宕机。
未来展望
未来即构会从三方面入手,一是探索更适合业务的调度算法, 对计算密集型的业务开放 CPU 拓扑感知调度的能力、提供 GPU 调度从而实现更全的业务覆盖;其次,通过更多工具链系统的建设和更多的能力抽象,进一步降低业务接入边缘容器的成本, 实现分钟级的部署;第三,把更多的能力在边缘侧进行提供。
即构将会继续推动边缘容器在全球音视频场景的进一步探索和应用!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 怀念一代传奇,陈皓与他的《左耳听风:传奇程序员练级攻略》
- 【2】Docker Compose编排
- 安科瑞有序充电运营场站落成-安科瑞 蒋静
- 尼康、索尼和佳能各大行业利用先进防伪技术对抗人工智能造假
- 二分查找——函数实现
- Yum仓库架构解析与搭建实践
- PHP 数据类型面试题
- 【Kubernetes 】Kubernetes 网络之 Ingress 配置详解
- 刚学C/C++,使用的是CLion,想要在同一个项目里面运行多个相互独立脚本?
- 环保行业的物联网升级:采用钡铼技术R10