AutoSub 中文视频字幕生成,语音识别翻译的工具
发布时间:2024年01月04日
AutoSub 使用记录
AutoSub
Autosub 是用于自动语音识别和字幕生成的实用程序。它以视频或音频文件为输入,执行语音活动检测以查找语音区域,向 Google Web Speech API 发出并行请求以生成这些区域的转录,(可选)将它们翻译成不同的语言,最后将生成的字幕保存到磁盘。它支持多种输入和输出语言(要查看哪种语言,请使用参数运行实用程序),并且目前可以生成SRT格式或简单JSON格式的字幕.。
官网的链接在这里。
安装流程如下
AutoSub 新工具
AutoSub和AutoSub基础上开发的新工具都需要通过梯子使用。我在使用AutoSub时出现了问题,因此选择这个新工具。下载解压缩后,进入如下路径使用:
运行如下类型指令(一定要挂梯子),进行转化:

转化需要几分钟
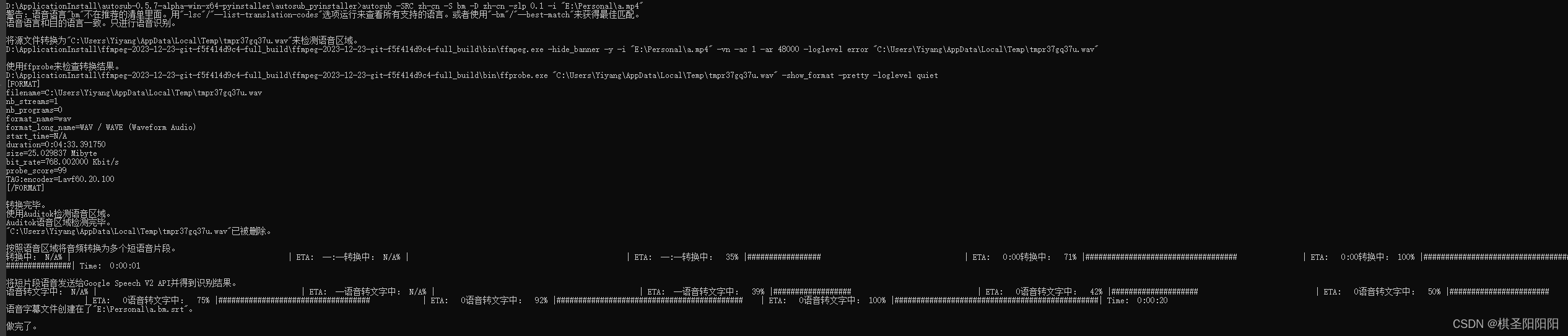
可调参数
由于是基于AutoSub开发的工具,因此指令是通用的:
用法:autosub [-i 路径] [选项]
为视频/音频/字幕文件自动生成字幕。
输入选项:
控制输入的选项。
-i 路径, --input 路径 用于生成字幕文件的视频/音频/字幕文件。如果输入文件是字幕文件,程序仅会对其进行翻译。(参数个数为1)
-er 路径, --ext-regions 路径
提供外部语音区域(时间轴)的字幕文件。该字幕文件格式需要是pysubs2所支持的。使用后会替换掉默认的自动 寻
找语音区域(时间轴)的功能。(参数个数为1)
-sty [路径], --styles [路径]
Valid when your output format is "ass"/"ssa". Path to
the subtitles file which provides "ass"/"ssa" styles
for your output. If the arg_num is 0, it will use the
styles from the : "-er"/"--external-speech-regions".
More info on "-sn"/"--styles-name". (arg_num = 0 or 1)
-sn [样式名 [样式名 ...]], --style-name [样式名 [样式名 ...]]
当输出格式为"ass"/"ssa"且"-sty"/"--styles"选项提供参数时有效。给输出字幕文件行提
供"ass"/"ssa"字幕的样式名。如果不提供该选项,字幕行会使用文件中的第一个样式名。如果参数个数为1,
字幕行会使用来自"-sty"/"--styles"的参数作为样式名。如果参数个数为2,源语言字幕行会使用第一
个参数作为样式名。目标语言行使用第二个。(参数个数为1或2)
语言选项:
控制语言的选项。
-S 语言代码, --speech-language 语言代码
用于语音识别的语言代码/语言标识符。推荐使用Google Cloud Speech的参考语言代码。错误的输入
不会终止程序。但是后果自负。参考:https://cloud.google.com/speech-to-
text/docs/languages(参数个数为1)(默认参数: None)
-SRC 语言代码, --src-language 语言代码
用于翻译的目标语言的语言代码/语言标识符。如果没有提供,使用py-
googletrans来自动检测源语言。(参数个数为1)(默认参数为auto)
-D 语言代码, --dst-language 语言代码
用于翻译的目标语言的语言代码/语言标识符。(参数个数为1)(默认参数为None)
-bm [模式 [模式 ...]], --best-match [模式 [模式 ...]]
使用langcodes为输入获取一个最佳匹配的语言代码。仅在使用py-googletrans和Google
Speech V2时起作用。如果langcodes未安装,使用fuzzywuzzy来替代。可选的模式:s,
src, d, all。"s"指"-S"/"--speech-
language"。"src"指"-SRC"/"--src-language"。"d"指"-D"/"--
dst-language"。(参数个数在1到3之间)
-mns integer, --min-score integer
一个介于0和100之间的整数用于控制以下两个选项的匹配结果组,"-lsc"/"--list-speech-
codes"以及"-ltc"/"--list-translation-codes"或者在"-bm"/"--
best-
match"选项中的最佳匹配结果。结果会是一组“好的匹配”,其分数需要超过这个参数的值。(参数个数为1)
输出选项:
控制输出的选项。
-o 路径, --output 路径 输出字幕文件的路径。(默认值是"input"路径和适当的文件名后缀的结合)(参数个数为1)
-F 格式, --format 格式 输出字幕的格式。如果没有提供该选项,使用"-o"/"--output"参数中的后缀。如果"-o"/"--
output"参数也没有提供扩展名,那么使用"srt"。在这种情况下,如果"-i"/"--
input"的参数是一个字幕文件,那么使用和字幕文件相同的扩展名。(参数个数为1)(默认参数为srt)
-y, --yes 避免任何暂停和覆写文件的行为。如果参数有误,会直接停止程序。(参数个数为0)
-of [种类 [种类 ...]], --output-files [种类 [种类 ...]]
输出更多的文件。可选种类:regions,src,full-src,dst,bilingual,dst-
lf-src,src-lf-
dst,all。(时间轴,源语言字幕,完整语音识别结果,目标语言字幕,双语字幕,dst-lf-
src,,src-lf-dst,所有)full-
src:由语音转文字API得到的json格式的完整语音识别结果加上开始和结束时间。dst-lf-
src:目标语言和源语言在同一字幕行中,且目标语言先于源语言。src-lf-dst:源语言和目标语言在同一字
幕行中,且源语言先于目标语言。(参数个数在6和1之间)(默认参数为['dst'])
-fps float, --sub-fps float
当输出格式为"sub"时有效。如果提供了该参数,它会取代原有的对输入文件的帧率检查。参考:https://p
ysubs2.readthedocs.io/en/latest/api-
reference.html#supported-input-output-formats(参数个数为1)
语音选项:
控制语音转文字的选项。
-sapi API代码, --speech-api API代码
选择使用Speech-to-Text API。当前支持:gsv2:Google Speech V2
(https://github.com/gillesdemey/google-speech-v2)。
gcsv1:Google Cloud Speech-to-Text V1P1Beta1
(https://cloud.google.com/speech-to-
text/docs)。xfyun:讯飞开放平台语音听写(流式版)WebSocket API(https://
www.xfyun.cn/doc/asr/voicedictation/API.html)。baidu:
百度短语音识别/短语音识别极速版(https://ai.baidu.com/ai-doc/SPEECH/Vk38lxily)(参数个数为1)(默认参数为gsv2)
-skey key, --speech-key key
Google Speech-to-Text API的密钥。(参数个数为1)当前支持:gsv2:gsv2的AP
I密钥。(默认参数为免费API密钥)gcsv1:gcsv1的API密钥。(如果使用了,可以覆盖
"-sa"/"--service-account"提供的服务账号凭据)
-sconf [路径], --speech-config [路径]
使用语音转文字识别配置文件来发送请求。取代以下选项:"-S", "-asr",
"-asf"。目前支持:gcsv1:Google Cloud Speech-to-Text
V1P1Beta1 API密钥配置参考:https://cloud.google.com/speech-
to-
text/docs/reference/rest/v1p1beta1/RecognitionConfig 服
务账号配置参考:https://googleapis.dev/python/speech/latest/ga
pic/v1/types.html#google.cloud.speech_v1.types.Recogni
tionConfig 。xfyun:讯飞开放平台语音听写(流式版)WebSocket
API(https://console.xfyun.cn/services/iat)。baidu:
百度短语音识别/短语音识别极速版(https://ai.baidu.com/ai-doc/SPEECH/ek
38lxj1u)。如果参数个数是0,使用const路径。(参数个数为0或1)(const为config.js
on)
-mnc float, --min-confidence float
Google Speech-to-Text API用于识别可信度的回应参数。一个介于0和1之间的浮点数。可信
度越高意味着结果越好。输入这个参数会导致所有低于这个结果的识别结果被删除。参考:https://github
.com/BingLingGroup/google-
speech-v2#response(参数个数为1)(默认参数为0.0)
-der, --drop-empty-regions
删除所有没有语音识别结果的空轴。(参数个数为0)
-sc integer, --speech-concurrency integer
用于Speech-to-Text请求的并行数量。(参数个数为1)(默认参数为10)
Translation Options:
Options to control translation.
-tapi API代码, --translation-api API代码
Choose which translation API to use. Currently
support: pygt: py-googletrans (https://py-
googletrans.readthedocs.io/en/latest/). man: Manually
translate the content by write a txt or docx file and
then read it. (arg_num = 1) (default: pygt)
-tf 格式, --translation-format 格式
Choose which output format for manual translation to
use. Currently support: docx, txt. (arg_num = 1)
(default: docx)
-mts integer, --max-trans-size integer
(Experimental)Max size per translation request.
(arg_num = 1) (default: 4000)
-slp 秒, --sleep-seconds 秒
(Experimental)Seconds for py-googletrans to sleep
between two translation requests. (arg_num = 1)
(default: 1)
-surl [URL [URL ...]], --service-urls [URL [URL ...]]
(Experimental)Customize py-googletrans request urls.
Ref: https://py-googletrans.readthedocs.io/en/latest/
(arg_num >= 1)
-ua User-Agent headers, --user-agent User-Agent headers
(Experimental)Customize py-googletrans User-Agent
headers. Same docs above. (arg_num = 1)
-doc, --drop-override-codes
在翻译前删除所有文本中的ass特效标签。只影响翻译结果。(参数个数为0)
-tdc [chars], --trans-delete-chars [chars]
将指定字符替换为空格,并消除每句末尾空格。只会影响翻译结果。(参数个数为0或1)(const为,。!)
字幕转换选项:
控制字幕转换的选项。
-mjs integer, --max-join-size integer
(Experimental)Max length to join two events. (arg_num
= 1) (default: 110)
-mdt 秒, --max-delta-time 秒
(Experimental)Max delta time to join two events.
(arg_num = 1) (default: 0.2)
-dms string, --delimiters string
(Experimental)Delimiters not to join two events.
(arg_num = 1) (default: !()*,.:;?[]^_`~)
-sw1 words_delimited_by_space, --stop-words-1 words_delimited_by_space
(Experimental)First set of Stop words to split two
events. (arg_num = 1)
-sw2 words_delimited_by_space, --stop-words-2 words_delimited_by_space
(Experimental)Second set of Stop words to split two
events. (arg_num = 1)
-ds, --dont-split (Experimental)Don't split. Just merge. (arg_num = 0)
-jctl [string [string ...]], --join-control [string [string ...]]
Control the way to join and split subtitles' events.
Key tag choice: ["\k", "\ko", "\kf", (None)] (default:
None). Events manual adjustment: ["man", "auto-ext",
"auto-punct", (None)] (default: None). You can choose
"man" and "auto-ext" method at the same time which
allows you to automatically adjust events at first and
then manually adjust them. Capitalized the first word
and add a full stop: ["cap", (None)] (default: None).
Trim regions after processing: ["trim", (None)]
(default: None). Keep the indexes from subtitles
events when input is a subtitles file: ["keep-events",
(None)] (default: None). (arg_num >= 1)
网络选项:
控制网络的选项。
-hsa, --http-speech-api
将Google Speech V2 API的URL改为http类型。(参数个数为0)
-hsp [URL], --https-proxy [URL]
通过设置环境变量的方式添加https代理。如果参数个数是0,使用const里的代理URL。(参数个数为0或1
)(const为https://127.0.0.1:1080)
-hp [URL], --http-proxy [URL]
通过设置环境变量的方式添加http代理。如果参数个数是0,使用const里的代理URL。(参数个数为0或1)
(const为http://127.0.0.1:1080)
-pu 用户名, --proxy-username 用户名
设置代理用户名。(参数个数为1)
-pp 密码, --proxy-password 密码
设置代理密码。(参数个数为1)
其他选项:
控制其他东西的选项。
-h, --help 显示autosub的帮助信息并退出。(参数个数为0)
-V, --version 显示autosub的版本信息并退出。(参数个数为0)
-sa 路径, --service-account 路径
设置服务账号密钥的环境变量。应该是包含服务帐号凭据的JSON文件的文件路径。如果使用了,会被API密钥选项 覆
盖。参考:https://cloud.google.com/docs/authentication/gett
ing-started
当前支持:gcsv1(GOOGLE_APPLICATION_CREDENTIALS)(参数个数为1)
音频处理选项:
控制音频处理的选项。
-ap [模式 [模式 ...]], --audio-process [模式 [模式 ...]]
控制音频处理的选项。如果没有提供选项,进行正常的格式转换工作。"y":它会先预处理输入文件,如果成功了 ,在语
音转文字之前不会对音频进行额外的处理。"o":只会预处理输入音频。("-k"/"--
keep"选项自动置为真)"s":只会分割输入音频。("-k"/"--
keep"选项自动置为真)以下是用于处理音频的默认命令: -hide_banner -i "{in_}"
-vn -af "asplit[a],aphasemeter=video=0,ametadata=selec
t:key=lavfi.aphasemeter.phase:value=-0.005:function=le
ss,pan=1c|c0=c0,aresample=async=1:first_pts=0,[a]amix"
-ac 1 -f flac -loglevel error "{out_}" | -hide_banner
-i "{in_}" -af "lowpass=3000,highpass=200" -loglevel
error "{out_}" |
D:\Anaconda3\envs\WordsRecognition\Scripts\ffmpeg-
normalize.exe -v "{in_}" -ar 44100 -ofmt flac -c:a
flac -pr -p -o "{out_}"(参考:https://github.com/stevenj/
autosub/blob/master/scripts/subgen.sh
https://ffmpeg.org/ffmpeg-filters.html)(参数个数介于1和2之间)
-k, --keep 将音频处理中产生的文件放在输出路径中。(参数个数为0)
-apc [命令 [命令 ...]], --audio-process-cmd [命令 [命令 ...]]
这个参数会取代默认的音频预处理命令。每行命令需要放在一个引号内。输入文件名写为{in_}。输出文件名写为{o
ut_}。(参数个数大于1)
-ac integer, --audio-concurrency integer
用于ffmpeg音频切割的进程并行数量。(参数个数为1)(默认参数为10)
-acc 命令, --audio-conversion-cmd 命令
(实验性)这个参数会取代默认的音频转换命令。"[", "]" 是可选参数,可以移除。"{",
"}"是必选参数,不可移除。(参数个数为1)(默认参数为 -hide_banner -y -i
"{in_}" -vn -ac {channel} -ar {sample_rate} -loglevel
error "{out_}")
-asc 命令, --audio-split-cmd 命令
(实验性)这个参数会取代默认的音频转换命令。相同的注意如上。(参数个数为1)(默认参数为 -y -ss
{start} -i "{in_}" -t {dura} -vn -ac [channel] -ar
[sample_rate] -loglevel error "{out_}")
-asf 文件名后缀, --api-suffix 文件名后缀
(实验性)这个参数会取代默认的给API使用的音频文件后缀。(默认参数为.flac)
-asr 采样率, --api-sample-rate 采样率
(实验性)这个参数会取代默认的给API使用的音频采样率(赫兹)。(参数个数为1)(默认参数为44100)
-aac 声道数, --api-audio-channel 声道数
(实验性)这个参数会取代默认的给API使用的音频声道数量。(参数个数为1)(默认参数为1)
Auditok的选项:
不使用外部语音区域控制时,用于控制Auditok的选项。
-et 能量(相对值), --energy-threshold 能量(相对值)
用于检测是否是语音区域的能量水平。参考:https://auditok.readthedocs.io/en/
latest/apitutorial.html#examples-using-real-audio-
data(参数个数为1)(默认参数为50)
-mnrs 秒, --min-region-size 秒
最小语音区域大小。同样的参考文档如上。(参数个数为1)(默认参数为0.5)
-mxrs 秒, --max-region-size 秒
最大音频区域大小。同样的参考文档如上。(参数个数为1)(默认参数为10.0)
-mxcs 秒, --max-continuous-silence 秒
在一段有效的音频活动区域中可以容忍的最大(连续)安静区域。同样的参考文档如上。(参数个数为1)(默认 参数为0
.2)
-nsml, --not-strict-min-length
如果不输入这个选项,它会严格控制所有语音区域的最小大小。参考:https://auditok.readthe
docs.io/en/latest/core.html#class-summary(参数个数为0)
-dts, --drop-trailing-silence
参考:https://auditok.readthedocs.io/en/latest/core.html#
class-summary(参数个数为0)
-am AUDITOK_MODE, --auditok-mode AUDITOK_MODE
Auditok mode used by "--nsml" and "--dts". If used, it
will override these two options mentioned above. Ref:
https://auditok.readthedocs.io/en/latest/core.html#cla
ss-summary (arg_num = 0)
-aconf [路径], --auditok-config [路径]
Auditok options automatic optimization config.(arg_num
= 0 or 1)
列表选项:
列出所有可选参数。
-lf, --list-formats 列出所有可用的字幕文件格式。如果的你想要的格式不支持,请使用ffmpeg或者SubtitleEdit来对其进
行转换。如果输出格式是"sub"且输入文件是音频无法获取到视频帧率时,你需要提供fps选项指定帧率。(参数个 数为0)
-lsc [语言代码], --list-speech-codes [语言代码]
列出所有推荐的"-S"/"--speech-language"Google Speech-to-Text 语
言代码。如果参数没有给出,列出全部语言代码。默认的“好的匹配”标准是匹配分数超过90分(匹配分数介于0和10
0之间)。参考:https://tools.ietf.org/html/bcp47 https://gith
ub.com/LuminosoInsight/langcodes/blob/master/langcodes
/__init__.py 语言代码范例:语言文字种类-(扩展语言文字种类)-变体(或方言)-使用区域-
变体(或方言)-扩展-私有(https://www.zhihu.com/question/21980689/
answer/93615123)(参数个数为0或1)
-ltc [语言代码], --list-translation-codes [语言代码]
列出所有可用的"-SRC"/"--src-language"也就是py-googletrans可用的翻译用的
语言代码。否则会给出一个“好的匹配”的清单。同样的参考文档如上。(参数个数为0或1)
-dsl 路径, --detect-sub-language 路径
使用py-googletrans去检测一个字幕文件的第一行的语言。并列出一个和该语言匹配的推荐Google
Speech-to-Text语言代码清单("-S"/"--speech-
language"选项所用到的)。参考:https://cloud.google.com/speech-
to-text/docs/languages(参数个数为1)(默认参数 None)
文章来源:https://blog.csdn.net/weixin_44597347/article/details/135341188
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 算法通关村第十二关-字符串基础题目
- MOSFET管GS电阻的作用-MOS管启动过程详细分析
- 代码随想录刷题第十天
- Java的线程组
- 数据结构与算法教程,数据结构C语言版教程!(第五部分、数组和广义表详解)一
- netty: Marshalling序列化示例
- Mysql 索引 、事务、隔离级别
- 【Databend】多表联结,你不会还没有掌握吧!
- 第 7 章 排序算法
- 西南科技大学数字电子技术实验五(用计数器设计简单秒表)FPGA部分