pytorch集智-1安装与简单使用
1 安装
1.1 简介
pytorch可用gpu加速,也可以不加速。gpu加速是通过cuda来实现,cuda是nvidia推出的一款运算平台,它可以利用gpu提升运算性能。
所以如果要装带加速的pytorch,需要先装cuda,再装pytorch,如果不需用加速,即默认用cpu计算,可不用装cuda
装cuda需要电脑有nvidia的显卡,如果你的网卡是amd,那么抱歉,windows上装不了加速的pytorch,因为cuda不支持amd,pytorch也不支持amd。不过可以装没加速的pytorch,因为官网写了,pytorch不支持amd,但linux上pytorch支持amd(ROCm)


1.2 安装
官网上如果能安装,直接拷贝命令安装就行。我的环境是windows下conda环境,官网那个页面就可以选stable(稳定版),windows,conda,python,cpu,然后拷贝下面'run this command'处的命令去安装
注意
1 当时安装时下载包超时一直报错,可以去国内镜像下载对应的版本包,然后conda install --offline package_name离线安装
2 原理与简单使用
2.1 常规命令
x = torch.rand(5, 3) # 5行3列的值在0-1范围内矩阵
y = torch.randn(5, 3) # 5行3列满足均值0方差1正态分布的矩阵
z = torch.ones(2, 5, 3)
x.mm(y.t()) # x和y矩阵乘法
x.mm(y.T) # 同上,写法不同
x * y # # x和y数乘,需满足x和y矩阵形状相同
# pytorch和numpy转换
x = torch.randn(2, 3)
y = np.random.rand(2, 3)
x_np = x.numpy()
y_torch = torch.from_numpy(y)
# 使用gpu张量运算
if torch.cuda.is_available(): # 判断torch是否可cuda加速
x = x.cuda()
y = y.cuda()
print(x + y)
# 使用cpu张量运算(把x.cuda()换成x.cpu()即可)
x.cpu()
...
2.2 动态计算图
可为神经网络提供统一的反向传播算法方案,可以使人专注于神经网络设计。通过动态计算图,在神经网络运算完成后,可以让反向传播算法自动运行。好处是不用手动设计反向传播算法,动态计算图弄成了自动
计算图的解决思路是将正向计算过程记录下来,只要计算过程可微分,就可以对计算过程求导算梯度
计算图有静态的和动态的,pytorch即支持动态也可以静态
2.3 自动微分变量
pytorch通过自动微分变量实现动态计算图,自动微分变量比一般张量结构更复杂
如何反向传播:计算图弄好后,直接调用.backward()即可获取每个计算过程梯度,并存储在自动微分变量结构体中
自动微分变量有三个重要属性data, grad, grad_fn
data存储自动微分变量的值
grad存储自动微分变量的梯度
grad_fn就是计算图中每个箭头和其方向,这样就可以通过grad_fn回溯计算图。调backward后,会将每个变量的梯度保存到变量的grad属性中
创自动微分变量时,通过传入关键字requires_grad为True实现
x = torch.ones(2, 2, requires_grad=True)pytorch 0.4版本以后,自动微分变量和一般张量合并了,即可以不用显式传入requires_grad获取的张量也是自动微分变量
backward方法只能对计算图的叶节点调用,如果非叶节点调用会得到None
3 实例
from matplotlib import pyplot as plot
import torch
from sklearn.model_selection import train_test_split
class Sample():
def exec(self):
self.prepare_data()
self.train()
self.predict()
self.plot()
def prepare_data(self):
self.x = torch.linspace(1, 100, 100).type(torch.FloatTensor)
rand = torch.randn(100) * 10
self.y = self.x + rand
#self.data = train_test_split(self.x, self.y)
self.data = self.x[:-10], self.x[-10:], self.y[:-10], self.y[-10:]
self.a = torch.rand(1, requires_grad=True)
self.b = torch.rand(1, requires_grad=True)
self.learning_rate = 0.0001
def train(self):
for i in range(2000):
prediction = self.a.expand_as(self.data[0]) * self.data[0] + self.b.expand_as(self.data[0])
loss = torch.mean((prediction - self.data[2]) ** 2)
if i % 200 == 0:
print(f'loss: {loss}')
loss.backward()
self.a.data.add_( - self.learning_rate * self.a.grad.data)
self.b.data.add_( - self.learning_rate * self.b.grad.data)
self.a.grad.data.zero_()
self.b.grad.data.zero_()
def predict(self):
self.pred = self.a.expand_as(self.data[1]) * self.data[1] + self.b.expand_as(self.data[1])
def plot(self):
plot.figure(figsize=(10, 8))
plot.plot(self.data[0].data, self.data[2].data, 'o')
plot.plot(self.data[1].data, self.data[3].data, 's')
plot.plot(self.data[0], self.data[0] * self.a.data + self.b.data)
plot.plot(self.data[1], self.pred.detach().numpy(), 'o')
plot.xlabel('x')
plot.ylabel('y')
plot.show()
def main():
Sample().exec()
pass
if __name__ == '__main__':
main()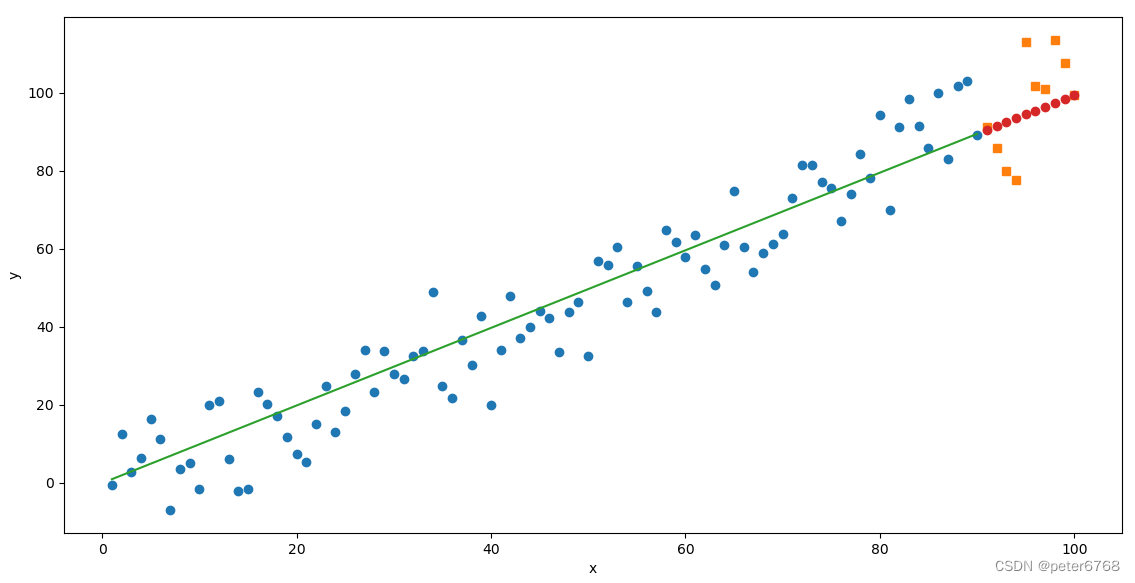
注意
1 self.b.data.add()和self.b.data.add_()区别是带下划线的是自运算,即将运算获得的值赋值给自身
2 对a b调用expand_as是为了扩维至x,因为a,b是数,但x是矩阵
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 编程基础 - 基本语法
- java客户端连接redis并设置序列化处理
- 业务架构中的10大领域
- Python中__getitem__的奇妙应用
- 搭建Python(3.7及以上版本)环境并安装DashScope SDK报错
- 酷开系统 | 重磅!酷开科技荣获第十届广东专利优秀奖!
- 代理IP有何类型区别?如何获取?
- Qt3D QConeMesh圆锥体模型类使用说明,附完整示例代码
- 还在用JS?过来看看GS
- GPT/GPT4科研应用与AI绘图技术及论文高效写作(建议收藏)