小周带你读论文-1之“浪潮Yuan2 有哪些创新“
新开一个系列连载,小周带你读论文,会不定期的更新各种新的,甚至老的有价值的论文,当然您有时间自己读最好了,如果自己读嫌麻烦,可以来看我这个的总结
老规矩,1,2,3 上链接...
IEIT-Yuan/Yuan-2.0: Yuan 2.0 Large Language Model (github.com)
Yuan2是浪潮的刚发布的LLM是基于Yuan1改的(这里吐槽一下浪潮,Yuan1的pretrain数据原来是公开下载的有1T多的语料很大一部分中文比例,现在给关闭了

)
Yuan2这论文写的还是有点意思的,受限于算力要求,很多事实性的实验我没法做证明或者证伪,那就先看看文中的一些理论创新
1- 魔改Transformer(LFA):
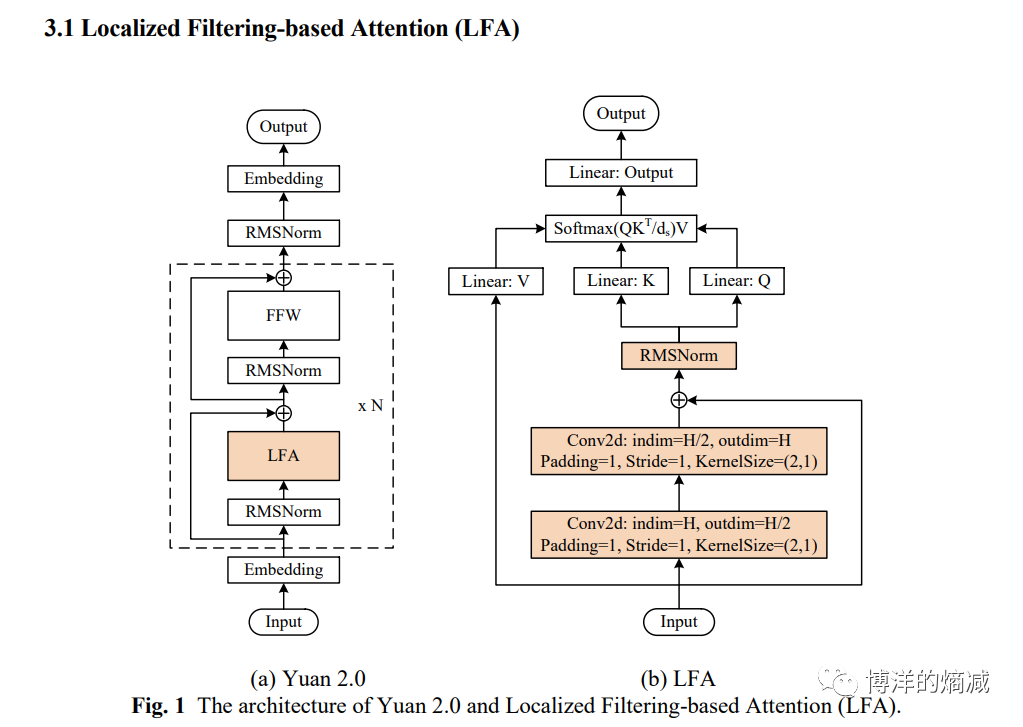
为了好理解我沾个Llama2的结构作为对比
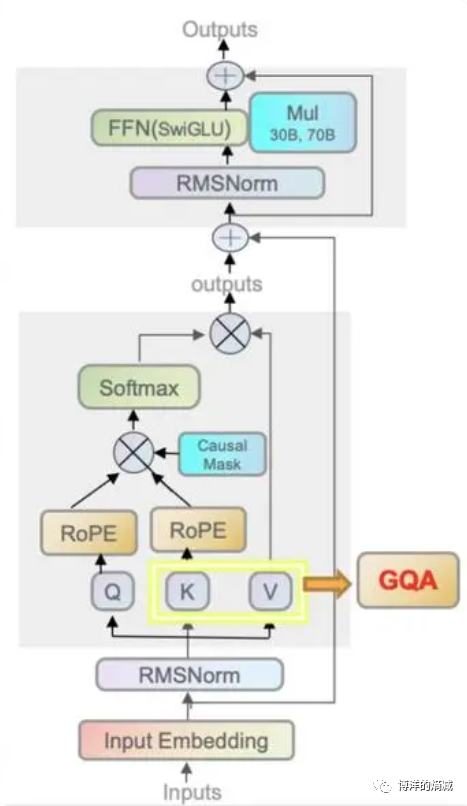
几乎一眼就可以看出来变化,他把multiheader attention层给改了(其实要严格一点说也不算全改,只是前面加东西了)!Transformer玩的啥呢,其实就是玩attetion这层呢,他为什么要把核心内容给改了呢?
下面是论文里给的说法:
Attention, as a basic building block in LLMs, has showed great success across NLP tasks [9,10]. When a sequence is fed in to a language model, attention mechanism learns the weights of each pair of tokens to build the dependencies across the entire input sequence. The mechanism equally treats a token in neighbourhood and that in a distance. However, in natural language, the dependencies of words in neighbourhood are often stronger than the words faraway. The interconnection learned by Attention is global without any prior knowledge of local dep
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Chatgpt【问心一语】线上运营代理火热招募中!
- 安卓手机如何打开ics文件?ics格式文件用什么软件打开?
- MySql -数据库进阶
- 数据结构之预习作业:排序(v1)
- 【?什么是分布式系统的一致性 ?】
- 华为机试真题实战应用【算法代码篇】-字符串比较(附C++和JAVA代码实现)
- Mysql SQL审核平台Yearning本地部署
- python_批量计算指定目录下的数据的固定率和时长
- 在线项目实习|2024寒假项目实战火热报名中!
- jmeter配置使用(mac)