Python能做大项目(8) - Need for Speed! 高效编码之一
1. AI赋能的代码编写
传统上,IDE的重要功能之一,就是代码自动完成、语法高亮、文档提示、错误诊断等等。随着人类进入深度学习时代,AI辅助编码则让程序员如虎添翼。
我们首先介绍几个AI辅助编码的工具,然后再介绍常规的语法高亮、文档提示等功能。
1.1. github copilot
github copilot是github官方出品的AI辅助编码工具。它是基于大规模语料、超大规模的深度学习模型,结合了大量的编程经验,为开发者提供代码补全、代码片段联想、代码推荐等功能。copilot可以根据用户输入的一行注释,自动生成代码片段甚至整个函数,功能十分强大。

比如,我们写一段注释如下:
# create a fibonacci series up to nth term
然后回车,copilot就会写出下面的代码:
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
这个函数还有一个尾递归版本,当然copilot也能提供。一般情况下,copilot能提供10个以内的备选答案。
我们再举一个例子,如果有以下注释:
设置npm中国加速镜像
你会立即得到以下代码:
npm install -g cnpm --registry=https://registry.npm.taobao.org
再也不用记忆这些奇怪的设置了!
我们再试一个例子:
# 读取csv文件,并返回一个数组对象
def read_csv(filename):
with open(filename, 'r') as f:
reader = csv.reader(f)
return list(reader)
# 将数组对象转换为json字符串
def to_json(data):
return json.dumps(data)
# 将json发送到github
def send_json(json_data):
url = 'https://api.github.com/repos/udacity/ud120-projects/issues'
headers = {
'Authorization': '' # 请填写你的token
}
r = requests.post(url, json_data, headers=headers)
def main():
data = read_csv('foo.csv')
json_data = to_json(data)
send_json(json_data)
在上述例子中,我们只写了三行注释,copilot自动帮我们填充了代码。在send_json那个方法里,copilot在headers中提示输入’Authorization’字段,并提示这里要给出token,这个填充很有意思,它因为github这个API正好是通过token认证的。当然,由于信息过少,它给的url几乎肯定是错的,这也在情理之中。
比较有意思的是main函数。我只定义了main()方法的函数头,copilot居然自动完成了所有功能的串联,而且应该说,符合预期。
如果上面的例子过于简单,你可以写一些注释,请求copilot为你抓取加密货币价格,通过正则表达式判断是否是有效的邮箱地址,或者压缩、解压缩文件等等。你会发现,copilot的能力是非常强大的。
copilot的神奇之处,绝不只限于上面的举例。作者在实践中确实体验过它的超常能力,比如在单元测试中,自动生成数据序列,或者在生成的代码中,它的错误处理方案会比你自己能写出来的更细腻,等等。但是,要演示那样复杂的功能,已经超出了一本书所以展现的范围了。
这是一些使用者的感言:

所以,Don’t fly solo!(copilot广告语),如果有可能,当你在代码的世界里遨游时,还是让copilot来伴飞吧。当然,copilot也有其不足,其中最重要的一点是,不能免费使用(学生除外),而且每个月10美金的费用对中国程序员来讲可能并不便宜。不仅如此,目前它只接受信用卡和paypal付款,因此在支付上也不够方便。
1.2. tabnine
另一个选项是tabnine,与copilot一样,它也提供了从自然语言到代码的转换,以及整段函数的生成等功能。一些评论认为,它比copilot多出的一个功能是,它能基于语法规则在一行还未结束时就给出代码提示,而copilot只能在一行结束后给出整段代码,即copilot需要更多的上下文信息。
tabnine与copilot的值得一提的区别是它的付费模式。tabnine提供了基础版和专业版两个版本,而copilot只能付费使用。tabnine的专业版还有一个特色,就是你可以基于自己的代码训练自己的私有AI模型,从而得到更为个性化的代码完成服务。这个功能对于一些大型公司来说,可能是一个很好的选择。它的另一个优势就是,它在训练自己时只使用实行宽松开源许可证模式的代码,因此,你的代码不会因为使用了tabnine生成的代码,就必须开源出去。
GPT code clippy是Github copilot的开源替代品,如果既不能用copilot,也不能使用tabnine,也可以试试这个。不过在我们成文的时候,它还没有提供一个发行版的vscode扩展,只能通过源码安装。
!!!Info
说到AI辅助编码,不能不提到这一行的先驱 - Kite。Kite成立于2014年,致力于AI辅助编程,于2021年11月关闭。由于切入市场过早,kite的技术路线也必然相对落后一些,其AI辅助功能主要是基于关键词联想代码片段的模式。等到2020年github的copilot横空出世时,基于大规模语料、超大规模的深度学习模型被证明才是最有希望的技术路线。而此时kite多年以来的投入和技术积累,不仅不再是有效资产,反而成为了历史包袱。往新的技术路线上的切换的代价往往是巨大的 – 用户体验也难免改变,而且新的模型所需要的钞能力,kite也并不具备。
2021年11月16日,创始人Adam Smith发表了一篇告别演说,对kite为什么没有成功进行了反思,指出尽管Kite每个月有超过50万月活跃用户,但这么多月活跃用户基本不付费,这最终压垮了kite。当然,终端用户其实也没有错,毕竟copilot的付费模式能够行得通。人们不为kite付费,也确实是因为kite还不够好。
属于kite的时代已经过去了,但正如Adam Smith所说,未来是光明的。AI必将引发一场编程革命。kite的试验失败了,但催生这场AI试验的所有人:投资人,开发团队以及最终用户,他们的勇气和贡献都值得被铭记。
作为一个曾经使用过kite,也欠Kite一个会员的使用者,我也在此道声感谢与珍重!
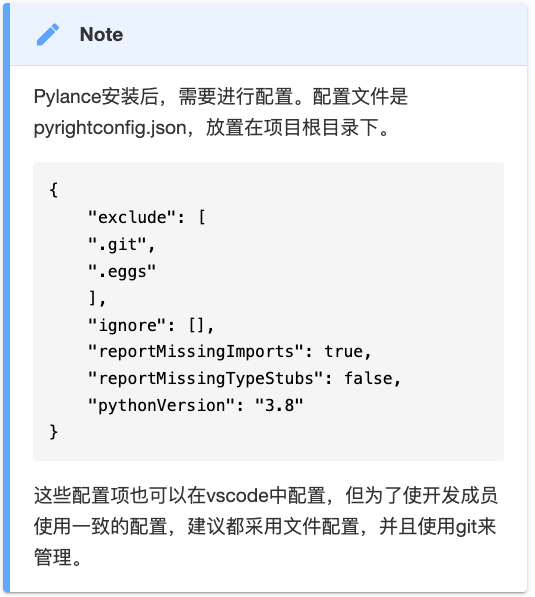
尽管AI辅助编程的功能很好用,但仍然有一些场景,我们需要借助传统的工具,比如pylance。pylance是微软官方出品的扩展。vscode本身只是一个通用的IDE框架,对具体某个语言的开发支持(编辑、语法高亮、语法检查、调试等),都是由该语言的扩展及语言服务器(对python而言,有jedi和pylance两个实现)来实现的,因此,pylance是我们在vscode中开发python项目时,必须安装的一个扩展。
它可以随用户输入时,提示函数的签名、文档和进行参数的类型提示,如下图所示:

Pylance在上面提到的代码自动完成之外,还能实现依赖自动导入。此外,由于它脱胎于语法静态检查器,所以它还能提示代码中的错误并显示,这正是到目前为止,像copilot这样的人工智能还做不太好的地方。源码级的查错,使得我们可以尽早修正这些错误,这也正是静态语言程序员认为Python做不到的地方。

2. Type Hint (Type Annotations)
很多人谈到Python时,会觉得它作为一种动态语言,是没有类型检查能力的。这种说法并不准确,Python是弱类型语言,变量可以改变类型,但在运行时,仍然会有类型检查,类型检查失败,就会抛出TypeError:
下面的例子演示了Python中变量是如何改变类型的,以及类型检查只在运行时进行的这一特点:
>>> one = 1
... if False:
... one + "two" # 这一行不会执行,所以不会抛出TypeError
... else:
... one + 2
...
3
>>> one + "two" # 运行到此处时,将进行类型检查,抛出TypeError
TypeError: unsupported operand type(s) for +: 'int' and 'str'
... one = "one " # 变量可以通过赋值改变类型
... one + "two" # 现在类型检查没有问题
one two
但Python曾经确实缺少静态类型检查的能力,这是Python一直以来为人诟病的地方。毕竟,错误发现的越早,修复成本就越低。但这正在成为历史。
类型注解从python 3.0(2006年,PEP 3107,当时还叫function annotations)时被引入,但它的用法和语义并没有得到清晰定义,也没有引起广泛关注和运用。数年之后,PEP 484(type hints including generics)被提出,定义了如何给python代码加上类型提示,这样,type annotation就成为实现type hint的主要手段。因此,当今天人们提到type annotation和type hint时,两者基本上是同一含义。
PEP 484是类型检查的奠基石。但是,仍然有一些问题没有得到解决,比如如何对变量进行类型注解?比如下面的语法在当时还是不支持的:
class Node:
left: str
2016年8月,PEP 526(syntax for variable annotations)提出,从此,像上文中的注解也是允许的了。

PEP 563 (Postponed Evaluation of Annotations) 解决了循环引用的问题。在这个提案之后,我们可以这样写代码:
from typing import Optional
class Node:
#left: Optional[Node] # 这会引起循环引用
left: Optional["Node"]
right: Optional["Node"]
注意到我们在类型Node还没有完成其定义时,就要使用它(即要使用Node来定义自己的一个成员变量的类型),这将引起循环引用。PEP 563的语法,通过在注释中使用字符串,而不是类型本身,解决了这个问题。
在这几个重要的PEP之后,随着Python 3.7的正式发布,社区也开始围绕Type Hint去构建一套生态体系,一些非常流行的python库开始补齐类型注解,在类型检查工具方面,除了最早的mypy之外,一些大公司也跟进开发,比如微软推出了pyright(现在是pylance的核心)来给vscode提供类型检查功能。google推出了pytype,facebook则推出了pyre。在类型注解的基础上,代码自动完成的功能也因此变得更容易、准确,推断速度也更快了。代码重构也因此变得更加容易。
类型检查功能将对Python的未来发展起到深远的影响,可能足够与typescript对js的影响类比。围绕类型检查,除了上面提到的几个最重要的PEP之外,还有:
- PEP 483(解释了python中类型系统的设计原理,非常值得一读)
- PEP 544 (定义了对结构类型系统的支持)
- PEP 591 (提出了final限定符)
以及PEP 561等另外18个PEP。此外,还有PEP 692等5个PEP目前还未被正式接受。
Python的类型检查可能最早由Jukka Lehtosalo推动,Guido,?ukasz Langa和Ivan Levkivskyi也是最重要的几个贡献者之一。Jukka Lehtosalo出生和成长于芬兰,当他在剑桥大学计算机攻读博士时,在他的博士论文中,他提出了一种名为“类型注解”(Type Annotations)的语法,从而一统静态语言和动态语言。最初的实验是在一种名为Alore的语言上实现的,然后移植到Python上,开发了mypy的最初几个版本。不过很快,他的工作重心就完全转移到Python上面来,毕竟,Python庞大的用户群和开源库才能提供丰富的案例以供实践。
2013年,在圣克拉拉举行的PyCon会议上,他公布了这个项目,并且得到了与Guido交谈的机会。Guido说服他放弃之前的自定义语法,完全遵循Python 3的语法,即PEP 3107提出的函数注解)。在随后他与Guido进行了大量的邮件讨论,并提出了通过注释来对变量进行注解的方案(不过后来的PEP 526提出了更好的方案)。
在Jukka Lehtosalo从剑桥毕业后,受Guido邀请,加入了Dropbox,领导了mypy的开发工作。
这里也可以看出顶尖大学对待学术研究上的开放和不拘一格。大概在2016年前后,我看到斯坦福的网络公开课上还有讲授ios编程的课,当时也是同样的震撼。一是感叹他们选课之新,二是感叹这种应用型的课程,在国内的顶尖大学里,一般是不会开设的,因为大家会觉得顶尖的学术殿堂,不应该有这么“low”的东西。
在有了类型注解之后,现在我们应该这样定义一个函数:
def foo(name: str) -> int:
score = 20
return score
foo(10)
foo函数要求传入字符串,但我们在调用时,错误地传入了一个整数。这在运行时并不会出错,但pylance将会发现这个错误,并且给出警告,当我们把鼠标移动到出错位置,就会出现如下提示:

下面,我们简要地介绍一下type hint的一些常见用法:
# 声明变量的类型
age: int = 1
# 声明变量类型时,并非一定要初始化它
child: bool
# 如果一个变量可以是任何类型,也最好声明它为Any。zen of python: explicit is better than implicit
dummy: Any = 1
dummy = "hello"
# 如果一个变量可以是多种类型,可以使用Union
dx: Union[int, str]
# 从python 3.10起,也可以使用下面的语法
dx: int | str
# 如果一个变量可以为None,可以使用Optional
dy: Optional[int]
# 对python builtin类型,可以直接使用类型的名字,比如int, float, bool, str, bytes等。
x: int = 1
y: float = 1.0
z: bytes = b"test"
# 对collections类型,如果是python 3.9以上类型,仍然直接使用其名字:
h: list[int] = [1]
i: dict[str, int] = {"a": 1}
j: tuple[int, str] = (1, "a")
k: set[int] = {1}
# 注意上面的list[], dict[]这样的表达方式。如果我们使用list(),则这将变成一个函数调用,而不是类型声明。
# 但如果是python 3.8及以下版本,需要使用typing模块中的类型:
from typing import List, Set, Dict, Tuple
h: List[int] = [1]
i: Dict[str, int] = {"a": 1}
j: Tuple[int, str] = (1, "a")
k: Set[int] = {1}
# 如果你要写一些decorator,或者是公共库的作者,则可能会常用到下面这些类型
from typing import Callable, Generator, Coroutine, Awaitable, AsyncIterable, AsyncIterator
def foo(x:int)->str:
return str(x)
# Callable语法中,第一个参数为函数的参数类型,因此它是一个列表,第二个参数为函数的返回值类型
f: Callable[[int], str] = foo
def bar() -> Generator[int, None, str]:
res = yield
while res:
res = yield round(res)
return 'OK'
g: Generator[int, None, str] = bar
# 我们也可以将上述函数返回值仅仅声明为Iterator:
def bar() -> Iterator[str]:
res = yield
while res:
res = yield round(res)
return 'OK'
def op() -> Awaitable[str]:
if cond:
return spam(42)
else:
return asyncio.Future(...)
h: Awaitable[str] = op()
# 上述针对变量的类型定义,也一样可以用在函数的参数及返回值类型声明上,比如:
def stringify(num: int) -> str:
return str(num)
# 如果函数没有返回值,请声明为返回None
def show(value: str) -> None:
print(value)
# 你可以给原有类型起一个别名
Url = str
def retry(url: Url, retry_count: int) ->None:
pass
此外,type hint还支持一些高级用法,比如TypeVar, Generics, Covariance和contravariance等,这些概念在PEP484中有定义,另外,PEP483和understanding typing可以帮助读者更好地理解类型提示,建议感兴趣的读者深入研读。
如果您的代码都做好了type hint,那么IDE基本上能够提供和强类型语言类似的重构能力。需要强调的是,在重构之前,你应该先进行单元测试、代码lint和format,在没有错误之后,再进行重构。如此一来,如果重构之后,单元测试仍然能够通过,则基本表明重构是成功的。
3. PEP8 - python代码风格指南
PEP8是2001年由Guido等人拟定的关于python代码风格的一份提案。PEP8的目的是为了提高python代码的可读性,使得python代码在不同的开发者之间保持一致的风格。PEP8的内容包括:代码布局,命名规范,代码注释,编码规范等。PEP8的内容非常多,在实践中,我们不需要专门去记忆它的规则,只要用对正确的代码格式化工具,最终呈现的代码就一定是符合PEP8标准的。在后面的小节里,我们会介绍这一工具 – black,因此,我们不打算在此处过多着墨。
本文摘录自《Python能做大项目》(暂定名),全书已送审,将由机械工业出版社出版。全文已发表在大富翁官网,您也可以前往提前阅读。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 深度学习记录--RMSprop均方根
- 基于内存的分布式NoSQL数据库Redis(二)数据结构与通用命令
- 性能测试类型-性能测试、负载测试和压力测试的区别
- 建立网络矩阵:选择迅腾文化提供定制集成化服务、专业团队支持与拓展销售渠道
- 海外数据中心代理与住宅代理:优缺点全面对比
- 【Jenkins】Pipeline 简单使用
- C++ 命名空间 namespace详解
- 电脑msvcr120.dll丢失怎样修复,一分钟教会你修复方法
- 用php语言写一个自适应新闻单页面
- STL中set和multiset容器的用法(轻松易懂~)