使用 Java 虚拟线程的结构化并发
Java平台为我们提供了很多启动线程和管理线程的方法。在本文中,我们将介绍 Java 并发编程的一些新方法。我们将介绍结构化并发的概念,然后讨论 Java 21 中的一组预览类 - 这使得将任务拆分为子任务、收集它们的结果并对它们采取行动变得非常容易,而不会无意中留下任何挂起的任务。
结构化并发包括对调试和理解线程之间关系的支持。特别是,结构化并发将所有线程关联到树结构中,作用域位于根。这样一来,查看线程之间的关系就变得很简单,即便使用嵌套作用域也是如此。
标准方法
这种创建线程的方法是最简单的,适用于简单的情况。这是使用 Lambda 表达式启动平台线程的一种方法。
Thread.ofPlatform().start(() -> {
// do something here which runs on
// a separate thread
});
这种方法存在一些大问题。其一,创建平台线程的成本很高。其次,如果应用程序有大量用户 — 平台线程的数量可能会增长到超出 JVM 支持的限制。毫不奇怪,大多数应用程序服务器不鼓励这种行为。那么,让我们继续讨论下一种方法——Java Futures。
Java Future
Java Future 类是在 JDK 5 中引入的,这里我们作为开发人员需要改变我们的思维方式。我们现在不再考虑启动一个新线程,而是考虑提交一个“任务”来执行到线程池。 JDK 5 还引入了 ExecutorService 的概念,这些任务将在其中提交。 ExecutorService 是一个接口,它定义了提交任务并返回 Java Future 的机制。您提交的任务需要实现 Runnable 或 Callable 接口。
这是一个将可调用任务提交到代表单线程线程池的执行器服务的简单示例。
ExecutorService service = Executors.newSingleThreadExecutor();
Future<String> future = service.submit(() -> {
// do some work and return data
return "Done";
});
// do other tasks here
// Block until submitted task completes
String output = future.get();
// prints "Done"
System.out.println(output);
// proceed further
考虑 Java Future 的一个好方法是将其视为对正在某个线程池中执行的已提交任务的引用。使用此 Future 引用,您可以使用 get() 方法等待结果或取消任务。我们在上面的示例中看到,调用 future.get() 返回已提交任务的输出。
现在让我们举一个将多个任务提交给执行器服务的示例。这是它的工作原理。
try (ExecutorService service = Executors.newFixedThreadPool(3)) {
Future<TaskResult> future1 = service.submit(() -> {
// execute task 1 and return TaskResult
});
Future<TaskResult> future2 = service.submit(() -> {
// execute task 2 and return TaskResult
});
Future<TaskResult> future3 = service.submit(() -> {
// execute task 3 and return TaskResult
});
/* All exceptions are filtered up */
// get() will block till task1 completes
TaskResult result1 = future1.get();
// get() will block till task2 completes
TaskResult result2 = future2.get();
// get() will block till task3 completes
TaskResult result3 = future3.get();
// Handle result1, result2, result3
handleResults(result1, result2, result3);
}
在上面的示例中,我们创建了一个新的 ExecutorService,它在大小为 3 的固定线程池上执行三个任务。每次提交任务时,都会返回一个 future 引用。提交三个任务将返回 future1、future2 和 future3。请注意,所有这些任务将并行运行,然后父线程可以使用 future.get() 方法检索每个任务的结果。
实施方面的问题
如果上面的代码中使用了平台线程,那么这段代码就有问题。用于检索 TaskResult 的 get() 方法将阻塞线程,并且由于与阻塞平台线程相关的可伸缩性问题,这可能会调用很昂贵。但是,在 Java 21 中,如果您使用虚拟线程,则不存在阻塞问题,因为在 get() 期间,底层平台线程被释放。
有关虚拟线程及其影响的更多详细信息,您可以阅读我的以下文章
Java Virtual Threads and Enterprise Scalability
Reactive Programming in Java — Good Time to Die
此外,如果任务 2 和任务 3 恰好在任务 1 之前完成执行,那么我们必须等到任务 1 完成后再处理任务 2 和任务 3 的结果。当任务 2 或任务 3 失败时,问题会更严重。假设如果任何任务失败,整个用例就会失败,代码必须等到任务 1 完成才能抛出异常。这并不理想,会给最终用户带来非常缓慢的体验。
上述实现的根本问题是,ExecutorService 类不知道提交给它的各个任务之间的关系。因此,它不知道如果其中一项任务失败会发生什么。换句话说,示例中提交的三个任务不被视为用例的一部分,而是被视为独立的任务。这不是 ExecutorService 类的失败,因为它不是设计来处理已提交任务之间的任何关系的。
然而你会注意到另一个问题。我们在 ExecutorService 的使用周围使用了 try-with-resources 块。这可以确保在 try 块退出时调用 ExecutorService close 方法。 close 方法确保提交给执行程序服务的所有任务都将在继续处理之前终止。如果我们的用例要求当任何一项任务失败时它应该立即失败,那么我们就不走运了。 close 方法将等待所有提交的任务完成。但是,如果我们不使用 try-with-resources 块,那么我们不能保证所有三个任务在该块退出之前结束。仍将存在未完全终止的失控线程。任何其他自定义实现都必须确保在一个任务失败时立即取消其他任务。
因此,尽管在处理可拆分为子任务的任务时使用 Java Future 是一个很好的改进,但它还远远不够。开发人员必须将用例的“意识”编码到逻辑中,而这很难做到。但请注意,平台线程存在的 Java Future 问题之一——即阻塞问题——在虚拟线程中并不存在。如前所述,当使用虚拟线程时,使用 future.get() 方法阻塞线程将简单地释放底层平台线程。这是一件好事。
阻塞问题也可以通过使用 CompletableFuture Pipelines 来解决,但我们不打算讨论这个问题。我们有一个更简单的方法来解决 Java 21 的阻塞问题;我们可以使用虚拟线程。然而,我们需要找到一个更好的解决方案来处理可以拆分为多个子任务并且“了解”用例的任务。这给我们带来了结构化并发的基本思想。
Structured Concurrency
想象一下从方法内提交给 ExecutorService 的任务并且该方法退出。现在更难以推理我们的代码,因为我们不知道提交的任务何时可能产生副作用,这可能会产生难以调试的问题。问题如下图所示
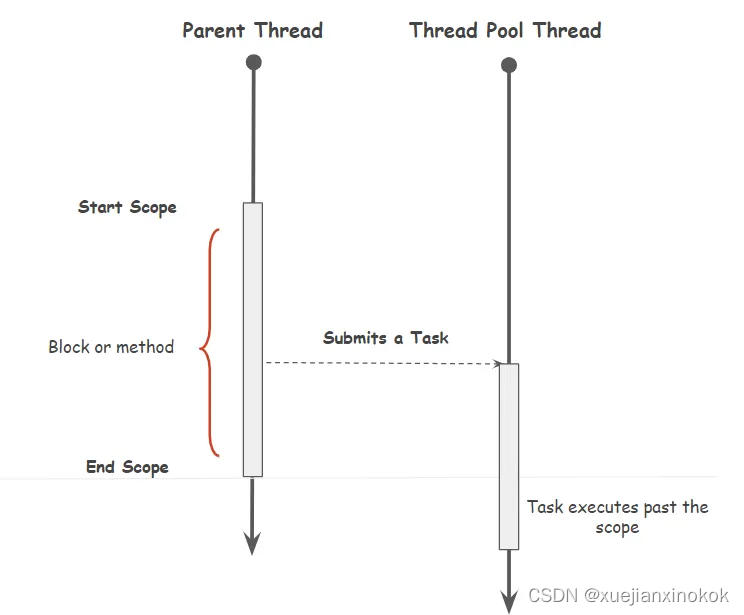
结构化并发的基本思想是,从代码块(方法或块)内启动的所有任务都应在块结束之前终止。换句话说,代码(块)的结构边界和该块内提交的任务的运行时边界是一致的。这使得应用程序代码更容易理解,因为块内提交的所有任务的执行效果都被限制在该块内。当查看块外的一段代码时,我们不必担心任务是否仍在运行。
ExecutorService 的 try-with-resources 块是结构化并发的一个很好的首次尝试,其中从块内提交的所有任务在块退出时完成。但这还不够,因为它可能导致父线程等待超过必要时间的情况。让我们看看下一个改进——StructuredTaskScope。
StructuredTaskScope
在 Java 21 中,引入了虚拟线程作为一项功能,该功能实际上消除了大多数情况下的阻塞问题。但即使使用虚拟线程和Futures,“任务终止不干净”和“等待超过必要时间”的问题仍然存在。 Java 21 中提供了 StructuredTaskScope 类作为预览功能来解决此问题。它试图提供比使用执行器服务的 try-with-resources 块更清晰的结构化并发模型。 StructuredTaskScope 类了解提交的任务之间的关系,因此可以对它们做出智能假设。
下面是一个使用 StructuredTaskScope 的示例,该示例用于用例在发生任何故障时需要立即返回的场景。 StructuredTaskScope.ShutdownOnFailure() 返回对 StructuredTaskScope 的引用,它知道如果一个任务失败,则其他任务也必须终止(它“了解”已提交任务之间的关系)。
try(var scope = new StructuredTaskScope.ShutdownOnFailure()) {
// Imagine LongRunningTask implements Supplier
var dataTask = new LongRunningTask("dataTask", ...);
var restTask = new LongRunningTask("restTask", ...);
// Start running the tasks in parallel
Subtask<TaskResponse> dataSubTask = scope.fork(dataTask);
Subtask<TaskResponse> restSubTask = scope.fork(restTask);
// Wait till all tasks succeed or first Child Task fails.
// Send cancellation to all other Child Tasks if one fails
scope.join();
scope.throwIfFailed();
// Handle Success Child Task Results
System.out.println(dataSubTask.get());
System.out.println(restSubTask.get());
}
想象一个典型的企业用例,其中两个任务可以并行运行——一个数据库任务和一个 Rest API 任务。这个想法是同时运行这些任务,然后将结果合并到一个对象中并返回它。
我们通过调用静态方法 ShutdownOnFailure() 创建一个 StructuredTaskScope 类。然后,我们使用 StructuredTaskScope 对象的 fork 方法(将 fork 方法视为提交方法)来并行运行两个任务。在底层,StructuredTaskScope 类默认使用虚拟线程来运行任务。每次任务被分叉时,都会创建一个新的虚拟线程(虚拟线程永远不会被池化)并运行该任务。
然后,我们在作用域上调用 join 方法,等待两项任务完成或其中一项任务失败。但更重要的是,如果一个任务失败, join() 方法将自动向另一个任务(剩余正在运行的任务)发送取消请求,并等待它终止。这很重要,因为取消请求将确保块退出时没有不必要的挂起任务。
如果其他线程向父线程本身发送取消请求,会发生什么情况。在这种情况下,取消请求也将被发送到子线程。最后,如果块内任何地方出现异常,StructuredTaskScope 的 close 方法将确保取消请求发送到子任务并终止任务。 StructuredTaskScope 实现的美妙之处在于,如果子线程创建它自己的 StructuredTaskScope(子任务本身具有子任务),那么它们都会在取消期间得到干净的处理。
需要注意的是,开发人员的一项责任是确保他们编写的任务必须处理取消期间在线程上设置的中断标志。任务的责任是读取此中断标志并干净地终止自身。如果任务没有正确处理中断标志,那么用例的响应能力将会受到影响。
使用 StructuredTaskScope
当用例要求将任务划分为子任务并且可能将子任务进一步划分为更多子任务时,那么使用 StructuredTaskScope 是合适的。我们在本文中看到的示例是用例需要在任何子失败时返回的情况。但 StructuredTaskScope 也可以处理其他用例。
- 返回第一个成功任务
- 当所有任务完成时返回(成功或失败)
- 推出您自己的 StructuredTaskScope 版本
StructuredTaskScope 有以下几个优点
- 易于阅读代码,因为无论哪种用例,代码看起来都是一样的
- 如果在适当的时间发生故障,子线程将被干净地终止。不会产生悬挂线程。
- 将 StructuredTaskScope 与虚拟线程结合使用意味着不存在与阻塞相关的可扩展性问题。难怪默认情况下,StructuredTaskScope 在幕后使用虚拟线程。
概括
总之,StructuredTaskScope 类是 Java 中一个很好的补充,可以处理将任务拆分为多个子任务的用例。子线程的自动取消、不同用例编码的一致性以及更好地理解代码的能力——使其成为在 Java 中实现结构化并发的理想选择。
虚拟线程和 StructuredTaskScope 类完美结合。虚拟线程使我们能够在 JVM 中创建数十万个线程,而 StructuredTaskScope 类使我们能够有效地管理它们。
相关文章:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 嵌入式Linux之Ubuntu学习笔记(文件系统结构)
- 【书生·浦语】大模型实战营——LMDeploy 大模型量化部署实战
- 重生奇迹MU中需要组队的地方
- 面试-旋转数组的三种方法
- 洛谷P2141 [NOIP2014 普及组] 珠心算测验(C语言)
- Redis面试题9
- 重装系统必看!分区方式MBR与GUID的区别
- 【openGauss/MogDB使用mog_xlogdump解析 xlog文件内容】
- 可视化远程监控EasyCVR及AI识别技术在种植养殖基地/果园场景中的应用建设
- This request has been blocked; the content must be served over HTTPS.