python中selenium库的基本使用详解
什么是selenium
selenium 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid)。
Selenium的核心Selenium Core基于JsUnit,完全由JavaScript编写,因此可以用于任何支持JavaScript的浏览器上。
selenium可以模拟真实浏览器,自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题。
这里要说一下比较重要的PhantomJS,PhantomJS是一个而基于WebKit的服务端JavaScript API,支持Web而不需要浏览器支持,其快速、原生支持各种Web标准:Dom处理,CSS选择器,JSON等等。PhantomJS可以用用于页面自动化、网络监测、网页截屏,以及无界面测试
selenium的基本用法
声明浏览器对象
上面我们知道了selenium支持很多的浏览器:
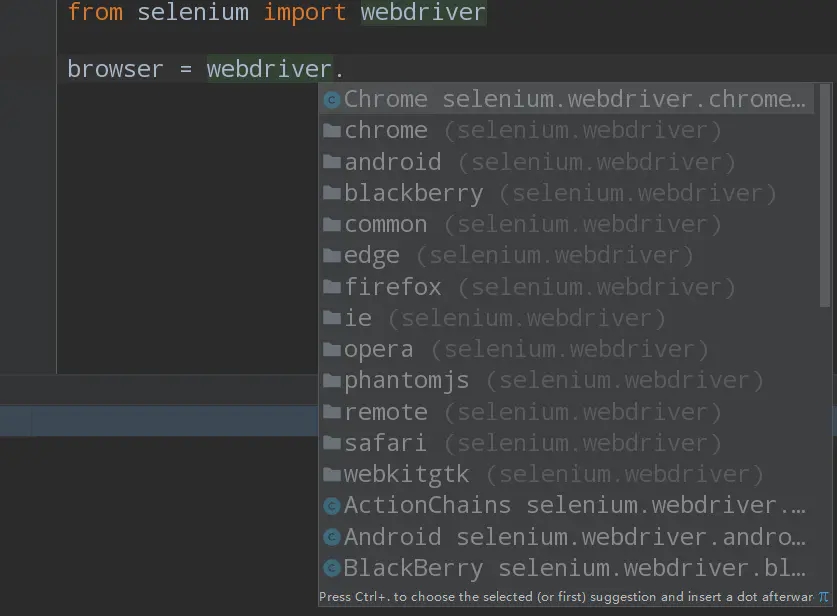
但是如果想要声明并调用浏览器则需要:
| 1 2 3 4 |
|
这里只写了两个例子,当然了其他的支持的浏览器都可以通过这种方式调用
访问页面
| 1 2 3 4 5 6 |
|
上述代码运行后,会自动打开Chrome浏览器,并登陆百度打印百度首页的源代码,然后关闭浏览器
查找元素
单个元素查找
| 1 2 3 4 5 6 7 8 |
|
这里我们通过2种不同的方式去获取响应的元素,第一种是通过id的方式,第二个中是CSS选择器,结果都是相同的。
输出如下:
| 1 2 |
|
这里列举一下常用的查找元素方法:
- find_element_by_name
- find_element_by_id
- find_element_by_xpath
- find_element_by_link_text
- find_element_by_partial_link_text
- find_element_by_tag_name
- find_element_by_class_name
- find_element_by_css_selector
下面这种方式是比较通用的一种方式:这里需要记住By模块所以需要导入
| 1 2 3 4 5 6 7 8 9 10 |
|
当然这种方法和上述的方式是通用的,browser.find_element(By.ID,"q")这里By.ID中的ID可以替换为其他几个
我个人比较倾向于css
多个元素查找
其实多个元素和单个元素的区别,举个例子:find_elements,单个元素是find_element,其他使用上没什么区别,通过其中的一个例子演示:
| 1 2 3 4 5 6 7 8 |
|
输出为一个列表形式:
[<selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-1")>, <selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-2")>, <selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-3")>, <selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-4")>, <selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-5")>, <selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-6")>, <selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-7")>, <selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-8")>, <selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-9")>, <selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-10")>, <selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-11")>, <selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-12")>, <selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-13")>, <selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-14")>, <selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-15")>, <selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-16")>]
当然上面的方式也是可以通过导入from selenium.webdriver.common.by import By 这种方式实现
lis = browser.find_elements(By.CSS_SELECTOR,'.service-bd li')
同样的在单个元素中查找的方法在多个元素查找中同样存在:
- find_elements_by_name
- find_elements_by_id
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
元素交互操作
对于获取的元素调用交互方法
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
运行的结果可以看出程序会自动打开Chrome浏览器并打开百度页面输入韩国女团,然后删除,重新输入后背摇,并点击搜索
Selenium所有的api文档:7. WebDriver API — Selenium Python Bindings 2 documentation
交互动作
将动作附加到动作链中串行执行
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
更多操作参考:7. WebDriver API — Selenium Python Bindings 2 documentation
执行JavaScript
这是一个非常有用的方法,这里就可以直接调用js方法来实现一些操作,
下面的例子是通过登录知乎然后通过js翻到页面底部,并弹框提示
| 1 2 3 4 5 |
|

获取元素属性
| 1 2 3 4 5 6 7 8 9 10 11 |
|
输出如下:
<selenium.webdriver.remote.webelement.WebElement (session="b72dbd6906debbca7d0b49ab6e064d92", element="0.511689875475734-1")>
zu-top-link-logo
zh-top-link-logo
获取文本值
text
| 1 2 3 4 5 6 |
|
输出如下:
<selenium.webdriver.remote.webelement.WebElement (session="ce8814d69f8e1291c88ce6f76b6050a2", element="0.9868611170776878-1")>
知乎
获取ID,位置,标签名
id
location
tag_name
size
| 1 2 3 4 5 6 7 8 9 10 |
|
输出如下:
0.022998219885927318-1
{'x': 759, 'y': 7}
button
{'height': 32, 'width': 66}
?现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:485187702【暗号:csdn11】最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走!?希望能帮助到你!【100%无套路免费领取】

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【C++配置yaml】yaml-cpp使用
- Linux Lha命令教程:学习如何管理.lzh文件(附案例详解和注意事项)
- 深入理解 hash 和 history:网页导航的基础(下)
- 通过 DBeaver 连接 CnosDB
- 2024最新FL Studio21.2MAC电脑版中文版下载安装步骤教程
- 鸿蒙原生应用再添新丁!万达 入局鸿蒙
- 基于SpringBoot+vue的学生信息管理系统详细设计
- windows PE文件都包含哪些信息【详细汇总介绍】
- 图像生成之pix2pix
- 设计模式之-策略模式,快速掌握策略模式,通俗易懂的讲解策略模式以及它的使用场景