深度学习进行数据处理(划分测试集和训练集)
发布时间:2024年01月12日
自己进行在深度学习时对数据的处理,希望可以帮助大家
文章目录
前言
在进行图像分类时我们经常得到的数据集各种各样,接下来我教大家如划分测试集和训练集.
一、观察数据格式
我们一般获得的数据在一个文件夹里,文件夹里面又有各种类别的文件夹,每个文件里面有各自类别的图片.比如.
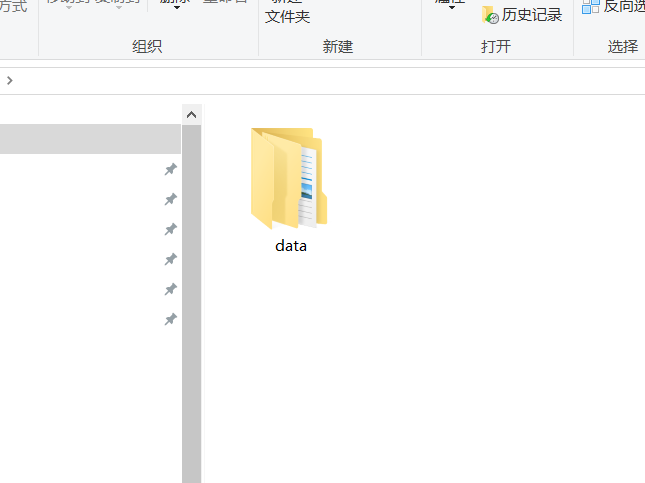
之后我们要想划分就需要知道你的数据集的图片格式是什么?这样才能更好的去认识数据集的情况方便以后操作.
import os
# 定义原始文件夹路径、目标文件夹路径和剩余文件夹路径
source_folder = 'path/to/source/folder'
img_classes = set()#定义一个名字集合
# 遍历原始文件夹中的每个文件夹
for folder_name in os.listdir(source_folder):
if not os.path.isdir(os.path.join(source_folder, folder_name)):
continue
# 获取当前文件夹中所有图片的路径
images = []
for file_name in os.listdir(os.path.join(source_folder, folder_name)):
split_result = file_name.split('.')#使用'.'分隔图片名称
extension = split_result[-1]
img_classes.add(extension)#加入集合
img_classes#返回图片格式像这样的一个集合
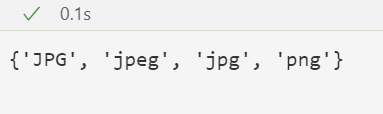
如果你的图片的格式太多建议完全转化一下,尽量不要超过5个,当然全一样的最好,我们这样做是因为在大量数据的时候可能会发生几张图片格式不一致,为了后续操作提供便利.
二、划分训练集和测试集
假设我们现在的要求是将每个分类样本都抽取30张图片放入测试集文件夹,剩余的文件放入训练集的文件夹,并且保持源来的数据集文件夹不变,我们可以用下面代码进行操作.
import os
import random
from PIL import Image
import shutil
# 定义原始文件夹路径、目标文件夹路径和剩余文件夹路径
source_folder = 'path/to/source/folder'#源文件夹
target_folder = 'path/to/target/folder'#测试集文件夹
remaining_folder = 'path/to/remaining/folder'#训练集文件夹
# 遍历原始文件夹中的每个文件夹
for folder_name in os.listdir(source_folder):
if not os.path.isdir(os.path.join(source_folder, folder_name)):
continue
# 创建目标文件夹路径和剩余文件夹路径
target_subfolder = os.path.join(target_folder, folder_name)
os.makedirs(target_subfolder, exist_ok=True)
remaining_subfolder = os.path.join(remaining_folder, folder_name)
os.makedirs(remaining_subfolder, exist_ok=True)
# 获取当前文件夹中所有图片的路径
images = []
for file_name in os.listdir(os.path.join(source_folder, folder_name)):
if file_name.endswith('.JPG') or file_name.endswith('.jpg') or file_name.endswith('.png') or file_name.endswith('.jpeg') :#这里就是你的图片格式
images.append(os.path.join(source_folder, folder_name, file_name))
# 随机选择30张图片
selected_images = random.sample(images, k=30)
# 将选中的图片复制到目标文件夹
for image_path in selected_images:
with Image.open(image_path) as img:
file_name = os.path.basename(image_path)
target_path = os.path.join(target_subfolder, file_name)
shutil.copy(image_path, target_path)
# 将剩余的图片移动到剩余文件夹
remaining_images = list(set(images) - set(selected_images))
for image_path in remaining_images:
file_name = os.path.basename(image_path)
remaining_path = os.path.join(remaining_subfolder, file_name)
shutil.copy(image_path, remaining_path)
这样你就得到了训练集文件夹里面包括各种类别的文件夹并且每个文件夹里面有30张随机抽出的图片了,训练集文件夹则是你抽取后剩余的图片啦!
如果你不保证的话可以测试一下训练集的图片数加测试集的图片书是否等于总的图片数.
你可以这样测试.
import torchvision #这个包学深度学习应该有,没有的话你换一个读取数据也行
data_path1 = 'trainfolder'
train_data = torchvision.datasets.ImageFolder(root=data_path1)
data_path2 = 'resourcefolder'
full_data = torchvision.datasets.ImageFolder(root=data_path2)
data_path3 = 'testfolder'
test_data = torchvision.datasets.ImageFolder(root=data_path3)
print(len(train_data))
print(len(test_data))
print(len(full_data))总结
本节介绍了如何对我们得到的数据文件进行操作,将其分成测试集和训练集两个部分,以便我们后续对数据得操作,之后我会出一期数据增强的操作,我们先将原始数据集划分,而后做数据增强的原因是数据增强后在划分可能会对测试集的污染这样你在训练的时候看起来不错,但在投入实际时却效果不好的原因,马上就会更新,期待各位小伙伴的关注.
文章来源:https://blog.csdn.net/qq_55383558/article/details/135560600
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章