02.构建和使用的大型语言模型(LLMs)阶段
发布时间:2024年01月11日
我们为什么要建立自己的LLMs?LLM从头开始编码是了解其机制和局限性的绝佳练习。此外,它还为我们提供了必要的知识,可以保留或微调现有的开源LLM架构,以适应我们自己的特定领域的数据集或任务。
研究表明,在建模性能方面,定制(LLMs为特定任务或领域量身定制的)可以胜过 ChatGPT LLMs 等通用型,后者专为各种应用而设计。这方面的例子包括 BloombergGPT,它专门用于金融,LLMs专为医学问答量身定制(有关详细信息,请参阅本章末尾的“进一步阅读和参考”部分)。
创建 LLM的一般过程,包括预训练和微调。“预训练”中的术语“预训练”是指在大型、多样化的数据集上训练模型LLM以发展对语言的广泛理解的初始阶段。然后,这个预训练模型作为基础资源,可以通过微调进一步完善,在这个过程中,模型在更特定于特定任务或领域的更窄的数据集上专门训练。图 1.3 描述了由预训练和微调组成的两阶段训练方法。
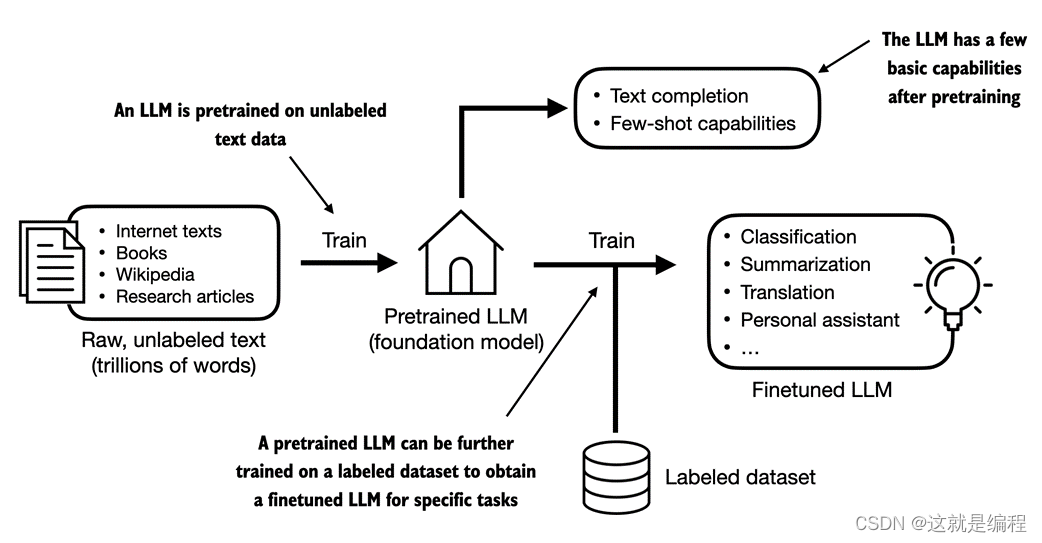
图 1.3 预训练涉及LLM对大型未标记文本语料库(原始文本)的下一个单词预测。然后,可以使用较小的标记数据集对预训练LLM进行微调。
如图 1.3 所示,创建文本的第一步是在大型文本数据语料库(有时称为原始文本LLM)上对其进行训练。在这里,“原始”是指这些数据只是没有任何标签信息的常规文本[1]。(可以应用过滤,例如删除未知语言的格式字符或文档。
文章来源:https://blog.csdn.net/cq20110310/article/details/135503401
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【粉丝福利社】一书读懂物联网:基础知识+运行机制+工程实现(文末送书-进行中)
- ELK日志分析
- 交叉注意力融合时域、频域特征的FFT + CNN -BiLSTM-CrossAttention轴承故障识别模型
- 【NVM】node版本管理插件使用
- 揭开 JavaScript 作用域的神秘面纱(下)
- 数据结构与算法-动态规划-机器人达到指定位置方法数
- “接口”公共规范的遵守者
- MATLAB中uitab函数用法
- locust 快速入门--程序调试
- 深入理解Spark编程中的map方法