清华提出ViLa,揭秘 GPT-4V 在机器人视觉规划中的潜力
人类在面对简洁的语言指令时,可以根据上下文进行一连串的操作。对于“拿一罐可乐”的指令,若可乐近在眼前,下意识的反应会是迅速去拿;而当没看到可乐时,人们会主动去冰箱或储物柜中寻找。这种自适应的能力源于对场景的深刻理解和对广泛常识的运用,使人们能够根据上下文推断和解释指令。

举例来说,对于机器人系统,底层指令可能是精确的关节运动或轮速控制。相比之下,高级语言指令可能是描述一个任务或目标,比如“将蓝色的盘子放在桌子上”。会更接近人类日常语言、易于理解,而不需要详细规定每个具体的动作。因此使用高级语言指令有助于提高系统的可理解性和用户友好性。
当下对于视觉语言模型(VLM)如 GPT-4V 的研究如火如荼,那么如何借助这些模型让机器人更好地理解高级语言指令,对非专业领域的人们更加友好呢?
来自清华的团队提出了一种简单有效的方法——ViLa,利用 GPT-4V 进行机器人长期任务规划的方法,揭示了 GPT-4V 在机器人视觉语言规划中的潜力,改变了机器人理解和与环境互动的方式。我们将深入探讨如何构建机器人智能体,使其能理解并执行类似于人类的复杂任务,并在不同场景中展现出长期任务规划的强大能力。
论文题目:
Look Before You Leap: Unveiling the Power of GPT-4V in Robotic Vision-Language Planning
论文链接:
https://arxiv.org/abs/2311.17842
博客地址:
https://robot-vila.github.io/
在大型语言模型(LLM)为复杂的长期任务生成步骤计划时,存在的关键局限是缺乏世界基础,无法感知和推理机器人及其环境的物理状态。为此,有人提出使用外部的适应性模型,但这些模块总无法传达在复杂环境中重要的任务相关信息,使 LLM 仍像一个盲人,适应性模型充当其向导时:
-
盲人仅依靠他们的想象力和向导有限的叙述来理解世界
-
向导可能无法准确理解盲人的目的
为了解决这一问题,结合视觉和语言进行联合推理显然不可或缺。视觉语言模型(VLM)直接将感知信息融入语言模型的推理过程中,以此为基础,作者提出了 ViLa。
ViLa 通过将视觉信息直接整合到推理和规划过程中,显著提高了在现实世界和模拟环境中解决各种复杂而长期任务的能力。其独特之处在于以零样本方式展示了解决各类真实世界日常操纵任务的能力,能够高效地处理各种开放集指令和对象。ViLa 不仅能够在没有事先学习的情况下执行任务,而且在面对多样化的指令和对象时表现出卓越的适应性。

▲图1 ViLA 可以利用基于视觉世界的丰富常识。需要理解空间布局(第一行)、对象属性(中间行)和具有多模态目标的任务(最后一行)
方法
机器人系统通过获取环境的视觉观察??和高级语言指令??来执行操纵任务。生成一连串文本动作,每个动作??都是一个短期语言指令(例如“拿起蓝色容器”),并指定一个子任务或基本技能。
机器人视觉语言规划(ViLA)算法的核心思想是利用 VLM 的能力,通过联合运用视觉和语言,将复杂的高级任务拆解为更容易执行的低级任务序列,实现在动态环境中的闭环规划。
如算法 1 所描述:

▲算法1
-
输入:?当前环境的视觉观察??和高级语言指令?。
-
使用 VLM 生成规划:?ViLA 通过促使视觉语言模型(VLMs)生成一份步骤规划?。表示了从当前状态到达目标状态所需的一系列步骤。
-
选择第一个步骤作为文本动作:?为了实现闭环执行,从生成的规划中选择第一步,即文本动作?。
-
执行策略:?机器人执行与所选择文本动作相对应的策略?π。
-
更新 VLM 查询:?修改 VLM 查询,将执行的文本动作??加入查询中。
-
循环执行:?重复步骤 2 至步骤 5,直到终止 token。
完整的执行过程形成一个闭环规划,整个过程概览如图 2 所示。
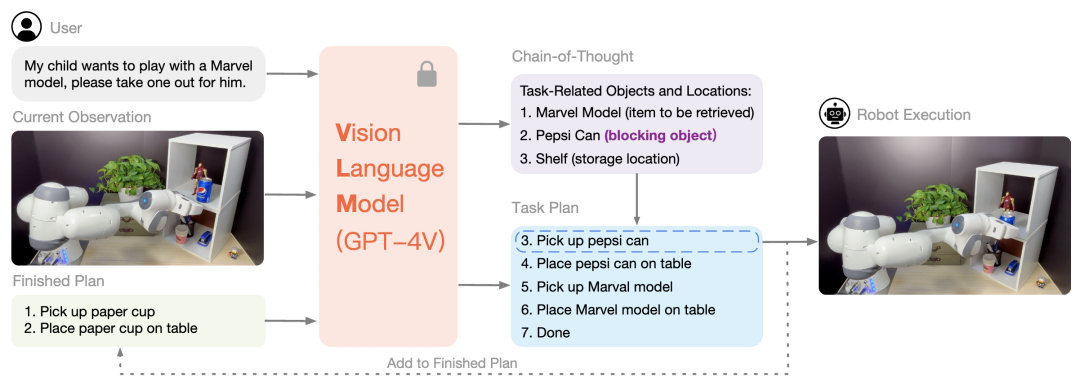
▲图2 ViLA 的概述
ViLA 的优势
-
对视觉常识的理解:?ViLA 通过直接整合图像信息到推理和规划过程中,以零样本方式展现了对复杂的实际世界操纵任务的能力,尤其在空间布局理解和物体属性理解方面具有独特优势。
-
多模态目标说明:?ViLA 在复杂的长期任务中通过视觉观察和语言指令,同时整合目标图像,实现了多模态的目标说明。这使得系统在不同任务和领域中更加灵活和实用。
-
视觉反馈:?ViLA 直接利用视觉反馈,将其融入规划过程,使机器人能更直观地理解环境变化,并在需要时进行实时调整或重新规划。这比将视觉反馈转换为语言的方法更自然和高效。
实验
规划日常操作任务
作者计划用 16 个长期规划的操纵任务来评估 ViLA 在三个领域的性能:
-
对视觉世界常识的理解
-
目标说明的灵活性
-
对视觉反馈的利用
作者严格遵守零示例,在提示中没有包含任何上下文示例,而只使用高级语言说明和机器人需要满足的一些简单约束。
理解视觉常识
如表 1 所示,对需要理解空间布局和物体属性的任务进行规划成功率的比较,ViLA 在 8 项任务中表现出色,能够在推理和规划的过程中融合图像,并深入理解视觉世界中的常识知识。ViLA 的出色表现不仅突显了其通用性,还展现了其作为开放世界任务通用规划器的潜力。
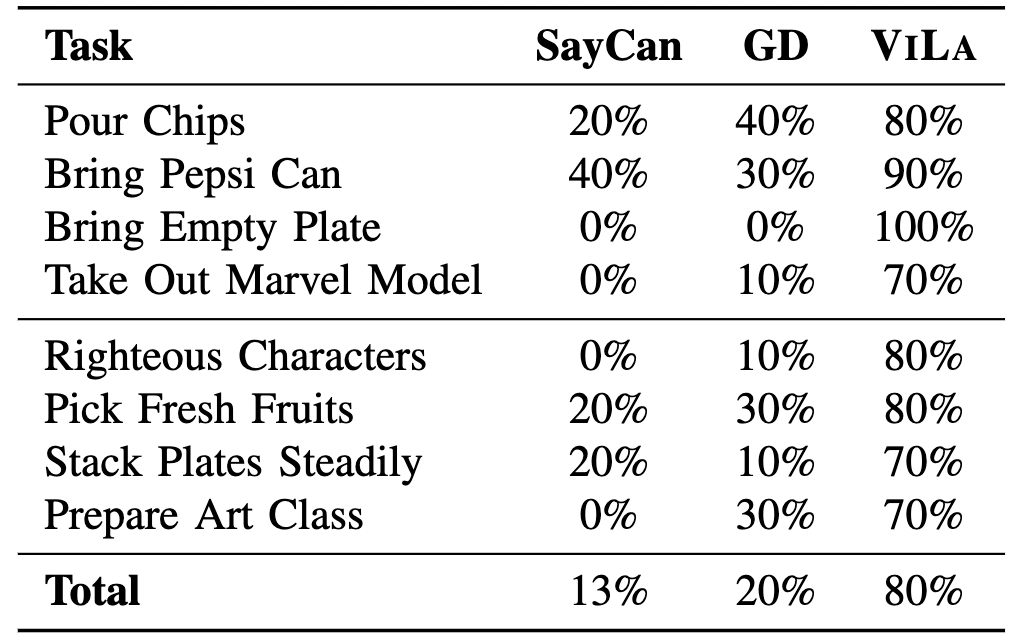
▲表1 需要丰富视觉常识的任务比较
如图 3 的实验所示,在第一个任务中,ViLA 成功识别出在拿起蓝色盘子之前需要将苹果和香蕉从蓝色盘子中移开。相反,SayCan 虽然识别到了物品,但未能理解它们之间的空间关系,试图直接拿起蓝色盘子,这凸显了在视觉推理中理解复杂的几何配置和环境约束的重要性。

▲图3 ViLA(左)和 SayCan (右)的决策过程
在另一个场景中,要为儿童美术课准备安全区域,基于桌子上的剪纸的上下文线索,剪刀应该保留在桌子上,但 SayCan 错误地拿起剪刀并放入盒子中。这显示了全面的视觉理解对于准确评估物体属性的关键性。
在图 4 中,作者进行了一项故障分析,主要关注了不同模型在执行规划任务时产生的错误类型。可以看到,通过利用根植于视觉世界的常识知识,ViLA 显著降低了理解错误。
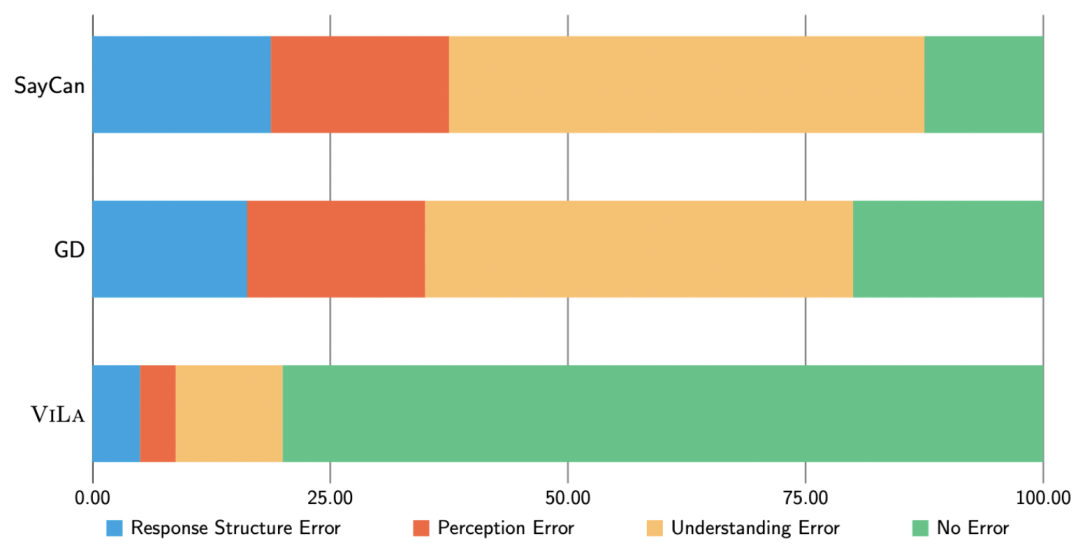
▲图4 ViLA 和 baseline 的错误细分
ViLA 支持灵活的多模态目标说明

▲表2 具有多模态目标的任务中实验结果
在一系列包含不同目标类型的 4 个任务中,实验结果如表 2 所示,ViLA 在所有任务中表现都很好,利用 GPT-4V 中蕴含的大量互联网知识,ViLA 展现了理解各种目标图像的卓越能力。这包括解释丰富儿童绘画以完成拼图、通过参考盘子的照片准备寿司盘(如图 5 顶部所示),甚至准确识别人指示的蔬菜布置(图 5 底部)。此外,作者通过图像和语言说明的组合探索目标说明,凭借其在视觉和语言推理中的双重能力,让 ViLA 获得不错的表现。
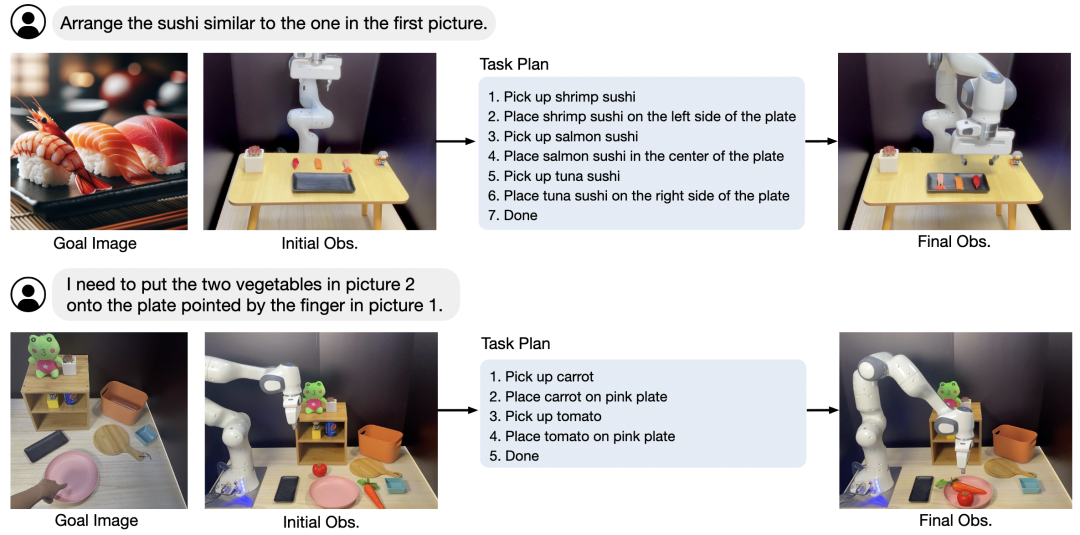
▲图5 ViLA 在基于图像目标的任务上的执行示例
ViLA 可以自然地利用视觉反馈
作者设计了四个需要实时视觉反馈才能成功执行的任务,评估了 ViLA 在仅基于初始观察制定计划的开环(open-loop)变体中的性能。表 3 的结果显示,开环变体在这些需要持续重新规划的动态任务中表现不佳,而通过利用视觉反馈,闭环 ViLA 则明显较优。

▲表3 开环 ViLA 与闭环 ViLA
ViLA 不仅能够有效地从外部干扰中恢复,还能够根据实时视觉反馈调整其策略。比如图 6 的 ViLA 在顶层抽屉找不到订书机时,会继续检查底层抽屉,从而成功找到订书机完成任务。

▲图6 ViLA 在 Find Stapler 任务中的执行示例
模拟桌面重排
在该任务中,机器人或自动化系统需要理解高级语言指令,重新排列桌面上的物体,来实现特定的目标配置或布局。这需要机器人进行视觉感知、语言理解、规划和执行一系列的操纵动作,以实现所要求的桌面布局。
这里有 3 种 baseline:
-
CLIPort:一种语言条件的模仿学习智能体,直接接收高级语言说明而无需规划器。
-
LLM-based Planner:一种基于 LLM 的规划器,不依赖任何将语言或符号与视觉感知或环境特征连接起来的可用性模型。
-
Grounded Decoding(GD):将 LLM 与可用性模型结合,以增强规划能力。
在表 4 的比较中,基于 CLIPort 的方法在面对新颖未见任务的泛化表现有限。尽管 GD 通过外部的可用性模型取得了一定进展,但在各项任务中明显落后于 ViLA,这凸显了在高级机器人规划中整合视觉和语言推理的优势。
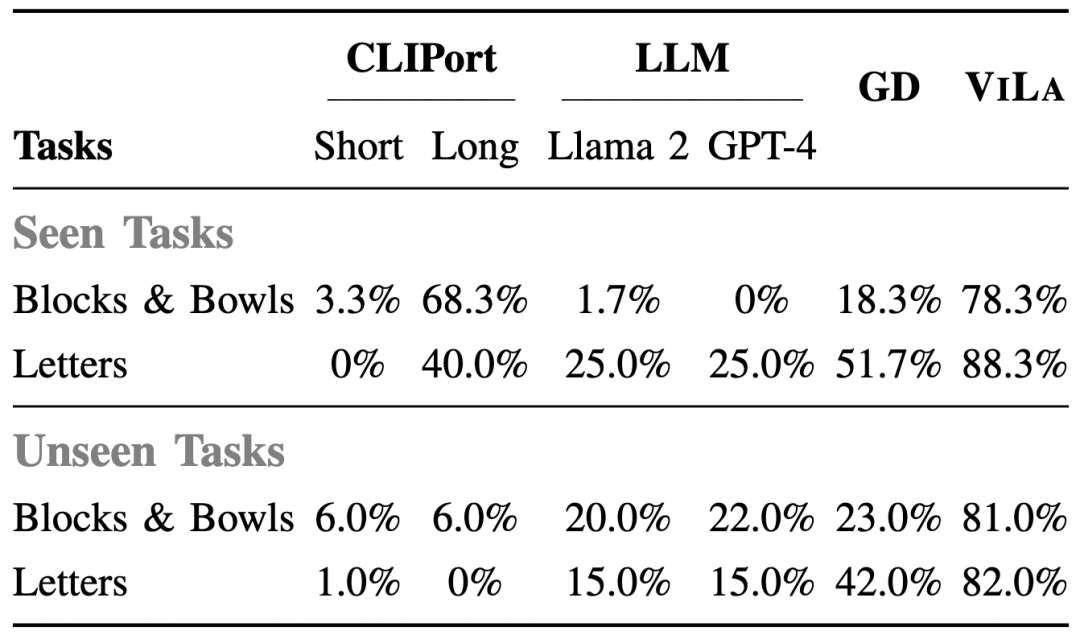
▲表4 在模拟环境中的平均成功率
总结
本文所提出的 ViLa 利用 VLM 将高层语言指令分解为可执行的步骤序列,这不仅是个规划工具,也是机器与人类交互的桥梁,它能够通过视觉和语言的完美协同,理解世界、规划动作,并在动态环境中实现自适应。这种融合视觉和语言的方法,突破了以往规划系统的局限,为机器人在真实世界中执行任务提供了更广阔的可能性。
任何科研探索在诞生之初都会面临挑战和限制,我们期待未来的 ViLa 能努力克服这些挑战,进一步提高其灵活性和智能水平。希望通过不断改进 VLM 的可解释性和输出的一致性,我们能更好地理解 ViLa 的决策过程,并进一步拓展其适用范围。
期待在未来,机器人不只是执行任务的工具,而是真正理解并融入我们生活的智能伙伴。

 ?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!