2023:生成式AI与存储最新发展和趋势分析(下)
上海市计算机学会 存储专委 陈雪菲
上一篇关于生成式AI讨论得比较多,这一篇我们聊聊存储以及存储和AI的碰撞。
1. 存储新发展概述
????????近两年存储领域最大的里程碑事件应该是闪存赢得过半市场,Gartner 连续几个季度的市场分析数据中也多次都确认了这一点,固态存储取代机械硬盘的趋势不可逆转。在这一大背景下,有三个新发展方向日益引起更多关注,分别是存储新介质,可计算存储(存算一体)和进一步的极致性能追求。
2.介质:
????????Intel曾经用傲腾推动了介质层的革命,它在DRAM和SSD之间硬生生开创出SCM/PMem这一新层级,拓展了存储金字塔的层数。性能好延迟低耐擦写非易失,这种新型相变储存器除了贵和容量小几乎没有缺点。但2022年傲腾突然退出市场,形成了事实上的釜底抽薪,许多基于新介质的产品技术研究和生态都被晾在沙滩上。然而经过几年市场培育,需求的幼苗早就破土而出,已经成为一种客观存在,也留下了一个真空地带需要填补。对于产品的呼唤,业界传言了一年多的三星铠侠大普微或是其他厂商,到底谁能真正推出成熟替代来解决供需矛盾,是非常值得关注的。
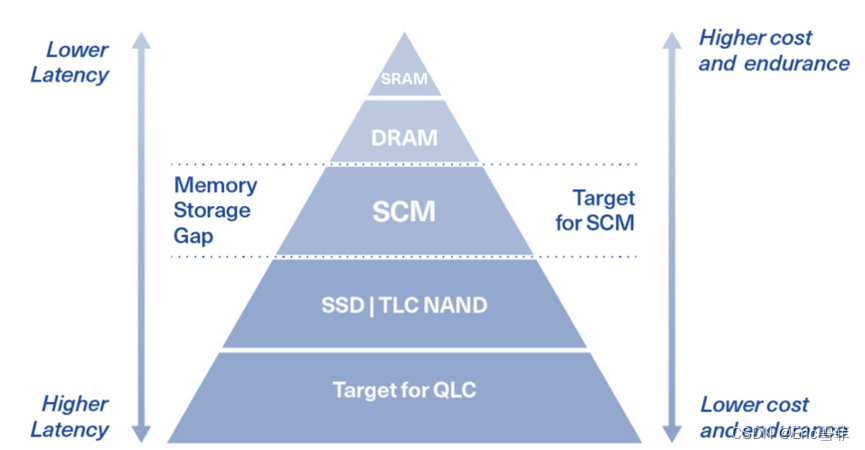
????????在替代产品出现之前,业界有两种思路解决此问题,一是重提NVDIMM(非易失内存模组)的路线,二是回归DRAM+SSD并重新设计软硬件架构,两者都非一蹴而就的简单工作。从硬件上看,NVDIMM-P/NVDIMM-H 都属于SCM,傲腾和NVDIMM-P设计也有相似之处,应该有所参照。但NVDIMM使用了DRAM,导致成本高昂,产品竞争力上有先天短板。其次如果回归DRAM+SSD方案,缓存机制和数据不丢失方案都需要重构,需要承担时间和产品成熟度风险。
3.存算一体
????????严格来说,存算一体技术所依赖的可编程SSD不能归类到介质,但可以认为和介质绑定非常紧密。最近这几年,两种有趣的相反思路都同时存在:首先,存算一体/可计算存储/可编程SSD,都是“ offload”思路:把原本由主机侧负责的部分数据处理的计算负载主动卸载到存储端(包括智能网卡也都是如此),通过在靠近存储介质的地方加个ARM CPU或者干脆是FPGA来提供计算能力,也就是所谓的让计算靠近数据。它能完成的计算包括数据压缩,视频编解码,加解密等等IO密集型应用所需功能,目前在这个方向有很多参与者,是一个热点。
????????另一种思路是把本来紧密集成在SSD介质侧的管控能力提到主机侧来处理,例子就是前两年业界广泛讨论的open channel SSD。原本是固化到FLASH主控芯片的功能,开放接口给主机侧,让主机侧根据自身应用负载特点,通过软件算法调整实现优化。实质上是把存储固件FTL的工作提到上层来完成,这样系统能够了解底层的情况,可以做文件系统软件和介质硬件的协同设计,用各种办法提高性能。这和前一种Offload思路形成了有趣的对照。
4.DNA存储
????????个人兴趣而言,我觉得真正有意思的介质是DNA存储,它属于生物技术与信息技术的跨学科结合,BT+IT。迄今为止,所有的电子信息技术和产业都是基于物理学,能带理论催生了半导体的发现。而DNA的碱基对序列能够储存遗传信息则是生物学的范畴,完全不同的学科。高中生物已经教过DNA的双螺旋结构和ATCG四种嘌呤和嘧啶,用ACTG 分别代表二进制数据00 01 10 11,就能够实现数据的存储,DNA编码合成技术能实现数据写入,而DNA测序技术就能实现数据的读取。

????????DNA存储有几个突出特点,首先是存储密度大,单位体积能够存储的数据量比闪存大三个数量级(1000倍)。MIT的生物工程学教授Mark Bathe有一个著名观点,“The world in a mug”:使用DNA存储技术,一个咖啡杯就可以放得下全世界175ZB的数据。
????????其次是保存时间长和保存成本低,磁盘和闪存的有限保存时间通常是十年或几十年以内,但DNA存储的保存时间至少是百年以上,如果保存得当,千年和万年也是有可能的,毕竟从万年前的琥珀里提取飞虫基因的故事大家也都听过了,更夸张的是Nature上的一篇论文提到能提取冻土中120万年猛犸象的遗传物质并对其DNA进行了解析。
????????但是DNA存储最大的问题是读速度慢和写成本高,合成1MB数据的成本可能超过10万美元;而高速测序技术虽然也叫高速,但和存储行业的高速不可同日而语。
????????DNA存储的整体研究最近两年有些进展,但还未产生重大突破,21年底22年初,微软+华盛顿大学发了新论文,实现并发读写方法;东南大学使用电化学方法加速合成(写)和测序(读);22年9月,天津大学团队用BT+IT的完美结合,解决了常温保存后DNA断裂错误问题。利用生物科学的序列重建算法和信息存储技术的喷泉码(纠删码的一种),事先存储于DNA中的敦煌壁画得到了完美数据恢复。他们之前还利用酵母繁殖实现数据生物复制,非常有意思。
????????另外,国外微软西数牵头的DNA数据存储产业联盟去年发布了白皮书;国内华大基因和中科院深圳先进技术研究院等联合一些单位在22年7月份发布了《DNA存储蓝皮书》也提出组建 DNA数据存储产学联盟。
5.?存储极致高性能
????????极致高性能的获得不是一件容易的事,它关系到整个数据链路的所有环节,介质、接口、协议、各层级的缓存机制设计和彼此配合都有关系,仅在一两个环节做局部升级和优化,有时候并不能获得如预期般的理想结果,性能瓶颈永远是一个狡猾的动态漂移者,需要全局视野和细致实践才能有所掌握。
????????衡量存储性能无非是带宽,IOps和时延,以及性能的稳定输出范围QoS,峰值再高,忽上忽下的性能表现肯定也是无法接受的。
????????从介质上看,Flash,SCM, DRAM都可能出现在数据路径上,搭配相应的缓存机制来提高性能绝对值,从接口上看,过去的PCIe4.0时代,M.2 和U.2使用PCIex4,顺序读带宽可以达到7GBps以上,而4k IOPS可以到100~160万;(另外插卡式的存储直接使用PCIe接口,支持X8和X16,理论带宽能超过20GBp)。现在的PCIe5.0时代,新接口E1.S/E1.L和E3.S/E3.L不仅带来容量的提升,更因为支持PCIe5.0 X8和X16,能够获得翻倍的带宽性能;而未来PCIe6.0到来时,由于通道带宽再次翻倍到128GBps,新接口应该需要更多考虑如何发挥出这一前所未有的通道性能。
????????至于协议方面,NVMe协议已经被广泛采用,NVMe-oF中的NVMe/RDMA(IB)对极致性能的达成有一定研究价值,而RoCE协议可能在时延上有较难克服的问题,更适合向下走性价比方案路线。近期业界真正广泛关注的可能是CXL3.0协议,通过cxl.io cxl.mem cxl.cache三个子协议模块,它实现了主机直接访问外设内存和外设直接访问主机内存的双向访问和系统内存扩展,同时提供了内存级的互联能力。在2023年8月美国闪存峰会(FMS)上,一家韩国厂商利CXL池化内存,展现了3.32倍优于传统RDMA方案的应用性能。在存储极致性能的研究方面,CXL是一个非常值得关注的协议。
????????虽然我们分开讨论了介质,接口,协议的新发展,但要实现存储系统的极致高性能,必须统一起来考虑,摸索高速网络和新介质新协议的协同设计,在每一个具体系统中实现各层级的匹配,才能充分发挥出性能潜力。
6. 分布式在做什么?
????????分布式存储一直是我长期关注和研究的方向,近两年分布式全闪和和全介质覆盖的高端分布式存储呈现出非常明显上升势头,在数据中心级别和高性能计算应用中有很好的表现,高性能海量小文件和混合数据的需求都兼有出现,同时,还看见一些集中式存储的高级功能例如重删也有对应“分布式重删”的实现。一些面向行业如金融的分布式索引和检索的增强特色功能也被引入。
????????今年我还注意到在底层数据的容错技术中,LDPC - 前向纠错码( Error ?Correcting Code)的出现,它原本主要用于通信、视频音频编码中,相比已经熟悉的EC纠删码典型的Reed-Solomon编码,LDPC带来了更好的编解码性能。主要原因是核心编解码算法中采用稀疏编码矩阵,仅使用异或操作,以微小的解码失效可能性换得编解码时间的降低,是一个大胆的技术选择。
????????另外,分布式融合存储的概念也在今年正式推出,也有的厂商叫分布式智能融合存储,“融合”这个词又一次出现在分布式存储产品中。定义上,主要是有三点,介质融合通过预设的可扩展分级存储机制,支持已有和未来各类介质,从HDD到SCM;广泛支持各种存储协议和大数据协议实现存储服务的融合;通过多协议互通技术和数底层据统一管理技术实现数据融合,不同的应用通过不同的协议可以访问同一份数据,真正实现统一资源池。服务融合、数据融合加介质融合形成了分布式融合存储,是一个值得关注的产品理念,里面更多的还是产品化和工程化的挑战。
????????谈完存储,我们再看看AI和存储的碰撞。
7. 大模型的基础设施需求
????????对存储系统来说,生成式AI也是一种应用,那么弄清楚大模型这类应用机制和真正的需求是非常重要的。
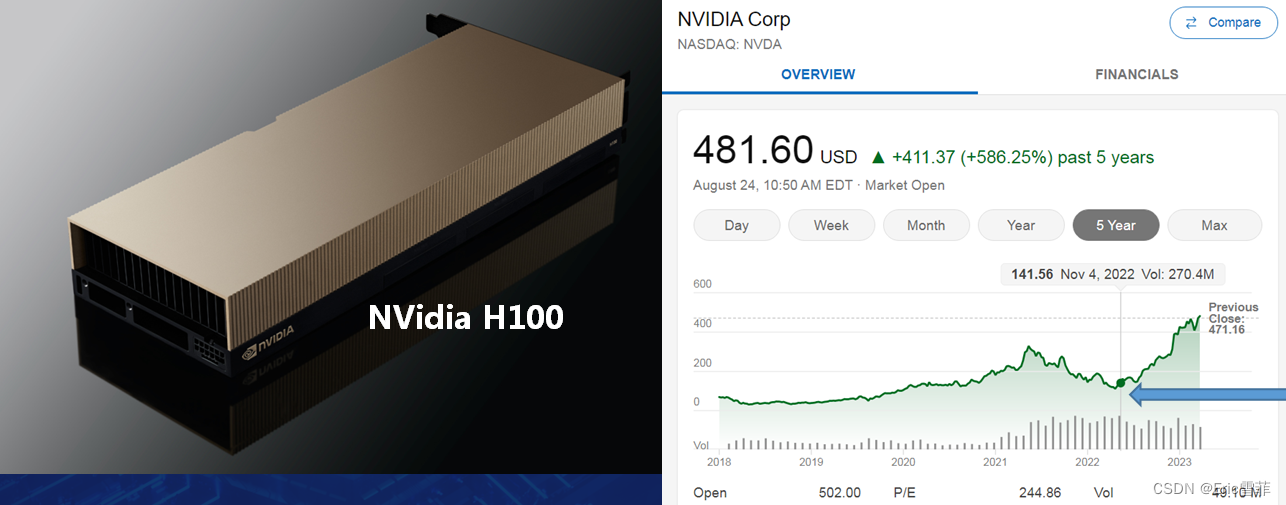
????????目前这个阶段,大模型真正的刚需是什么?毫无疑问,所有的竞争者都在盯一件事,如何能够尽快完成GPU集群的组建部署。如我们在前文所分析,由于产能,政策等原因,NVidia最适合大模型应用的高端产品H100和A100出现了市场短缺和购买困难。AI大模型的算力需求增长达到了每两三个月翻一倍的程度,阿里云的一位架构师给出每两年275倍的估算。面对如此旺盛的需求,NVidia的股价也突破500美元创了新高。除了购买,集群的使用成本也不低,都以小时计;对于如此宝贵的计算资源,尽量提高利用率是第一考虑因素,业界的头部参与者都在算法上想了不少办法,譬如提高计算并行度,避免bubble带来的GPU空转现象等。
????????无米之炊难为,对于大模型来说,算力是第一优先级,其次是超高速网络;因为本质上,当前的生成式AI是一个非常典型的计算密集型应用,这和传统的科学计算及高性能计算(HPC)非常相似。按照之前的HPC经验,搭建这样的IT基础设施,算力和高速网络是最需要解决也最麻烦的问题,我们发现在大模型应用里同样如此,9成的精力和预算都用于解决以上两个问题,上万张H100/A100卡如何用IB网实现高速互联,是非常头疼的问题。
????????同时,由于前文所述的“宽度计算”架构,事实上内存也成为函待解决的高优先级问题。Transform架构的万亿参数,梯度都需要放在最快的介质里,利用HBM(高带宽内存)来构建的缓存(显存)显然是不够的,因此业界对于GPU的带外缓存技术也已经推进一段时间,如果按照速度和时延的优先级排序,缓存->DRAM->NVMe外设来看,AI业界最头部的一批参与者的关注点还集中在前两级,存储的关注优先级明显不太高。
????????最后,即使这一系列基础设施的供应和技术问题都已经解决,找到合适的数据中心资源进行部署也不是太容易的事情,GPU的能耗远大于CPU,例如Dell、H3C的AI服务器都已经采用2400W甚至是3000W的电源,功耗远大于普通服务器,现在市场上大量的IDC还有不少说标准4KW机柜,即使是6KW机柜也很难满足AI基础设施部署的要求,这也是要面对的实际问题。
8. 大模型的数据量和存储需求

????????真实的大模型训练数据量其实并不惊人,从GPT的5GB到GPT3的570GB训练数据,总量都在一个不大的范围。公开资料显示,浪潮的源1.0大模型收集了几乎整个中文互联网的数据集用于训练,总数据量也不过在5TB上下;如果按照7月份GPT-4的最新分析材料透露,使用了13万亿个token进行训练,以每token4字节计算,整个训练数据集也不过是53TB左右。对于如今的存储行业来说,53TB真的不算一个巨大的容量需求,一台高端全闪存储设备通常就可以提供50~100TB的容量空间,混闪和中端存储能够提供的容量就更大,数量级的差别。
????????然而,在开始训练之前,数据集需要经过收集和清洗两个预备动作。

????????以GPT-3为例,训练原始数据来自于网络爬虫工具CommonCrawl所获得的45TB的互联网公开数据,约包含了1万亿Token;当完成了数据清洗工作,数据量缩减了80倍到570GB,而Token数也减少到约40%,4100亿。在这个数据归集和清洗的准备阶段,对于存储容量和并发访问需求还是客观存在的,基本上还是前些年大数据应用和数据湖之类的典型需求。
????????另外,由于直到GPT-4都未能在训练阶段就启用多模态数据集,在生成式AI领域,非结构化数据的爆发式增长还未真正广泛到来,这可能在未来的半年到一年内有巨大的改变。
9. 大模型与存储相关的机制
????????前文我们已经讨论过,大模型应用最主要的是训练和推理两个阶段,进入训练阶段,大模型运作机制里有两个点和存储紧密相关。
????????首先是训练数据集的初次加载。严重膨胀的大模型的训练集群通常规模可观,而神经网络的工作机制要求把所有数据都加载后才能开动,这个过程中数据集有一个类似数据库sharding的动作,对存储产生了大量的并发读写请求,目前大模型对存储主流的访问模式还是通过文件接口协议,经过清洗的数据集里是海量的小文件为主,这种情况下,NAS存储的并发性能包括元数据性能都会遭受考验。
????????第二个机制是训练过程长达数周数月且过程中经常出错,不得以的AI工程师早已经提出了应对方法Checkpoint,这个机制其实是一个被动的应对,假设每隔8小时就可能出一次错,那么就设置6小时为单位的Checkpoint,每隔6小时就把中间状态数据全备份一次,下次错误发生时就回滚到最近的一个checkpoint状态再次开始即可。这个我称之为土法备份,把AI工程师逼的连备份软件都设计得七七八八了。
????????天量参数是大模型的特色,这些中间态数据也非常巨大,假设放回到提供最初训练数据集的集中存储或是分布式存储里,读写过程可能很慢,会像第一次数据加载那样持续十几个小时或者更长时间,这会带来问题:“备份没做完,生产系统崩溃了“。因此,比较土豪的方案是直接在训练集群的节点上插个五六七八块NVME SSD,把Checkpoint的数据直接本地缓存下去就行了。没有了网络和并发IO的种种困扰,“备份”和“恢复”的速度都飞快,就是成本高些。
????????相比训练过程的存储需求,推理阶段的难度基本上可以忽略不计,在推理阶段,由于模型已经完成了训练和微调,大部分的工作负载都是在做计算,或许会获取一些新数据例如来自用户的输入,也会产生推理结果的数据,但是数据量就是一个普通应用的水平,没有不同以往的巨大挑战。
????????还有一些大模型应用希望延续这个持续优化的过程,上线以后,仍然不断根据真实用户反馈再做调优,那也可能涉及到反馈数据的处理和不同阶段数据归档等全生命周期管理的内容,也可能涉及存储需求,但目前还没太多真正接触到,而且从技术上分析都属于常规应用需求,当前各种存储系统是能够轻松应对的。
10. 从存储视角的AI总结
????????无可否认,除了Nvidia这个最大受益者,这一轮生成式AI推动了所有IT产业链的需求增长,大大小小的厂商都在庆贺大模型带来的新订单。按照一位资深行业战略专家的说法,从全球2万亿美金的IT市场规模大盘来看,存储只占个位数的百分比,是其中比较少的部分;从AI应用视角来看,无论是资源紧缺程度,亟待解决的技术紧迫度和预算占比,存储尤其是外部存储现在都不在优先考虑范畴。但对于存储行业来说,虽然只是众多需要支持的应用中的一种,但生成式AI应用的未来增长前景是值得优先关注的。
????????在当前阶段,生成式AI的存储需求首先是高性能低延时,但这个需求并不难满足,按照Nvidia的官方建议性能带宽达到读40GB写20GB即可,它的推荐计算节点配置里,也只有两个40GB的InfiniBand端口,考虑组网冗余,能跑满一个端口带宽即可。如果能够充分发挥闪存的性能,百万级的IOps相信也已经能够满足生成式AI的需求。
????????第二个需求是并发访问能力和数据共享,但也仅在训练数据加载时有强烈需求,另外如果以向量数据库作为数据存储的方案,那么对存储的需求又再简化到了性能可靠性等传统需求。
????????最后是一些待研究探讨的高级功能,例如NVidia CUDA中的GDS支持,可以让GPU跳过CPU直接访问存储,提高性能和响应。另外就是前面讨论过AI工程师们用工程化方法实现的一些存储功能替代,checkpoint等等,是否能够转由存储系统更专业的实现方式,Offload到存储层完成,这都是有意思的研究方向。
????????除外,生成式AI的行业当前还有绝对数据量不大和成本不敏感的特点,综合以上,现在的新NVme SSD和高性能分布式全闪的文件存储两种存储产品是比较适合的,实践中也大多如此。
???? 
????????总的来看,AI应用的特点是发展非常迅速,且时不时就有引爆点,“大模型”方兴未艾,“AI智能体”的新概念业已提上台面,新公司Imbue产品还没有做,已经从NVidia获得两亿美金风投和1万张H100,估值高达10亿美金,革命性的技术迭代一个接一个。2023年,通用大模型的全球化竞争仍然非常激烈,领头羊集团时不时就有开源动作,按照投资行业的观点,每一次都可能会带来重新洗牌。国内垂直行业大模型的百模大战也如火如荼,对相关技术产品方案人才的需求都非常巨大,在终局未了之前,起码会有一个窗口期,值得存储行业好好把握。
(完)
2023.9
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!