单词搜索 II
发布时间:2023年12月18日
题目链接
题目描述
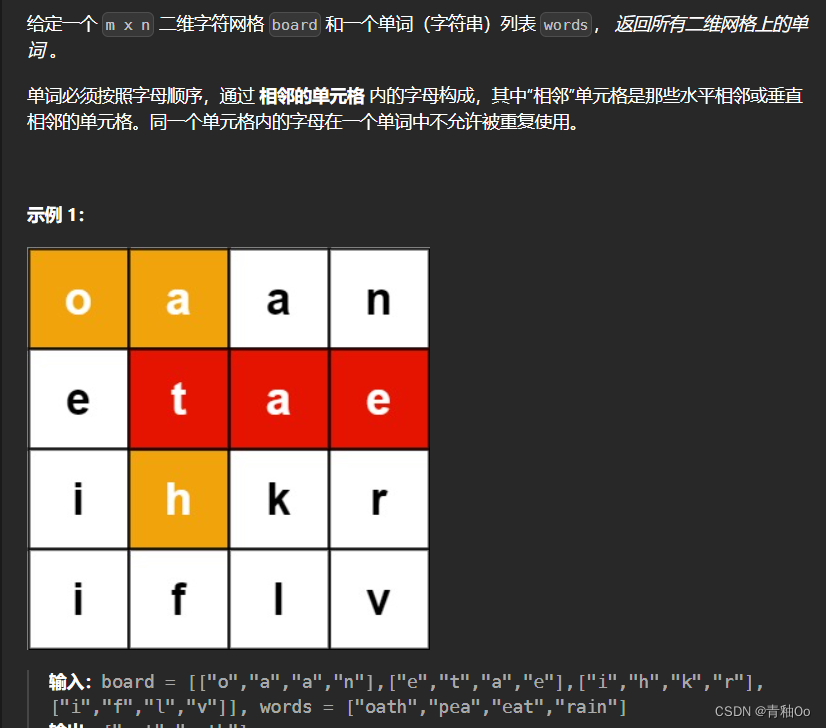

注意点
- board[i][j] 是一个小写英文字母
- words[i] 由小写英文字母组成
- words 中的所有字符串互不相同
- 同一个单元格内的字母在一个单词中不允许被重复使用
解答思路
- 要想找到一个完整的单词,首先想到的是深度优先遍历,如果想要时间复杂度更低,很容易想到剪枝,剪枝的节点在于如果某个字符串在words中没有一个单词的前缀与该字符串重合(注意不是words中不包含该字符串),所以还要用到前缀树的知识,可以参考前缀树,所以本题的主要思路为深度优先遍历+剪枝+前缀树
- 第一步要完成的是前缀树的构建,因为本题中所有单词都是由小写字母组成,所以前缀树的子树可以由大小为26的TrieNode数组构成;第二步是遍历整个board数组,将任意位置作为起点;第三步是从起点开始深度优先遍历,在搜索单词的期间判断其是否在前缀树中,如果不存在则直接剪枝,如果存在则需要判断其是否是单词并重复进行第三步进行深度优先遍历(注意,在此期间,需要对该位置是否遍历进行回溯)
代码
class Solution {
public List<String> findWords(char[][] board, String[] words) {
List<String> res = new ArrayList<>();
int row = board.length;
int col = board[0].length;
// 存储board[i][j]是否已经访问过
boolean[][] visited = new boolean[row][col];
// 构建前缀树
Trie trie = new Trie();
for (String word : words) {
trie.insert(word);
}
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
dfs(board, words, visited, trie.root, res, i, j);
}
}
return res;
}
public void dfs(char[][] board, String[] words, boolean[][] visited, TrieNode trieNode, List<String> res, int i, int j) {
if (i < 0 || i >= board.length || j < 0 || j >= board[0].length) {
return;
}
if (visited[i][j]) {
return;
}
trieNode = trieNode.childTrie[board[i][j] - 'a'];
// 在前缀树中未找到该前缀
if (trieNode == null) {
return;
}
if (trieNode.word != null && !"".equals(trieNode.word)) {
res.add(trieNode.word);
// 该单词已经加入到结果集中,删除防止重复添加
trieNode.word = null;
}
visited[i][j] = true;
// 上下左右四个方向深度搜索单词
dfs(board, words, visited, trieNode, res, i - 1, j);
dfs(board, words, visited, trieNode, res, i + 1, j);
dfs(board, words, visited, trieNode, res, i, j - 1);
dfs(board, words, visited, trieNode, res, i, j + 1);
// 回溯
visited[i][j] = false;
}
}
class TrieNode {
String word;
TrieNode[] childTrie = new TrieNode[26];
}
class Trie {
TrieNode root = new TrieNode();
public void insert(String word) {
TrieNode currTrie = root;
for (char c : word.toCharArray()) {
if (currTrie.childTrie[c - 'a'] == null) {
currTrie.childTrie[c - 'a'] = new TrieNode();
}
currTrie = currTrie.childTrie[c - 'a'];
}
currTrie.word = word;
}
}
关键点
- 前缀树的概念及构建过程
- 深度优先遍历的思想
- 怎样利用前缀树优化对空间的利用及减少遍历次数(前缀树的叶子节点存储整个单词)
- 剪枝节省时间的三个节点:一是board[i]j[]已经遍历过进行剪枝,二是字符串不在前缀树中进行剪枝,三是对已经添加到结果集中的某个单词对应前缀树中存储的该单词信息进行剪枝
文章来源:https://blog.csdn.net/weixin_51628158/article/details/135055691
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- AUTOSAR CanTSyn时间同步模块配置与代码实现(一)
- Linux 内核学习 2 - 用户程序如何被塞进内核进行调度?
- 暂时性死区:JavaScript 中隐藏的陷阱
- 【Verilog】期末复习——设计11011序列检测器电路
- react 6种方式编写样式
- 【MATLAB源码-第103期】基于simulink的OFDM+16QAM系统仿真,输出误码率和星座图。
- Python算法例29 统计比给定整数小的数
- 如何获取一张虚拟银行卡
- 下代 iPhone 反向升级,国产机也要跟着遭殃
- 【C++入门】类和对象(完)