[C#]利用paddleocr进行表格识别
发布时间:2024年01月13日
【官方框架地址】
https://github.com/PaddlePaddle/PaddleOCR.git
【算法介绍】
PaddleOCR表格识别是PaddlePaddle开源项目中的一个强大功能,它利用深度学习技术实现了对各类表格的高精度识别。PaddleOCR表格识别能够处理各种复杂的表格,包括但不限于Excel、CSV和PDF表格,具有广泛的应用场景。
PaddleOCR表格识别的核心是深度学习模型,采用了先进的卷积神经网络和序列模型等技术,能够自动学习和提取表格中的文字、数字和结构信息。通过训练大量的数据集,模型能够逐渐提高识别的准确率和稳定性。
使用PaddleOCR表格识别非常方便,用户只需上传需要识别的表格文件,系统会自动进行预处理和识别,并输出识别的结果。识别的结果可以以文本、数字和结构化的形式展示,方便用户进行后续的数据分析和处理。
此外,PaddleOCR表格识别还支持多种语言和字符集,能够满足不同国家和地区的需求。同时,系统还提供了可定制化的服务,用户可以根据自己的需求进行模型训练和优化,提高识别的准确率和效率。
总的来说,PaddleOCR表格识别是一种高效、准确、易用的表格识别工具,能够帮助用户快速地提取和处理各种表格中的信息。无论是数据分析和可视化领域,还是办公自动化和文档处理领域,PaddleOCR表格识别都具有广泛的应用前景
【效果展示】
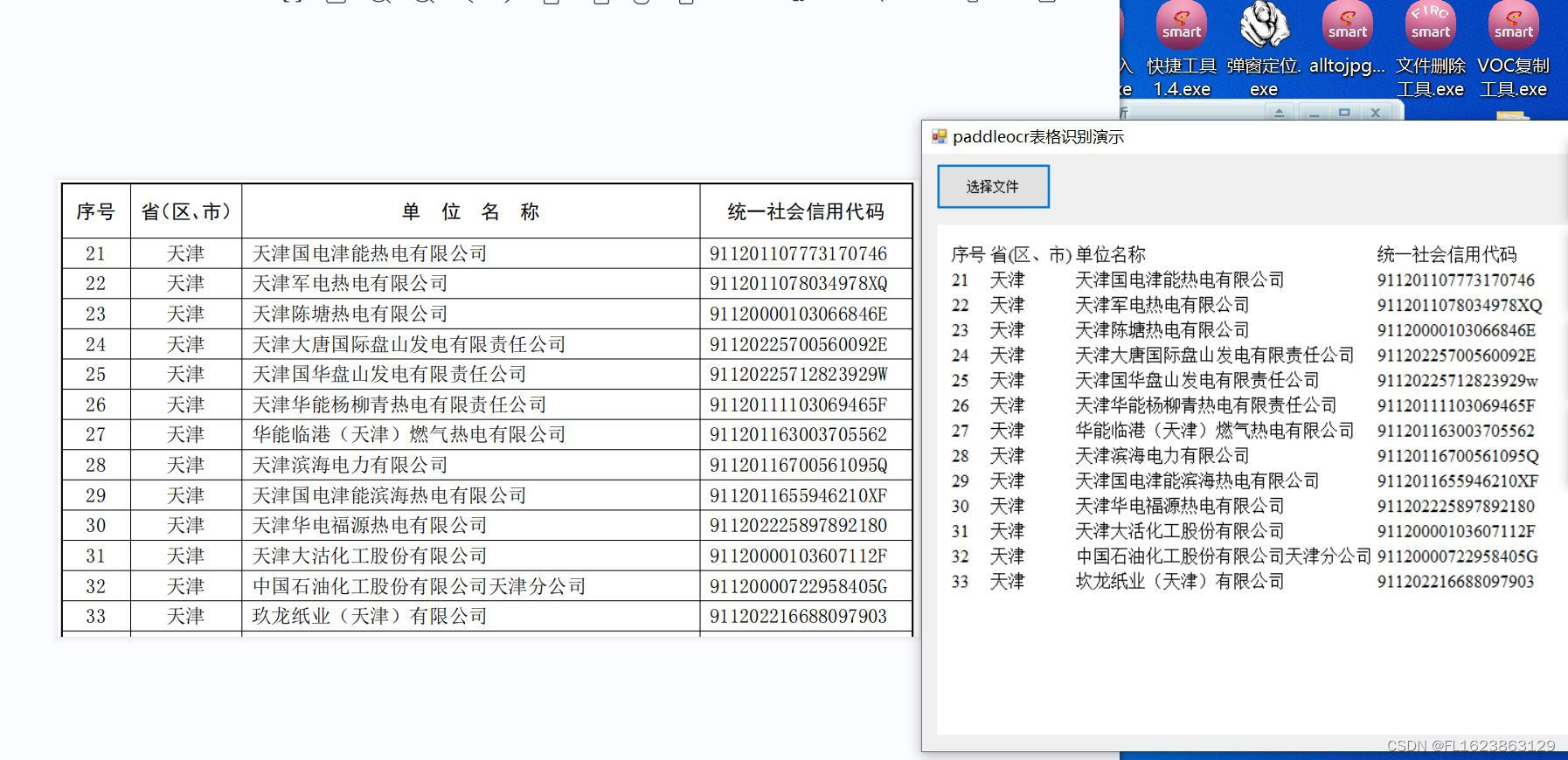
【官方实现部分代码】
FullOcrModel model = LocalFullModels.ChineseV3;
byte[] sampleImageData;
string sampleImageUrl = @"https://www.tp-link.com.cn/content/images2017/gallery/4288_1920.jpg";
using (HttpClient http = new HttpClient())
{
Console.WriteLine("Download sample image from: " + sampleImageUrl);
sampleImageData = await http.GetByteArrayAsync(sampleImageUrl);
}
using (PaddleOcrAll all = new PaddleOcrAll(model, PaddleDevice.Mkldnn())
{
AllowRotateDetection = true, /* 允许识别有角度的文字 */
Enable180Classification = false, /* 允许识别旋转角度大于90度的文字 */
})
{
// Load local file by following code:
// using (Mat src2 = Cv2.ImRead(@"C:\test.jpg"))
using (Mat src = Cv2.ImDecode(sampleImageData, ImreadModes.Color))
{
PaddleOcrResult result = all.Run(src);
Console.WriteLine("Detected all texts: \n" + result.Text);
foreach (PaddleOcrResultRegion region in result.Regions)
{
Console.WriteLine($"Text: {region.Text}, Score: {region.Score}, RectCenter: {region.Rect.Center}, RectSize: {region.Rect.Size}, Angle: {region.Rect.Angle}");
}
}
}
【源码下载】
【测试环境】
vs2019
netframework4.7.2
opencvsharp4.8.0
?
文章来源:https://blog.csdn.net/FL1623863129/article/details/135570852
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SpringMVC controller方法返回值见解3
- 力扣每日一题 2625.构造有效字符串的最少插入数
- 生信软件11 - 基于ACMG的CNV注释工具ClassifyCNV
- 算法训练营第五十天|123.买卖股票的最佳时机III 188.买卖股票的最佳时机IV
- Everything结合内网穿透搭建在线资料库并实现随时随地远程访问
- Thinkphp 5框架学习
- centOS系统yum安装和卸载mongodb
- 3D曲面图
- R语言生物群落(生态)数据统计分析与绘图教程
- 第3章-第3节-Java核心类库之Scanner和Random