高分辨大尺寸图像的目标检测切图处理
发布时间:2024年01月08日
对于yolo等目标检测框架,输入的尺寸通常为640x640,这对于常规的图片尺寸和常规目标检测足够了。但是在诸如航拍图像等任务上,图像尺寸通常几千x几千甚至上万,目标也是非常小的,如果resize到640的尺寸,显然目标都已经丢失完了。实际上可以通过切图的方式进行推理,也就是将高分辨率的图切成640x640的图像块,每一个块再去做目标检测,最后再将图像块中目标的坐标转换为大尺寸图上即可。
以下是基于python的切图:
import torch
from PIL import Image
import numpy as np
import math
import matplotlib.pyplot as plt
import cv2
def split_and_overlap(image_path, output_size=640, overlap_pixels_x=100, overlap_pixels_y=100,normalize=False):
"""
@param image_path:
@param output_size: 切图小图的尺寸
@param overlap_pixels_x: 经过在训练集上可视化分析,目标框的长和框都分布在100像素内,故设为为100像素
@param overlap_pixels_y:
@return:
(num_cut, Channel, output_size, output_size)=》(切图个数,通道,小图尺寸),
{"num_x": 在x轴上的切图数量,
"num_y": 在y轴上的切图数量}
"""
# 打开图像 1281*1920*3
original_image = cv2.imread(image_path)
if normalize:
original_image=original_image/255
original_height,original_width,_ = original_image.shape
# 计算每个小图的大小
tile_width = output_size
tile_height = output_size
# 初始化结果列表
result_images = []
# 计算能够整切的图像的长和宽
target_width = math.ceil((original_width - overlap_pixels_x) / (output_size - overlap_pixels_x)) * (
output_size - overlap_pixels_x) + overlap_pixels_x
target_height = math.ceil((original_height - overlap_pixels_y) / (output_size - overlap_pixels_y)) * (
output_size - overlap_pixels_y) + overlap_pixels_y
# 填充到target尺寸
original_image_pad = np.pad(original_image, ((0, target_height-original_height),(0, target_width-original_width), (0, 0)), mode='constant', constant_values=0)
# 开始切割和堆叠
for y_block_id in range(0, (target_height - overlap_pixels_y) // (output_size - overlap_pixels_y)):
for x_block_id in range(0, (target_width - overlap_pixels_x) // (output_size - overlap_pixels_x)):
# 裁剪图像
left = max(x_block_id * (tile_width - overlap_pixels_x), 0)
up = max(y_block_id * (tile_height - overlap_pixels_y), 0)
box = (left, up, left + output_size, up + output_size)
print(box)
tile_image = original_image_pad[up:up + output_size,left:left + output_size,:]
# 添加到结果列表
result_images.append(tile_image)
# 将result_images转为ndarray,形成[num_block,3,630,630]的张量
return (np.array(result_images).transpose((0, 3, 2, 1)),
{"num_x": (target_width - overlap_pixels_x) // (output_size - overlap_pixels_x),
"num_y": (target_height - overlap_pixels_y) // (output_size - overlap_pixels_y)})
def visualize_tensor(tensor, columns=3):
# 获取张量的形状
batch_size, num_channels, height, width = tensor.shape
# 计算行数
rows = int(np.ceil(batch_size / columns))
# 设置画布大小
plt.figure(figsize=(15, 15))
# 循环遍历每个图像
for i in range(batch_size):
plt.subplot(rows, columns, i + 1)
# 提取图像数据
image_data = np.transpose(tensor[i], (2, 1, 0)) # 将通道放在最后的顺序
# 可能需要进行适当的缩放或预处理,具体取决于你的数据
# 显示图像
plt.imshow(image_data)
plt.axis('off') # 关闭坐标轴
plt.subplots_adjust(wspace=0.05, hspace=0.05)
plt.show()
if __name__ == "__main__":
# 示例用法
image_path = "yolov5/0006.jpg"
# 切图
result_images, cut_meta = split_and_overlap(image_path,normalize=False)
for i in range(result_images.shape[0]):
# 获取单张小图片的数据
image_data = result_images[i].transpose(2, 1, 0) # 将通道放到最后一个维度
image = Image.fromarray(image_data)
# 保存小图片,方便验证
image.save(f'cut/image_{i + 1}.png')
print(cut_meta)
inp = torch.tensor(result_images, dtype=torch.float32)
# 可视化小图片
visualize_tensor(inp,columns=cut_meta['num_x'])
通过将[B,3,640,640]传入yolo检测中,相当于同时对B张图片进行检测,最终得到B个图像中的检测框信息。那么如何将小图上的检测框bbox坐标转换到大图上的坐标呢?也很简单
对于某一个小图,指导在B维度上的序号idx就知道这是第几张小图,然后通过列数运算能够得知所处几行几列的位置:
# 前面有N行,M列
N = cut_block_id // num_block_x
M = cut_block_id % num_block_x
# 也就是左侧有M个540像素,上侧有N个540像素,
# 在整图上的绝对坐标
center_x = center_x + M * 540
center_y = center_y + N * 540
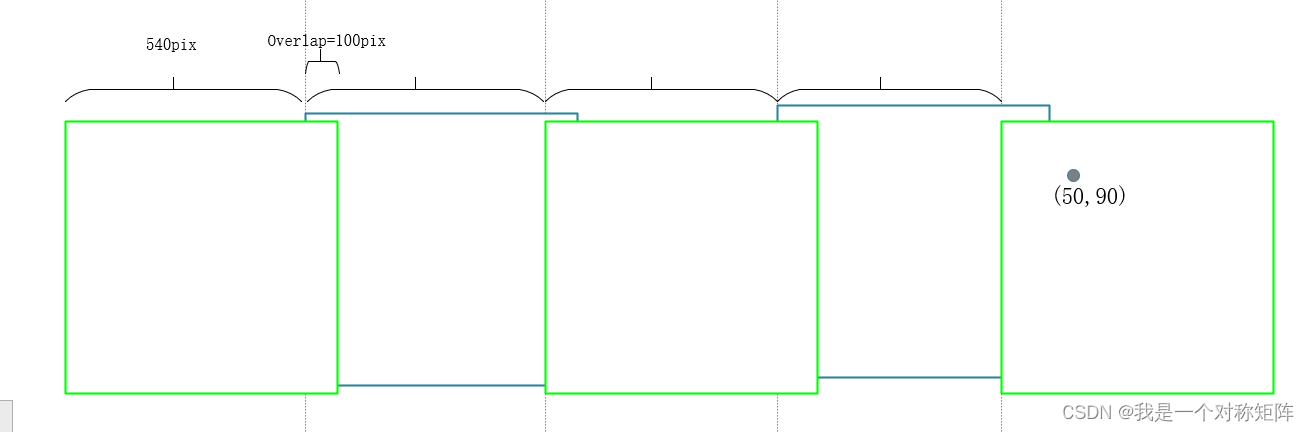
如图所示,某个小图中坐标为(50,90),通过计算得知所处第5列,则左侧有4个小图,考虑到有重叠区域,则左侧有4个540像素,故该坐标在大图中侧横坐标为50+540x4=2210。同理,也可以通过这样的方法计算其在大图中纵坐标的位置。
文章来源:https://blog.csdn.net/qq_40243750/article/details/135449420
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- VB6获取多个汉字拼音的首字母,vba字符串转拼音
- 并发编程之JUC并发工具类下
- 牛客周赛 Round 24
- 1855_emacs_compnay的使用探索
- uni-app如何解决在for循环里调用异步请求获取数据顺序混乱问题
- equals()比较字符串和MySQL中=比较结果不一致
- 运维之道—生产环境安装mysql
- 【手撕C语言 第三集】初识C语言
- 对象转成json,由于数据量过大压缩成.json.zip格式
- 【架构师视角系列】Apollo配置中心之Client端(二)