基于Google guava工具实现一致性Hash算法的应用实践
发布时间:2024年01月18日
一、前言
在分布式架构系统中,要将数据存储到具体的节点上,如果采用普通的key%N取模Hash算法,将数据映射到具体的节点上,就有可能大部分数据集中在某一个节点,形成“热点”数据,造成数据分布失衡,二是如果有一个机器加入或退出这个集群,则大部分的数据映射都无效了,数据需要重新进行排列。
基于上面普通Hash算法的问题,1997年由麻省理工学院提出一致性Hash算法,引入了“虚拟节点”的概念:即想象在这个环上有很多“虚拟节点”,数据的存储是沿着环的顺时针方向找一个虚拟节点,每个虚拟节点都会关联到一个真实节点;一个真实节点对应多个虚拟节点,虚拟节点足够多的情况下,可以使数据分布尽可能的平衡,但是需要注意的是一致性Hash算法也不能百分百解决普通Hash算法的问题,极端情况下,可能存在和普通Hash算法一样的问题。
二、基于一致性Hash算法解决普通Hash算法常见问题
在业务中,假设有一个场景,需要把用户User信息尽可能均衡的保存到32个后端用户数据库中(为了有对比效果,这里使用重写User hashcode()方法的方式来通过HashMap存储来实现)。
1. 普通Hash算法
- 参考实现代码:
import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
public class CommonHashTest2 {
static class User {
private String name;
private int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
CommonHashTest2.User user = (CommonHashTest2.User) o;
return age == user.age && Objects.equals(name, user.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public String toString() {
return "User{" + "name='" + name + '\'' + ", age=" + age + '}';
}
}
/**
* 普通Hash算法
*/
public static void normalHash() {
Map<Integer, Integer> map1 = new HashMap<>();
for (int i = 0; i < 32; i++) {
CommonHashTest2.User user = new CommonHashTest2.User("name" + i, i);
int code = user.hashCode();
int key = code % 32;
Integer integer = map1.get(key);
if (integer != null) {
map1.put(key, ++integer);
} else {
map1.put(key, 1);
}
}
System.out.println("普通Hash算法分布情况:\n" + map1);
}
public static void main(String[] args) {
normalHash();
}
}
- 运行结果
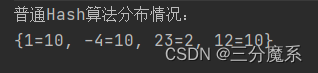
通过运行结果可以看到,普通Hash算法情况下数据分布失衡情况比较明显。
2. 基于Guava实现一致性Hash算法
- 引入maven依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.0.1-jre</version>
</dependency>
- 实现代码:
import com.google.common.hash.HashFunction;
import com.google.common.hash.Hashing;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
public class CommonHashTest {
static class User {
private String name;
private int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
CommonHashTest.User user = (CommonHashTest.User) o;
return age == user.age && Objects.equals(name, user.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public String toString() {
return "User{" + "name='" + name + '\'' + ", age=" + age + '}';
}
}
/**
* 普通Hash算法
*/
public static void normalHash() {
Map<Integer, Integer> map1 = new HashMap<>();
for (int i = 0; i < 32; i++) {
CommonHashTest.User user = new CommonHashTest.User("name" + i, i);
int code = user.hashCode();
int key = code % 32;
Integer integer = map1.get(key);
if (integer != null) {
map1.put(key, ++integer);
} else {
map1.put(key, 1);
}
}
System.out.println("普通Hash算法分布情况:\n" + map1);
}
/**
* guava实现一致性Hash算法
*/
public static void guavaConsistentHash() {
HashFunction hashFunction = Hashing.sha256();
Map<Integer, Integer> map2 = new HashMap<>();
for (int i = 0; i < 32; i++) {
CommonHashTest.User user = new CommonHashTest.User("name" + i, i);
int key2 = Hashing.consistentHash(hashFunction.hashString(user.toString(), StandardCharsets.UTF_8), 32);
Integer integer2 = map2.get(key2);
if (integer2 != null) {
map2.put(key2, ++integer2);
} else {
map2.put(key2, 1);
}
}
System.out.println("\nguava实现一致性Hash算法分布情况:\n" + map2);
}
public static void main(String[] args) {
normalHash();
guavaConsistentHash();
}
}
- 运行结果对比:

可以看到使用一致性Hash算法以后,比起普通Hash算法,数据分布确实均衡了,不过需要注意的是,Guava的一致性Hash算法也只能保证大概平衡,不能保证绝对平衡。
文章来源:https://blog.csdn.net/C_AJing/article/details/135660970
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 如何查看 Java 程序的内存使用情况?使用了多少百分比的堆
- UV胶应用广泛,涉及各行各业,那么电子UV胶水会腐蚀电子元器件吗?
- 用java语言写一个协同过滤算法
- VSCode-Python报错:Import“unreal“could not be resolved Pylance(reportMissingImports)
- 在 Python 中使用 OpenCV 通过透视校正转换图像
- 互联网摸鱼日报(2023-12-26)
- OWASP发布开源AI网络安全知识库框架AI Exchange
- Hive之set参数大全-6
- LeetCode Hot100 31.下一个排列
- 【中等】56. 合并区间