文本生成精准图像字幕,谷歌等开源PixelLLM
传统的大语言模型可以描述、回答与图像相关的问题,甚至进行复杂的图像推理。但使用大型语言模型进行文本定位,或用图像指代准确坐标却不太行。
为了进行该技术的探索,谷歌和加州大学圣地亚哥分校的研究人员开发了像素对齐大语言模型——PixelLLM。
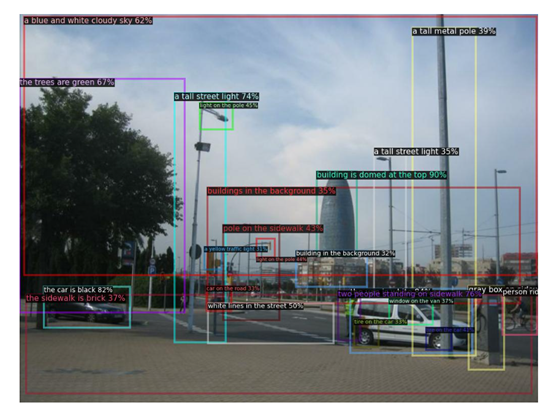
PixelLLM可以将图像位置信息作为输入或输出。当将位置作为输入时,模型可以根据位置生成与指定对象或区域相关的描述文本。
当生成位置作为输出时,模型可以为每个输出词语生成像素坐标,实现密集的词语定位。
项目地址:https://jerryxu.net/PixelLLM/
论文地址:https://arxiv.org/abs/2312.09237
PixelLLM的核心技术原理是,通过在大语言模型的单词特征之上添加一个小型多层感知机(MLP),来回归每个输出单词的像素坐标,从而实现对文本的密集定位。而语言模型的权重可以保持冻结,也可以通过低秩微调(LoRA)进行更新。
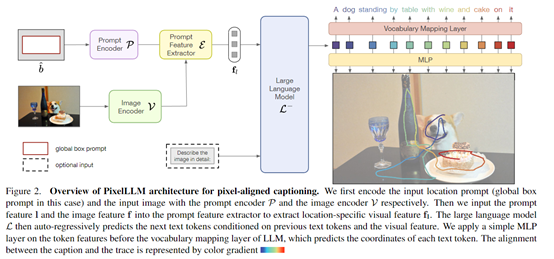
PixelLLM的整体架构包括图像编码器、提示编码器/特征提取器和大语言模型组成。
支持图像以及位置或文本的任意组合作为输入,并生成字幕以及每个词的像素定位作为输出。
图像编码器
图像编码器使用了Vision Transformer为输入图像生成表征,可以把图片转换成计算机可以理解的格式。
图像编码器使用了两种并行的主干:一种是从SAM模型初始化的ViT-H,用于获取强大的定位特征;
另一种是从EVA02初始化的ViT-L,用于学习语义特征。两种主干的输出在通道维上拼接,作为整体的图像表征。
提示编码/提取器
提示编码器将位置或文本等非图像输入编码为与图像表征相匹配的特征空间。对于位置输入,使用正弦余弦位置编码和线性层编码边界框坐标或点序列。对于文本输入,将词嵌入与图像表征拼接作为语言模型的前缀特征。
提示特征提取器用于接收来自提示编码器的特征,以及来自图像编码器的整幅图像表征。它的作用是从整幅图像中提取出与提示相关的区域特征。

提示特征提取器使用了基于学习性查询词的“双向变压”结构。其中提示特征和查询词作为“询问”;图像表征作为关键字和结果,并进行自注意力聚焦。
大语言模型
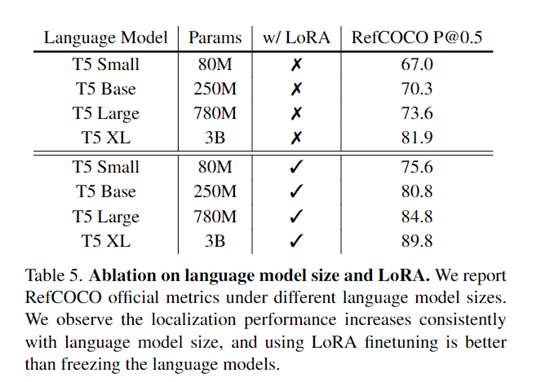
PixelLLM使用了谷歌曾发布的T5-XL作为基础语言模型,并将大部分参数进行了冻结, 只有提问和结果的投影层通过LoRA进行了低秩适配。
主要用于接收来自提示特征提取器的区域特定特征,以及可选的文本特征,并自动回归地生成字幕。
此外,在映射到词典空间的线性层之前,应用了多层感知器为每个词预测坐标。这样语言解码和定位预测可以并行地进行。
训练方法和实验数据
PixelLLM使用了谷歌的Localized Narrative数据集进行预训练。该数据集包含了人类对图像进行叙述的注释,以及注释者在叙述过程中的鼠标轨迹。这些注释提供了叙述中每个词语的同步位置信息。
在训练过程中,研究人员通过最小化生成的描述与实际注释之间的差异来优化PixelLLM模型。语言模型的权重可以保持固定,也可以使用低秩微调(LoRA)进行更新。
,时长00:13
为了评估PixelLLM的性能,研究人员在RefCOCO、Visual Genome等下游数据集上进行了微调,根据具体任务的要求,微调模型的参数,并在相应的任务上进行性能评估。
结果显示,PixelLLM在多个视觉-语言任务上取得了最先进的性能。例如,在RefCOCO的指代定位任务上达到了89.8。在Visual Genome的基于位置的描述生成任务上达到了19.9。
本文素材来源PixelLLM论文,如有侵权请联系删除
END
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Keras使用sklearn中的交叉验证和网格搜索
- 【Git】撤销命令
- DataStream API(转换算子)
- flutter 文件下载及存储路径
- gephi里做多个图,保证图例相同颜色表示相同种类
- RabbitMQ详解与Java实现
- 008 Linux_文件在磁盘上的管理
- [高阶+]使用状态机整理领域逻辑和生成代码
- confluence模版注入漏洞_CVE-2023-22527
- 软件测试|解决‘pip‘ 不是内部或外部命令,也不是可运行的程序或批处理文件