递归的递归之书:引言到第四章
引言
原文:Introduction
译者:飞龙

递归编程技术可以产生优雅的代码解决方案。然而,更常见的情况是它会使程序员感到困惑。这并不意味着程序员可以(或应该)忽视递归。尽管它以具有挑战性而闻名,但递归是一个重要的计算机科学主题,可以为编程本身提供深刻的见解。至少,了解递归可以帮助你在编程工作面试中脱颖而出。
如果你是一个对计算机科学感兴趣的学生,递归是一个必须克服的障碍,以理解许多流行的算法。如果你是一个编程训练营的毕业生或自学的程序员,成功地绕过了更理论性的计算机科学主题,递归问题仍然会在白板编程面试中出现。如果你是一个有经验的软件工程师,在之前从未接触过递归算法,你可能会发现递归是你知识中一个令人尴尬的空白。
不用担心。递归并不像教授它那样难以理解。正如我将在第一章中解释的那样,我认为递归的普遍误解是由于教学不佳而不是任何固有的困难。由于递归函数在日常编程中并不常用,许多人可以很好地没有它们。
但递归算法背后存在着一定的概念美,即使你不经常应用它们,也可以帮助你理解编程。递归也有视觉美。这种技术是分形的惊人数学艺术的基础,如图 1 所示的自相似形状。

图 1:这些分形的例子包括 Sierpiński 三角形(左)、希尔伯特曲线(中)和科赫雪花(右)。
然而,这本书并不完全是在赞美递归。我对这种技术提出了一些尖锐的批评。在存在更简单解决方案的情况下,递归被过度使用。递归算法可能难以理解,性能较差,并容易导致堆栈溢出错误。某种类型的程序员可能使用递归,并不是因为它是解决特定问题的正确技术,而只是因为他们觉得当他们编写其他程序员难以理解的代码时更聪明。计算机科学家约翰·威兰德博士曾说过:“当你在计算机科学领域获得博士学位时,他们会带你去一个特殊的房间,并解释你绝不能在现实生活中使用递归。它的唯一目的是让本科生的编程变得困难。”
因此,无论你是想在编程面试中获得优势,想创建美丽的数学艺术,还是固执地寻求最终理解这个概念的迷人特性,这本书将是你进入递归的兔子洞的向导(以及兔子洞内部的兔子洞)。递归是计算机科学中将专业人士与初学者区分开的主题之一。通过阅读本书,你将掌握一项重要的技能,并了解它的黑暗秘密:递归并不像人们想象的那么复杂。
这本书是为谁写的?
这本书是为那些对递归算法感到害怕或感兴趣的人写的。递归是一个对初学者或大一计算机科学学生来说似乎像黑魔法的主题之一。大多数递归课程很难理解,使这个主题看起来令人沮丧,甚至可怕。对于这些读者,我希望本书直接的解释和丰富的例子可以帮助他们最终理解这个主题。
这本书的唯一先决条件是具有 Python 或 JavaScript 编程语言的基本编程经验,这些章节的代码示例使用这些语言。本书的程序已经被简化到它们的本质;如果你知道如何调用和创建函数以及全局变量和局部变量之间的区别,你就足够了。
关于本书
本书共有 14 章:
第一部分:理解递归
-
第一章:什么是递归?解释了递归以及它是编程语言实现函数和函数调用的自然结果。本章还认为递归并不像许多人声称的那样优雅、神秘。
-
第二章:递归与迭代深入探讨了递归和迭代技术之间的差异(以及许多相似之处)。
-
第三章:经典递归算法涵盖了著名的递归程序,如汉诺塔、泛洪填充算法等。
-
第四章:回溯和树遍历算法讨论了递归特别适用的问题:遍历树数据结构,比如解决迷宫和导航目录时。
-
第五章:分治算法讨论了递归如何将大问题分解为更小的子问题,并涵盖了几种常见的分治算法。
-
第六章:排列和组合涵盖了涉及排序和匹配的递归算法,以及这些技术应用到的常见编程问题。
-
第七章:记忆化和动态规划解释了一些简单的技巧,以提高在现实世界中应用递归时的代码效率。
-
第八章:尾递归优化涵盖了尾递归优化,这是一种用于改进递归算法性能的常见技术,以及它的工作原理。
-
第九章:绘制分形介绍了可以通过递归算法以编程方式生成的有趣艺术。本章利用海龟图形生成其图像。
第二部分:项目
-
第十章:文件查找器涵盖了一个可以根据您提供的自定义搜索参数搜索计算机上文件的项目。
-
第十一章:迷宫生成器涵盖了一个自动生成任意大小迷宫的项目,使用了递归回溯算法。
-
第十二章:滑块拼图求解器涵盖了一个解决滑块拼图(也称为 15 拼图)的项目。
-
第十三章:分形艺术生成器探索了一个可以制作自己设计的自定义分形艺术的项目。
-
第十四章:Droste 生成器探索了一个使用 Pillow 图像处理模块制作递归图片的项目。
动手实验计算机科学
单单阅读关于递归的内容并不能教会你如何独立实现它。本书包含了许多 Python 和 JavaScript 编程语言的递归代码示例供您实验。如果您是编程新手,您可以阅读我的书《用 Python 自动化繁琐工作》,第二版(No Starch Press,2019 年),或者 Eric Matthes 的《Python 编程快速上手》,第二版(No Starch Press,2019 年)来介绍编程和 Python 编程语言。
我建议使用调试器逐行执行这些程序。 调试器允许您逐行执行程序并检查程序的状态,从而可以准确定位错误发生的位置。《用 Python 自动化繁琐工作》,第二版,第十一章介绍了如何使用 Python 调试器,并可在automatetheboringstuff.com/2e/chapter11免费在线阅读。
本书的章节展示了 Python 和 JavaScript 代码示例。Python 代码保存在*.py文件中,JavaScript 代码保存在.html文件中(而不是.js*文件)。例如,看下面的hello.py文件:
print('Hello, world!')
以及以下的hello.html文件:
<script type="text/javascript">
document.write("Hello, world!<br />");
</script>
这两个代码清单充当了一块罗塞塔石,描述了以两种不同语言产生相同结果的程序。
我鼓励您使用键盘手动复制这些程序,而不是简单地将它们的源代码复制粘贴到一个新文件中。这有助于您对程序的“肌肉记忆”,并迫使您在输入每一行时考虑它。
.html文件在技术上不是有效的,因为它们缺少几个必要的 HTML 标签,例如<html>和<body>,但您的浏览器仍然可以显示输出。这些标签是故意省略的。本书中的程序是为了简单和可读性而编写的,而不是为了展示 Web 开发的最佳实践。
安装 Python
虽然每台计算机都有一个可以查看本书中*.html*文件的 Web 浏览器,但如果您希望运行本书的 Python 代码,则必须单独安装 Python。您可以从python.org/downloads免费下载 Microsoft Windows、Apple macOS 和 Ubuntu Linux 的 Python。确保下载 Python 3 的版本(如 3.10),而不是 Python 2。Python 3 对语言进行了一些不兼容的更改,本书中的程序可能无法在 Python 2 上正确运行,如果能运行的话。
运行 IDLE 和 Python 代码示例
您可以使用 Python 自带的 IDLE 编辑器编写 Python 代码,也可以安装免费的编辑器,例如来自codewith.mu的 Mu 编辑器,来自www.jetbrains.com/pycharm/download的 PyCharm 社区版,或来自code.visualstudio.com/Download的 Microsoft Visual Studio Code。
要在 Windows 上打开 IDLE,打开屏幕左下角的开始菜单,在搜索框中输入IDLE,然后选择IDLE(Python 3.10 64 位)。
在 macOS 上,打开 Finder 窗口,点击应用程序?Python 3.10,然后点击 IDLE 图标。
在 Ubuntu 上,选择应用程序?附件?终端,然后输入IDLE 3。您也可以点击屏幕顶部的应用程序,选择编程,然后点击IDLE 3。
IDLE 有两种类型的窗口。交互式 shell 窗口有>>>提示符,用于逐个运行 Python 指令。当您想要尝试 Python 代码的一部分时,这是很有用的。文件编辑器窗口是您可以输入完整的 Python 程序并将它们保存为*.py*文件的地方。这是您将输入本书中 Python 程序的源代码的方式。要打开新的文件编辑器窗口,点击文件?新建文件。您可以通过点击运行?运行模块或按F5来运行程序。
在浏览器中运行 JavaScript 代码示例
您的计算机的 Web 浏览器可以运行 JavaScript 程序并显示它们的输出,但要编写 JavaScript 代码,您需要一个文本编辑器。像记事本或 TextMate 这样的简单程序就可以,但您也可以安装专门用于编写代码的文本编辑器,例如来自www.sublimetext.com的 IDLE 或 Sublime Text。
在输入 JavaScript 程序代码后,将文件保存为*.html文件,而不是.js*文件。在 Web 浏览器中打开它们以查看结果。任何现代 Web 浏览器都可以用于此目的。
一、什么是递归?
原文:Chapter 1 - What Is Recursion?
译者:飞龙
递归有着令人望而生畏的声誉。人们认为很难理解,但其核心只依赖于两件事:函数调用和栈数据结构。
大多数新程序员通过跟踪执行来追踪程序的操作。这是阅读代码的简单方法:你只需把手指放在程序顶部的代码行上,然后向下移动。有时你的手指会回到原点;其他时候,它会进入一个函数,然后返回。这使得很容易可视化程序的操作和顺序。
但要理解递归,你需要熟悉一个不太明显的数据结构,称为调用栈,它控制程序的执行流程。大多数编程初学者不了解栈,因为编程教程在讨论函数调用时通常甚至不提及它们。此外,自动管理函数调用的调用栈在源代码中根本看不到。
当你看不见并且不知道它的存在时,很难理解某件事!在本章中,我们将拉开窗帘,消除递归难以理解的夸大概念,你将能够欣赏其中的优雅之处。
递归的定义
在开始之前,让我们先把陈词滥调的递归笑话搞定,比如:“要理解递归,你必须先理解递归。”
在我写这本书的几个月里,我可以向你保证,这个笑话听得越多就越好笑。
另一个笑话是,如果你在谷歌上搜索递归,结果页面会问你是否是指递归。点击链接,如图 1-1 所示,会带你到…递归的搜索结果。
图 1-1:递归的谷歌搜索结果链接到递归的谷歌搜索结果。
图 1-2 显示了网络漫画 xkcd 中的一个递归笑话。

图 1-2:我如此元,甚至这个首字母缩略词(I.S. M.E.T.A.)(xkcd.com/917 by Randall Munroe)
关于 2010 年科幻动作电影《盗梦空间》的大多数笑话都是递归笑话。电影中的角色在梦中有梦,而这些梦中还有梦。
最后,作为计算机科学家,谁能忘记希腊神话中的递归半人马怪物?正如你在图 1-3 中所看到的,它是半马半递归半人马。

图 1-3:递归半人马。Joseph Parker 提供的图片。
根据这些笑话,你可能会得出结论,递归是一种元、自我引用、梦中梦、无限镜中镜的东西。让我们建立一个具体的定义:递归是指其定义包括自身的东西。也就是说,它具有自我引用的定义。
图 1-4 中的谢尔宾斯基三角形被定义为一个等边三角形,中间有一个倒置的三角形,形成三个新的等边三角形,每个三角形都包含一个谢尔宾斯基三角形。谢尔宾斯基三角形的定义包括谢尔宾斯基三角形。
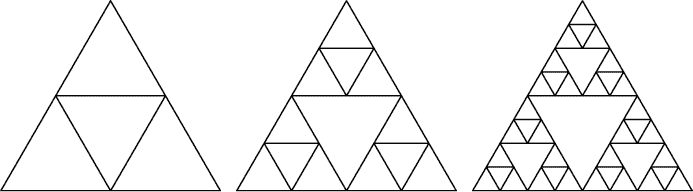
图 1-4:谢尔宾斯基三角形是包含谢尔宾斯基三角形的分形(递归形状)。
在编程上下文中,递归函数是调用自身的函数。在我们探索递归函数之前,让我们退一步,了解正常函数是如何工作的。程序员往往认为函数调用理所当然,但即使是有经验的程序员也会发现值得回顾下一节中的函数。
什么是函数?
函数可以被描述为程序中的迷你程序。它们是几乎每种编程语言的特性。如果您需要在程序中的三个不同位置运行相同的指令,而不是将源代码复制粘贴三次,您可以在函数中编写一次代码并调用函数三次。有益的结果是更短和更易读的程序。程序也更容易更改:如果您需要修复错误或添加功能,您只需要在一个地方更改程序,而不是三个地方。
所有编程语言在它们的函数中实现了四个特性:
-
函数有在调用函数时运行的代码。
-
参数(即值)在调用函数时传递。这是函数的输入,函数可以有零个或多个参数。
-
函数返回一个返回值。这是函数的输出,尽管一些编程语言允许函数不返回任何东西或返回像
undefined或None这样的空值。 -
程序记住了调用函数的代码行,并在函数完成执行时返回到它。
不同的编程语言可能具有其他特性,或者对如何调用函数有不同的选项,但它们都具有这四个一般元素。您可以在源代码中直观地看到这四个元素中的前三个,但是当函数返回时,程序如何跟踪执行应该返回到哪里呢?
为了更好地理解问题,创建一个functionCalls.py程序,其中包含三个函数:a()调用b(),b()调用c():
Python
def a():
print('a() was called.')
b()
print('a() is returning.')
def b():
print('b() was called.')
c()
print('b() is returning.')
def c():
print('c() was called.')
print('c() is returning.')
a()
这段代码等同于以下functionCalls.html程序:
JavaScript
<script type="text/javascript">
function a() {
document.write("a() was called.<br />");
b();
document.write("a() is returning.<br />");
}
function b() {
document.write("b() was called.<br />");
c();
document.write("b() is returning.<br />");
}
function c() {
document.write("c() was called.<br />");
document.write("c() is returning.<br />");
}
a();
</script>
当您运行此代码时,输出如下:
a() was called.
b() was called.
c() was called.
c() is returning.
b() is returning.
a() is returning.
输出显示了函数a(),b()和c()的开始。然后,当函数返回时,输出以相反的顺序出现:c(),b(),然后是a()。注意文本输出的模式:每次函数返回时,它都记住了最初调用它的代码行。当c()函数调用结束时,程序返回到b()函数并显示b()正在返回。然后b()函数调用结束,程序返回到a()函数并显示a()正在返回。最后,程序返回到程序末尾的原始a()函数调用。换句话说,函数调用并不会使程序的执行成为单向行程。
但程序如何记住是a()还是b()调用了c()?这个细节由程序隐式处理,使用一个调用栈。要理解调用栈如何记住函数调用结束时执行返回的位置,我们首先需要了解栈是什么。
什么是栈?
之前我提到过一个陈词滥调的笑话,“要理解递归,你必须先理解递归。”但这实际上是错误的:要真正理解递归,你必须先理解栈。
栈是计算机科学中最简单的数据结构之一。它像列表一样存储多个值,但与列表不同的是,它只限制您在栈的“顶部”添加或删除值。对于使用列表或数组实现的栈,“顶部”是最后一个项目,在列表或数组的右端。添加值称为推送值到栈上,而删除值称为弹出值出栈。
想象一下,您正在与某人进行一场漫谈。您正在谈论您的朋友 Alice,然后想起了关于您同事 Bob 的故事,但为了讲清楚这个故事,您首先必须解释一些关于您表妹 Carol 的事情。您讲完了关于 Carol 的故事,然后回到谈论 Bob,当您讲完了关于 Bob 的故事后,您又回到了谈论 Alice。然后您想起了您的兄弟 David,于是您讲了一个关于他的故事。最终,您回到了最初关于 Alice 的故事。
您的对话遵循类似堆栈的结构,就像图 1-5 中的那样。对话类似于堆栈,因为当前话题总是在堆栈的顶部。

图 1-5:您的漫谈对话堆栈
在我们的对话堆栈中,新话题被添加到堆栈的顶部,并在完成时被移除。之前的话题在堆栈中的当前话题下面被“记住”。
如果我们限制自己使用append()和pop()方法来执行推入和弹出操作,我们可以将 Python 列表用作堆栈。JavaScript 数组也可以通过它们的push()和pop()方法用作堆栈。
例如,考虑这个cardStack.py程序,它将扑克牌的字符串值推入和弹出到名为cardStack的列表的末尾:
Python
cardStack = [] # ?
cardStack.append('5 of diamonds') # ?
print(','.join(cardStack))
cardStack.append('3 of clubs')
print(','.join(cardStack))
cardStack.append('ace of hearts')
print(','.join(cardStack))
cardStack.pop() # ?
print(','.join(cardStack))
以下的cardStack.html程序包含了 JavaScript 中的等效代码:
JavaScript
<script type="text/javascript">
let cardStack = []; // ?
cardStack.push("5 of diamonds"); // ?
document.write(cardStack + "<br />");
cardStack.push("3 of clubs");
document.write(cardStack + "<br />");
cardStack.push("ace of hearts");
document.write(cardStack + "<br />");
cardStack.pop() // ?
document.write(cardStack + "<br />");
</script>
当您运行此代码时,输出如下所示:
5 of diamonds
5 of diamonds,3 of clubs
5 of diamonds,3 of clubs,ace of hearts
5 of diamonds,3 of clubs
堆栈从空开始?。推入堆栈的是代表卡片的三个字符串?。然后弹出堆栈?,这将移除红桃 A 并再次将梅花三放在堆栈的顶部。cardStack堆栈的状态在图 1-6 中进行了跟踪,从左到右。
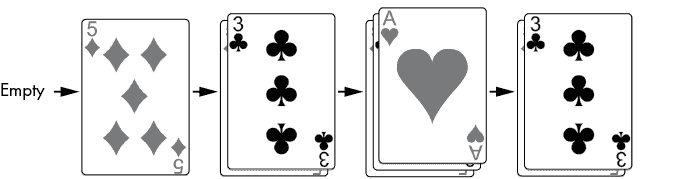
图 1-6:堆栈开始为空。然后将卡片推入和弹出堆栈。
您只能看到卡堆中的最顶部卡片,或者在我们程序的堆栈中,最顶部的值。在最简单的堆栈实现中,您无法看到堆栈中有多少张卡片(或值)。您只能看到堆栈是否为空。
堆栈是一种LIFO数据结构,代表后进先出,因为推入堆栈的最后一个值是弹出的第一个值。这种行为类似于您的网络浏览器的“返回”按钮。您的浏览器标签的历史记录就像一个包含您按顺序访问的所有页面的堆栈。浏览器始终显示历史记录“堆栈”中的顶部网页。单击链接会将新网页推入历史记录堆栈,而单击“返回”按钮会弹出顶部网页并显示其下面的网页。
调用堆栈是什么?
程序也使用堆栈。程序的调用堆栈,也简称为堆栈,是一堆帧对象。帧对象,也简称为帧,包含有关单个函数调用的信息,包括调用函数的代码行,因此当函数返回时,执行可以回到那里。
当调用函数时,将创建帧对象并将其推送到堆栈上。当函数返回时,该帧对象将从堆栈中弹出。如果我们调用一个调用一个调用函数的函数,调用堆栈将在堆栈上有三个帧对象。当所有这些函数返回时,调用堆栈将在堆栈上有零个帧对象。
程序员不必编写处理帧对象的代码,因为编程语言会自动处理它们。不同的编程语言有不同的实现帧对象的方式,但通常它们包含以下内容:
-
返回地址,或者函数返回时执行的位置
-
传递给函数调用的参数
-
在函数调用期间创建的一组局部变量
例如,看一下以下localVariables.py程序,它有三个函数,就像我们之前的functionCalls.py和functionCalls.html程序一样:
Python
def a():
spam = 'Ant' # ?
print('spam is ' + spam) # ?
b() # ?
print('spam is ' + spam)
def b():
spam = 'Bobcat' # ?
print('spam is ' + spam)
c() # ?
print('spam is ' + spam)
def c():
spam = 'Coyote' # ?
print('spam is ' + spam)
a() # ?
这个localVariables.html是等效的 JavaScript 程序:
JavaScript
<script type="text/javascript">
function a() {
let spam = "Ant"; // ?
document.write("spam is " + spam + "<br />"); // ?
b(); // ?
document.write("spam is " + spam + "<br />");
}
function b() {
let spam = "Bobcat";//# ?
document.write("spam is " + spam + "<br />");
c(); // ?
document.write("spam is " + spam + "<br />");
}
function c() {
let spam = "Coyote"; // ?
document.write("spam is " + spam + "<br />");
}
a(); // ?
</script>
当您运行此代码时,输出如下所示:
spam is Ant
spam is Bobcat
spam is Coyote
spam is Bobcat
spam is Ant
当程序调用函数a() ?时,将创建一个帧对象并将其放置在调用堆栈顶部。该帧存储传递给a()的任何参数(在本例中没有),以及局部变量spam ?和a()函数返回时执行的位置。
当调用a()时,它显示其局部spam变量的内容,即Ant ?。当a()中的代码调用函数b() ?时,将创建一个新的帧对象并将其放置在调用堆栈上方,用于a()的帧对象。b()函数有自己的局部spam变量 ?,并调用c() ?。为c()调用创建一个新的帧对象并将其放置在调用堆栈上,其中包含c()的局部spam变量 ?。随着这些函数的返回,帧对象从调用堆栈中弹出。程序执行知道要返回到哪里,因为返回信息存储在帧对象中。当执行从所有函数调用返回时,调用堆栈为空。
图 1-7 显示了每个函数调用和返回时调用堆栈的状态。请注意,所有局部变量都具有相同的名称:spam。我这样做是为了突出局部变量始终是具有不同值的单独变量,即使它们与其他函数中的局部变量具有相同的名称。

图 1-7:localVariables程序运行时调用堆栈的状态
正如您所看到的,编程语言可以具有相同名称(spam)的单独的局部变量,因为它们保存在单独的帧对象中。当在源代码中使用局部变量时,将使用顶部帧对象中具有该名称的变量。
每个运行的程序都有一个调用堆栈,多线程程序每个线程都有一个调用堆栈。但是当您查看程序的源代码时,您无法在代码中看到调用堆栈。调用堆栈不像其他数据结构一样存储在变量中;它在后台自动处理。
调用堆栈在源代码中不存在的事实是递归对初学者如此令人困惑的主要原因:递归依赖于程序员甚至看不到的东西!揭示堆栈数据结构和调用堆栈的工作原理消除了递归背后的许多神秘之处。函数和堆栈都是简单的概念,我们可以将它们结合起来理解递归是如何工作的。
递归函数和堆栈溢出是什么?
递归函数是调用自身的函数。这个shortest.py程序是递归函数的最短可能示例:
Python
def shortest():
shortest()
shortest()
前面的程序等同于这个shortest.html程序:
JavaScript
<script type="text/javascript">
function shortest() {
shortest();
}
shortest();
</script>
shortest()函数除了调用shortest()函数什么也不做。当这发生时,它再次调用shortest()函数,然后shortest()会调用shortest(),依此类推,看起来永远不会停止。这类似于地壳靠着一只巨大的空间乌龟的背部,而那只乌龟又靠着另一只乌龟。在那只乌龟下面:另一只乌龟。如此循环,永无止境。
但是这个“无穷递归”的理论并不能很好地解释宇宙学,也不能很好地解释递归函数。由于调用堆栈使用了计算机的有限内存,这个程序不能永远继续下去,就像无限循环那样。这个程序唯一能做的就是崩溃并显示错误消息。
shortest.py的 Python 输出看起来像这样:
Traceback (most recent call last):
File "shortest.py", line 4, in <module>
shortest()
File "shortest.py", line 2, in shortest
shortest()
File "shortest.py", line 2, in shortest
shortest()
File "shortest.py", line 2, in shortest
shortest()
[Previous line repeated 996 more times]
RecursionError: maximum recursion depth exceeded
shortest.html的 JavaScript 输出在 Google Chrome 网页浏览器中看起来像这样(其他浏览器会有类似的错误消息):
Uncaught RangeError: Maximum call stack size exceeded
at shortest (shortest.html:2)
at shortest (shortest.html:3)
at shortest (shortest.html:3)
at shortest (shortest.html:3)
at shortest (shortest.html:3)
at shortest (shortest.html:3)
at shortest (shortest.html:3)
at shortest (shortest.html:3)
at shortest (shortest.html:3)
at shortest (shortest.html:3)
这种错误被称为堆栈溢出。(这就是流行网站stackoverflow.com得名的地方。)不断的函数调用而没有返回会使调用堆栈增长,直到计算机为调用堆栈分配的所有内存都被用完。为了防止这种情况,Python 和 JavaScript 解释器在一定数量的不返回值的函数调用后会终止程序。
这个限制被称为最大递归深度或最大调用堆栈大小。对于 Python,这被设置为 1,000 个函数调用。对于 JavaScript,最大调用堆栈大小取决于运行代码的浏览器,但通常至少为 10,000 左右。把堆栈溢出想象成当调用堆栈变得“太高”(也就是消耗了太多的计算机内存)时发生,就像图 1-8 中的情况。
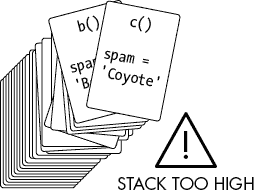
图 1-8:当调用堆栈变得太高时,堆栈溢出就会发生,有太多的帧对象占用了计算机的内存。
堆栈溢出不会损坏计算机。计算机只是检测到函数调用的限制已经达到并终止程序。最坏的情况下,你会丢失程序中的任何未保存的工作。堆栈溢出可以通过有一个叫做基本情况的东西来防止,接下来会解释。
基本情况和递归情况
堆栈溢出示例有一个shortest()函数调用shortest()但从不返回。为了避免崩溃,需要有一个情况,或一组情况,使得函数停止调用自身,而是直接返回。这被称为基本情况。相比之下,函数递归调用自身的情况被称为递归情况。
所有递归函数都需要至少一个基本情况和至少一个递归情况。如果没有基本情况,函数永远不会停止进行递归调用,最终导致堆栈溢出。如果没有递归情况,函数永远不会调用自身,只是一个普通函数,而不是递归函数。当你开始编写自己的递归函数时,一个很好的第一步是找出基本情况和递归情况应该是什么。
看一下这个shortestWithBaseCase.py程序,它定义了不会因堆栈溢出而崩溃的最短递归函数:
Python
def shortestWithBaseCase(makeRecursiveCall):
print('shortestWithBaseCase(%s) called.' % makeRecursiveCall)
if not makeRecursiveCall:
# BASE CASE
print('Returning from base case.')
return # ?
else:
# RECURSIVE CASE
shortestWithBaseCase(False) # ?
print('Returning from recursive case.')
return
print('Calling shortestWithBaseCase(False):')
shortestWithBaseCase(False) # ?
print()
print('Calling shortestWithBaseCase(True):')
shortestWithBaseCase(True) # ?
这段代码等同于以下shortestWithBaseCase.html程序:
JavaScript
<script type="text/javascript">
function shortestWithBaseCase(makeRecursiveCall) {
document.write("shortestWithBaseCase(" + makeRecursiveCall +
") called.<br />");
if (makeRecursiveCall === false) {
// BASE CASE
document.write("Returning from base case.<br />");
return; // ?
} else {
// RECURSIVE CASE
shortestWithBaseCase(false); // ?
document.write("Returning from recursive case.<br />");
return;
}
}
document.write("Calling shortestWithBaseCase(false):<br />");
shortestWithBaseCase(false); // ?
document.write("<br />");
document.write("Calling shortestWithBaseCase(true):<br />");
shortestWithBaseCase(true); // ?
</script>
当你运行这段代码时,输出看起来像这样:
Calling shortestWithBaseCase(False):
shortestWithBaseCase(False) called.
Returning from base case.
Calling shortestWithBaseCase(True):
shortestWithBaseCase(True) called.
shortestWithBaseCase(False) called.
Returning from base case.
Returning from recursive case.
这个函数除了提供递归的简短示例外并没有做任何有用的事情(并且通过删除文本输出可以使其更短,但文本对我们的解释很有用)。当调用shortestWithBaseCase(False)时?,基本情况被执行,函数仅返回?。然而,当调用shortestWithBaseCase(True)时?,递归情况被执行,并调用shortestWithBaseCase(False)?。
重要的是要注意,当从?递归调用shortestWithBaseCase(False)并返回时,执行不会立即回到?处的原始函数调用。递归调用后的递归情况中的其余代码仍然会运行,这就是为什么输出中会出现Returning from recursive case.。从基本情况返回并不会立即返回到之前发生的所有递归调用。这在下一节中的countDownAndUp()示例中将是重要的要记住的。
递归调用前后的代码
递归情况中的代码可以分为两部分:递归调用前的代码和递归调用后的代码。(如果在递归情况中有两个递归调用,比如第二章中的斐波那契数列示例,那么会有一个前、一个中和一个后。但现在让我们保持简单。)
重要的是要知道,达到基本情况并不一定意味着递归算法的结束。它只意味着基本情况不会继续进行递归调用。
例如,考虑这个countDownAndUp.py程序,其递归函数从任何数字倒数到零,然后再次升到该数字:
Python
def countDownAndUp(number):
print(number) # ?
if number == 0:
# BASE CASE
print('Reached the base case.') # ?
return
else:
# RECURSIVE CASE
countDownAndUp(number - 1) # ?
print(number, 'returning') # ?
return
countDownAndUp(3) # ?
这里是等效的countDownAndUp.html程序:
JavaScript
<script type="text/javascript">
function countDownAndUp(number) {
document.write(number + "<br />"); // ?
if (number === 0) {
// BASE CASE
document.write("Reached the base case.<br />"); // ?
return;
} else {
// RECURSIVE CASE
countDownAndUp(number - 1); // ?
document.write(number + " returning<br />"); // ?
return;
}
}
countDownAndUp(3); # ?
</script>
当运行此代码时,输出如下:
3
2
1
0
Reached the base case.
1 returning
2 returning
3 returning
请记住,每次调用函数时,都会创建一个新帧并推送到调用堆栈上。这个帧是存储所有局部变量和参数(如number)的地方。因此,对于调用堆栈上的每个帧都有一个单独的number变量。这是关于递归经常令人困惑的另一个要点:尽管从源代码看,似乎只有一个number变量,但请记併,因为它是局部变量,实际上对于每个函数调用都有一个不同的number变量。
当调用countDownAndUp(3)时?,会创建一个帧,该帧的局部变量number设置为3。函数将number变量打印到屏幕上?。只要number不是0,就会递归调用countDownAndUp(),参数为number - 1?。当调用countDownAndUp(2)时,会推送一个新帧到堆栈上,并且该帧的局部变量number设置为2。同样,递归情况被触发,调用countDownAndUp(1),再次触发递归情况并调用countDownAndUp(0)。
连续进行递归函数调用然后从递归函数调用返回的模式是导致数字倒数出现的原因。一旦调用countDownAndUp(0),就会达到基本情况?,不会再进行递归调用。然而,这并不是我们程序的结束!当达到基本情况时,局部变量number为0。但当基本情况返回并且帧从调用堆栈中弹出时,其下面的帧有自己的局部变量number,其值始终为1。当执行返回到调用堆栈中的前一个帧时,递归调用后的代码会被执行?。这就是导致数字升序出现的原因。图 1-9 显示了在递归调用countDownAndUp()并返回时调用堆栈的状态。
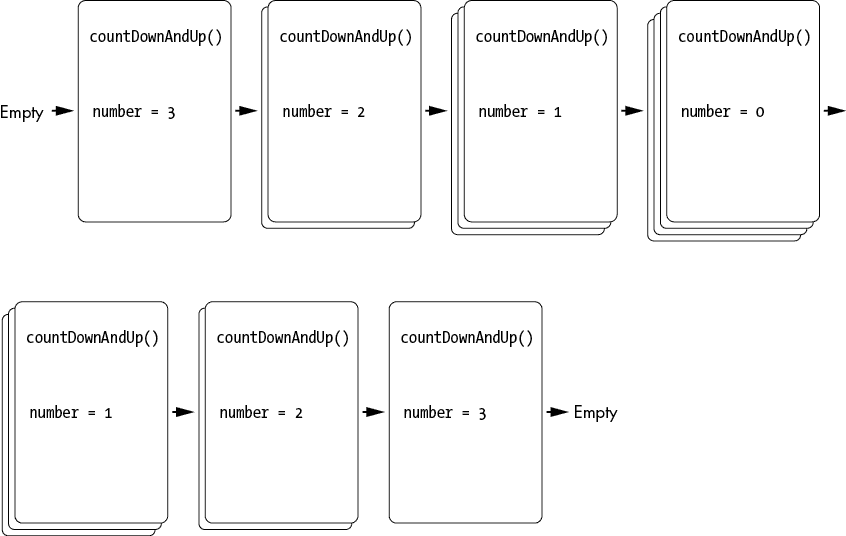
图 1-9:调用堆栈跟踪每个函数调用中“number”局部变量的值
当基本情况达到时,代码不会立即停止,这一点对于下一章中的阶乘计算非常重要。请记住,递归情况之后的任何代码仍然必须运行。
此时,您可能会认为递归的countDownAndUp()函数设计过于复杂,难以理解。为什么不使用迭代解决方案来打印数字呢?迭代方法通常被认为是递归的相反,它使用循环重复任务直到完成。
每当您问自己,“使用循环会更容易吗?”答案几乎肯定是“是”,您应该避免使用递归解决方案。递归对于初学者和有经验的程序员都可能很棘手,递归代码并不自动比迭代代码“更好”或“更优雅”。可读性强、易于理解的代码比递归提供的任何所谓的优雅更重要。然而,在某些情况下,算法可以清晰地映射到递归方法。涉及树状数据结构并需要回溯的算法特别适合使用递归。这些想法在第二章和第四章中进一步探讨。
总结
递归经常会让新手程序员感到困惑,但它建立在一个简单的思想上,即函数可以调用自身。每次进行函数调用时,都会向调用堆栈添加一个新的帧对象,其中包含与调用相关的信息(例如局部变量和函数返回时执行移动到的返回地址)。调用堆栈作为一个堆栈数据结构,只能通过向其“顶部”添加或删除数据来改变。这分别称为推入和弹出堆栈。
程序隐式处理调用堆栈,因此没有调用堆栈变量。调用函数会将一个帧对象推入调用堆栈,从函数返回会从调用堆栈中弹出一个帧对象。
递归函数有递归情况,即进行递归调用的情况,和基本情况,即函数简单返回的情况。如果没有基本情况或者错误阻止基本情况运行,执行将导致堆栈溢出,从而使程序崩溃。
递归是一种有用的技术,但递归并不会自动使代码“更好”或更“优雅”。这个想法在下一章中会更详细地探讨。
进一步阅读
您可以在 2018 年北湾 Python 大会上找到有关递归的其他介绍,标题为“递归入门:递归初学者指南”,网址为youtu.be/AfBqVVKg4GE。YouTube 频道 Computerphile 还在其视频“地球上的递归是什么?”中介绍了递归,网址为youtu.be/Mv9NEXX1VHc。最后,V. Anton Spraul 在他的书像程序员一样思考(No Starch Press,2012)和他的视频“递归(像程序员一样思考)”中讨论了递归,网址为youtu.be/oKndim5-G94。维基百科的递归文章在en.wikipedia.org/wiki/Recursion中有详细介绍。
您可以为 Python 安装“ShowCallStack”模块。该模块添加了一个“showcallstack()”函数,您可以将其放在代码中的任何位置,以查看程序在特定点的调用堆栈状态。您可以在pypi.org/project/ShowCallStack下载该模块并找到相关说明。
练习题
通过回答以下问题来测试你的理解能力:
-
一般来说,什么是递归的东西?
-
在编程中,什么是递归函数?
-
函数有哪四个特征?
-
什么是堆栈?
-
向堆栈的顶部添加和移除值的术语是什么?
-
假设你将字母J推送到堆栈,然后推送字母Q,然后弹出堆栈,然后推送字母K,然后再次弹出堆栈。堆栈是什么样子?
-
被推送和弹出到调用堆栈上的是什么?
-
是什么导致堆栈溢出?
-
什么是基本情况?
-
什么是递归情况?
-
递归函数有多少个基本情况和递归情况?
-
如果一个递归函数没有基本情况会发生什么?
-
如果一个递归函数没有递归情况会发生什么?
二、递归与迭代
原文:Chapter 2 - Recursion vs. Iteration
译者:飞龙
递归和迭代都没有一般上是更好的技术。事实上,任何递归代码都可以用循环和堆栈编写成迭代代码。递归并没有某种特殊的能力使其能够执行迭代算法无法执行的计算。任何迭代循环都可以重写为递归函数。
本章比较和对比了递归和迭代。我们将研究经典的斐波那契和阶乘函数,并看看它们的递归算法为什么有关键的弱点。我们还将通过考虑指数算法来探索递归方法可以产生的见解。总的来说,本章揭示了递归算法的所谓优雅之处,并展示了递归解决方案何时有用以及何时不适用。
计算阶乘
许多计算机科学课程使用阶乘计算作为递归函数的经典示例。一个整数(我们称之为n)的阶乘是从 1 到n的所有整数的乘积。例如,4 的阶乘是 4 × 3 × 2 × 1,即 24。感叹号是阶乘的数学表示法,如 4!,表示4 的阶乘。表 2-1 显示了前几个阶乘。
表 2-1:前几个整数的阶乘
| n! | 展开形式 | 乘积 | ||
|---|---|---|---|---|
| 1! | = | 1 | = | 1 |
| 2! | = | 1 × 2 | = | 2 |
| 3! | = | 1 × 2 × 3 | = | 6 |
| 4! | = | 1 × 2 × 3 × 4 | = | 24 |
| 5! | = | 1 × 2 × 3 × 4 × 5 | = | 120 |
| 6! | = | 1 × 2 × 3 × 4 × 5 × 6 | = | 720 |
| 7! | = | 1 × 2 × 3 × 4 × 5 × 6 × 7 | = | 5,040 |
| 8! | = | 1 × 2 × 3 × 4 × 5 × 6 × 7 × 8 | = | 40,320 |
阶乘在各种计算中都有用途——例如,找到某物排列的排列数。如果你想知道有多少种方式可以将四个人——Alice、Bob、Carol 和 David——排成一行,答案就是 4 的阶乘。四个可能的人可以先站在队伍中(4);然后对于这四个选项中的每一个,还有三个人可以站在第二位(4 × 3);然后两个人可以站在第三位(4 × 3 × 2);最后一个人站在第四位(4 × 3 × 2 × 1)。人们可以排成队伍的方式数量——也就是排列的数量——就是人数的阶乘。
现在让我们来看看计算阶乘的迭代和递归方法。
迭代阶乘算法
用迭代方法计算阶乘相当直接:在循环中将整数 1 到n相乘。迭代算法总是使用循环。factorialByIteration.py程序看起来像这样:
Python
def factorial(number):
product = 1
for i in range(1, number + 1):
product = product * i
return product
print(factorial(5))
而factorialByIteration.html程序看起来像这样:
JavaScript
<script type="text/javascript">
function factorial(number) {
let product = 1;
for (let i = 1; i <= number; i++) {
product = product * i;
}
return product;
}
document.write(factorial(5));
</script>
当你运行这段代码时,输出会显示 5!的计算结果如下:
120
用迭代方法计算阶乘没有问题;它很直接并且完成了任务。但是让我们也看看递归算法,以便更好地理解阶乘和递归本身的性质。
递归阶乘算法
注意 4 的阶乘是 4 × 3 × 2 × 1,5 的阶乘是 5 × 4 × 3 × 2 × 1。所以你可以说 5! = 5 × 4!。这是递归,因为 5 的阶乘(或任何数字n)的定义包括 4 的阶乘(数字n - 1)的定义。依此类推,4! = 4 × 3!,以此类推,直到必须计算 1!,即基本情况,它只是 1。
递归阶乘算法的 Python 程序factorialByRecursion.py使用了递归阶乘算法:
Python
def factorial(number):
if number == 1:
# BASE CASE
return 1
else:
# RECURSIVE CASE
return number * factorial(number - 1) # ?
print(factorial(5))
而factorialByRecursion.html的 JavaScript 程序与等效代码看起来是这样的:
JavaScript
<script type="text/javascript">
function factorial(number) {
if (number == 1) {
// BASE CASE
return 1;
} else {
// RECURSIVE CASE
return number * factorial(number - 1); // ?
}
}
document.write(factorial(5));
</script>
当你运行这段代码递归计算 5!时,输出与迭代程序的输出相匹配:
120
对许多程序员来说,这个递归代码看起来很奇怪。你知道factorial(5)必须计算 5 × 4 × 3 × 2 × 1,但很难指出这个乘法发生在哪一行代码上。
混淆是因为递归情况有一行 ?,其中一半在递归调用之前执行,另一半在递归调用返回后执行。我们不习惯一行代码只有一半在执行。
第一部分是factorial(number - 1)。这涉及计算number - 1并创建一个递归函数,导致调用栈中推送一个新的帧对象。这发生在递归调用之前。
代码再次运行时,旧的帧对象是在factorial(number - 1)返回后。当调用factorial(5)时,factorial(number - 1)将是factorial(4),返回值是24。这时第二部分代码运行。return number * factorial(number - 1)现在看起来像return 5 * 24,这就是为什么factorial(5)返回120。
图 2-1 跟踪了调用栈的状态,帧对象被推送(当递归函数调用时发生)和帧对象被弹出(当递归函数调用返回时)。注意乘法发生在递归调用之后,而不是之前。
当原始函数调用factorial()返回时,它返回了计算出的阶乘。
为什么递归阶乘算法很糟糕
用于计算阶乘的递归实现有一个关键的弱点。计算 5 的阶乘需要五次递归函数调用。这意味着在基本情况到达之前,调用栈上会有五个帧对象。这不可扩展。
如果你想计算 1001 的阶乘,递归的factorial()函数必须进行 1001 次递归函数调用。然而,你的程序很可能在完成之前引起堆栈溢出,因为进行如此多的函数调用而不返回会超过解释器的最大调用栈大小。这很糟糕;你绝对不会想在真实世界的代码中使用递归阶乘函数。
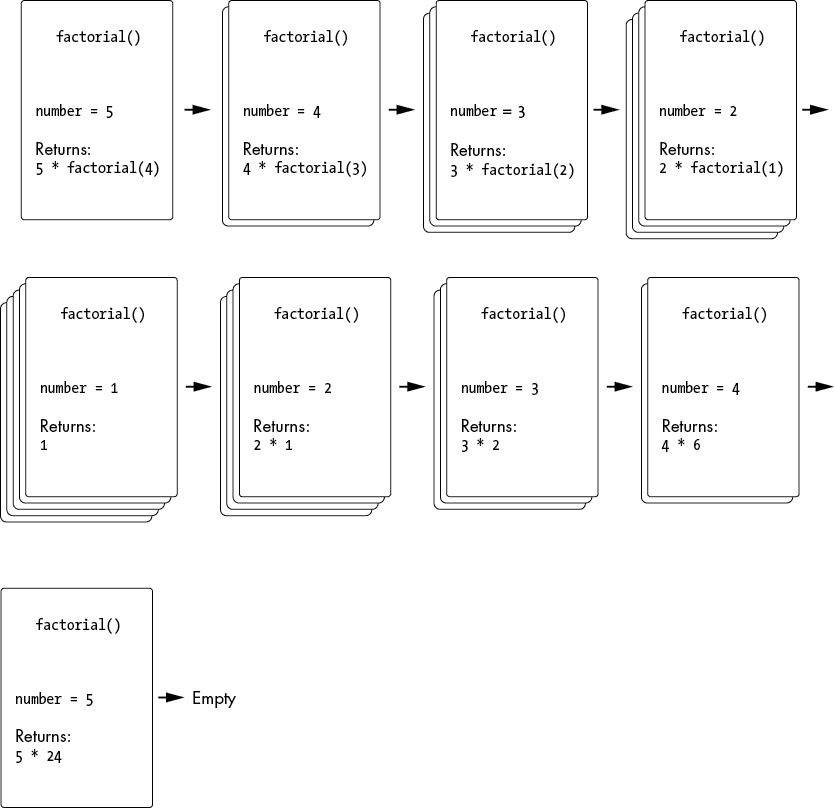
图 2-1:调用栈的状态,递归调用factorial()后的返回
另一方面,迭代阶乘算法将快速高效地完成计算。可以使用一些编程语言中的一种称为尾递归优化的技术来避免堆栈溢出。第八章涵盖了这个主题。然而,这种技术进一步复杂化了递归函数的实现。对于计算阶乘,迭代方法是最简单和最直接的。
计算斐波那契序列
斐波那契序列是介绍递归的另一个经典例子。数学上,整数的斐波那契序列以数字 1 和 1(有时是 0 和 1)开始。序列中的下一个数字是前两个数字的和。这创建了序列 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144 等,永远不会结束。
如果我们将序列中的最新两个数字称为a和b,您可以在图 2-2 中看到序列是如何增长的。

图 2-2:斐波那契序列的每个数字都是前两个数字的和。
让我们探索一些迭代和递归解决方案的代码示例,用于生成斐波那契数。
迭代斐波那契算法
迭代斐波那契示例很简单,由一个简单的for循环和两个变量a和b组成。这个fibonacciByIteration.py Python 程序实现了迭代斐波那契算法:
Python
def fibonacci(nthNumber):
a, b = 1, 1 # ?
print('a = %s, b = %s' % (a, b))
for i in range(1, nthNumber):
a, b = b, a + b # Get the next Fibonacci number. # ?
print('a = %s, b = %s' % (a, b))
return a
print(fibonacci(10))
这个fibonacciByIteration.html程序包含了等效的 JavaScript 代码:
JavaScript
<script type="text/javascript">
function fibonacci(nthNumber) {
let a = 1, b = 1; // ?
let nextNum;
document.write('a = ' + a + ', b = ' + b + '<br />');
for (let i = 1; i < nthNumber; i++) {
nextNum = a + b; // Get the next Fibonacci number. // ?
a = b;
b = nextNum;
document.write('a = ' + a + ', b = ' + b + '<br />');
}
return a;
};
document.write(fibonacci(10));
</script>
当您运行此代码来计算第 10 个斐波那契数时,输出如下:
a = 1, b = 1
a = 1, b = 2
a = 2, b = 3
# --snip--
a = 34, b = 55
55
程序只需要一次跟踪序列中的最新两个数字。由于斐波那契序列中的前两个数字被定义为 1,我们将1存储在变量a和b中?。在for循环内,通过将a和b相加来计算序列中的下一个数字?,这成为b的下一个值,而a获得b的前一个值。当循环结束时,b包含第n个斐波那契数,因此返回它。
递归斐波那契算法
计算斐波那契数涉及递归属性。例如,如果要计算第 10 个斐波那契数,您将第九个和第八个斐波那契数相加。要计算这些斐波那契数,您将第八个和第七个,然后第七个和第六个斐波那契数相加。会发生大量重复计算:注意到将第九个和第八个斐波那契数相加涉及再次计算第八个斐波那契数。您继续递归,直到达到第一个或第二个斐波那契数的基本情况,它们始终为 1。
递归斐波那契函数在这个fibonacciByRecursion.py Python 程序中:
def fibonacci(nthNumber):
print('fibonacci(%s) called.' % (nthNumber))
if nthNumber == 1 or nthNumber == 2: # ?
# BASE CASE
print('Call to fibonacci(%s) returning 1.' % (nthNumber))
return 1
else:
# RECURSIVE CASE
print('Calling fibonacci(%s) and fibonacci(%s).' % (nthNumber - 1, nthNumber - 2))
result = fibonacci(nthNumber - 1) + fibonacci(nthNumber - 2)
print('Call to fibonacci(%s) returning %s.' % (nthNumber, result))
return result
print(fibonacci(10))
这个fibonacciByRecursion.html文件包含了等效的 JavaScript 程序:
<script type="text/javascript">
function fibonacci(nthNumber) {
document.write('fibonacci(' + nthNumber + ') called.<br />');
if (nthNumber === 1 || nthNumber === 2) { // ?
// BASE CASE
document.write('Call to fibonacci(' + nthNumber + ') returning 1.<br />');
return 1;
}
else {
// RECURSIVE CASE
document.write('Calling fibonacci(' + (nthNumber - 1) + ') and fibonacci(' + (nthNumber - 2) + ').<br />');
let result = fibonacci(nthNumber - 1) + fibonacci(nthNumber - 2);
document.write('Call to fibonacci(' + nthNumber + ') returning ' + result + '.<br />');
return result;
}
}
document.write(fibonacci(10) + '<br />');
</script>
当您运行此代码来计算第 10 个斐波那契数时,输出如下:
fibonacci(10) called.
Calling fibonacci(9) and fibonacci(8).
fibonacci(9) called.
Calling fibonacci(8) and fibonacci(7).
fibonacci(8) called.
Calling fibonacci(7) and fibonacci(6).
fibonacci(7) called.
# --snip--
Call to fibonacci(6) returning 8.
Call to fibonacci(8) returning 21.
Call to fibonacci(10) returning 55.
55
大部分代码用于显示这个输出,但fibonacci()函数本身很简单。基本情况——不再进行递归调用的情况——发生在nthNumber为1或2时?。在这种情况下,函数返回1,因为第一个和第二个斐波那契数始终为 1。任何其他情况都是递归情况,因此返回的值是fibonacci(nthNumber - 1)和fibonacci(nthNumber - 2)的和。只要原始的nthNumber参数是大于0的整数,这些递归调用最终会达到基本情况并停止进行更多的递归调用。
还记得递归阶乘示例中的“递归调用之前”和“递归调用之后”部分吗?因为递归斐波那契算法在其递归情况中进行了两次递归调用,所以你应该记住它有三个部分:“第一个递归调用之前”,“第一个递归调用之后但第二个递归调用之前”,以及“第二个递归调用之后”。但相同的原则适用。不要认为因为达到了基本情况,递归调用之后就不再需要运行任何代码。只有在原始函数调用返回后,递归算法才算完成。
你可能会问:“迭代斐波那契解决方案是否比递归斐波那契解决方案更简单?”答案是“是的”。更糟糕的是,递归解决方案存在一个关键的低效性,下一节将对此进行解释。
为什么递归斐波那契算法很糟糕
与递归阶乘算法一样,递归斐波那契算法也存在一个关键的弱点:它一遍又一遍地重复相同的计算。图 2-3 显示了调用fibonacci(6)(在树形图中标记为fib(6)以简洁表示)时调用了fibonacci(5)和fibonacci(4)。
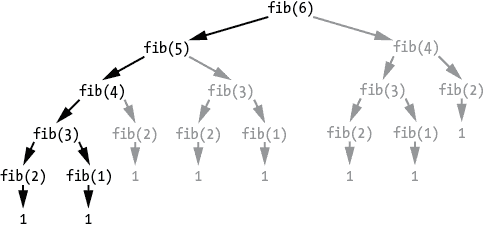
图 2-3:从fibonacci(6)开始进行的递归函数调用的树形图。冗余的函数调用以灰色显示。
这会引起其他函数调用的级联,直到它们达到fibonacci(2)和fibonacci(1)的基本情况,返回1。但请注意,fibonacci(4)被调用了两次,fibonacci(3)被调用了三次,依此类推。这会使整体算法变慢,因为存在不必要的重复计算。随着要计算的斐波那契数变得更大,这种低效性会变得更糟。虽然迭代斐波那契算法可以在不到一秒的时间内完成fibonacci(100),但递归算法需要超过一百万年才能完成。
将递归算法转换为迭代算法
将递归算法转换为迭代算法总是可能的。虽然递归函数通过调用自身重复计算,但这种重复可以通过循环来执行。递归函数还利用调用堆栈;然而,迭代算法可以用堆栈数据结构来替代。因此,任何递归算法都可以通过使用循环和堆栈来进行迭代执行。
为了证明这一点,这里有一个名为factorialEmulateRecursion.py的 Python 程序,它实现了一个迭代算法来模拟递归算法:
callStack = [] # The explicit call stack, which holds "frame objects". ?
callStack.append({'returnAddr': 'start', 'number': 5}) # "Call" the "factorial() function". ?
returnValue = None
while len(callStack) > 0:
# The body of the "factorial() function":
number = callStack[-1]['number'] # Set number parameter.
returnAddr = callStack[-1]['returnAddr']
if returnAddr == 'start':
if number == 1:
# BASE CASE
returnValue = 1
callStack.pop() # "Return" from "function call". ?
continue
else:
# RECURSIVE CASE
callStack[-1]['returnAddr'] = 'after recursive call'
# "Call" the "factorial() function":
callStack.append({'returnAddr': 'start', 'number': number - 1}) # ?
continue
elif returnAddr == 'after recursive call':
returnValue = number * returnValue
callStack.pop() # "Return from function call". ?
continue
print(returnValue)
factorialEmulateRecursion.html程序包含了等效的 JavaScript 代码:
<script type="text/javascript">
let callStack = []; // The explicit call stack, which holds "frame objects". // ?
callStack.push({"returnAddr": "start", "number": 5}); // "Call" the "factorial() function". // ?
let returnValue;
while (callStack.length > 0) {
// The body of the "factorial() function":
let number = callStack[callStack.length - 1]["number"]; // Set number parameter.
let returnAddr = callStack[callStack.length - 1]["returnAddr"];
if (returnAddr == "start") {
if (number === 1) {
// BASE CASE
returnValue = 1;
callStack.pop(); // "Return" from "function call". // ?
continue;
} else {
// RECURSIVE CASE
callStack[callStack.length - 1]["returnAddr"] = "after recursive call";
// "Call" the "factorial() function":
callStack.push({"returnAddr": "start", "number": number - 1}); // ?
continue;
}
} else if (returnAddr == "after recursive call") {
returnValue = number * returnValue;
callStack.pop(); // "Return from function call". // ?
continue;
}
}
document.write(returnValue + "<br />");
</script>
请注意,这个程序没有递归函数;它根本没有任何函数!该程序通过使用列表作为堆栈数据结构(存储在callStack变量中?)来模拟调用堆栈,从而模拟递归函数调用。存储返回地址信息和nthNumber本地变量的字典模拟了帧对象?。该程序通过将这些帧对象推送到调用堆栈?来模拟函数调用,并通过从调用堆栈中弹出帧对象 35 来模拟从函数调用返回。
任何递归函数都可以以这种方式被写成迭代的。虽然这段代码非常难以理解,你永远不会以这种方式编写一个真实的阶乘算法,但它确实证明了递归没有任何迭代代码没有的固有能力。
将迭代算法转换为递归算法
同样,将迭代算法转换为递归算法总是可能的。迭代算法只是使用循环的代码。重复执行的代码(循环的主体)可以放在递归函数的主体中。就像循环主体中的代码被重复执行一样,我们需要重复调用函数来执行它的代码。我们可以通过从函数本身调用函数来做到这一点,创建一个递归函数。
hello.py中的 Python 代码演示了通过使用循环打印Hello, world!五次,然后还使用递归函数:
Python
print('Code in a loop:')
i = 0
while i < 5:
print(i, 'Hello, world!')
i = i + 1
print('Code in a function:')
def hello(i=0):
print(i, 'Hello, world!')
i = i + 1
if i < 5:
hello(i) # RECURSIVE CASE
else:
return # BASE CASE
hello()
等价的 JavaScript 代码在hello.html中:
JavaScript
<script type="text/javascript">
document.write("Code in a loop:<br />");
let i = 0;
while (i < 5) {
document.write(i + " Hello, world!<br />");
i = i + 1;
}
document.write("Code in a function:<br />");
function hello(i) {
if (i === undefined) {
i = 0; // i defaults to 0 if unspecified.
}
document.write(i + " Hello, world!<br />");
i = i + 1;
if (i < 5) {
hello(i); // RECURSIVE CASE
}
else {
return; // BASE CASE
}
}
hello();
</script>
这些程序的输出如下:
Code in a loop:
0 Hello, world!
1 Hello, world!
2 Hello, world!
3 Hello, world!
4 Hello, world!
Code in a function:
0 Hello, world!
1 Hello, world!
2 Hello, world!
3 Hello, world!
4 Hello, world!
while循环有一个条件,i < 5,用于确定程序是否继续循环。同样,递归函数使用这个条件作为它的递归情况,这会导致函数调用自身并执行Hello, world!来再次显示它的代码。
对于一个更真实的例子,以下是迭代和递归函数,它们返回字符串haystack中子字符串needle的索引。如果没有找到子字符串,这些函数返回-1。这类似于 Python 的find()字符串方法和 JavaScript 的indexOf()字符串方法。这个findSubstring.py程序有一个 Python 版本:`
`Python
def findSubstringIterative(needle, haystack):
i = 0
while i < len(haystack):
if haystack[i:i + len(needle)] == needle:
return i # Needle found.
i = i + 1
return -1 # Needle not found.
def findSubstringRecursive(needle, haystack, i=0):
if i >= len(haystack):
return -1 # BASE CASE (Needle not found.)
if haystack[i:i + len(needle)] == needle:
return i # BASE CASE (Needle found.)
else:
# RECURSIVE CASE
return findSubstringRecursive(needle, haystack, i + 1)
print(findSubstringIterative('cat', 'My cat Zophie'))
print(findSubstringRecursive('cat', 'My cat Zophie'))
这个findSubstring.html程序有等价的 JavaScript 版本:
JavaScript
<script type="text/javascript">
function findSubstringIterative(needle, haystack) {
let i = 0;
while (i < haystack.length) {
if (haystack.substring(i, i + needle.length) == needle) {
return i; // Needle found.
}
i = i + 1
}
return -1; // Needle not found.
}
function findSubstringRecursive(needle, haystack, i) {
if (i === undefined) {
i = 0;
}
if (i >= haystack.length) {
return -1; // # BASE CASE (Needle not found.)
}
if (haystack.substring(i, i + needle.length) == needle) {
return i; // # BASE CASE (Needle found.)
} else {
// RECURSIVE CASE
return findSubstringRecursive(needle, haystack, i + 1);
}
}
document.write(findSubstringIterative("cat", "My cat Zophie") + "<br />");
document.write(findSubstringRecursive("cat", "My cat Zophie") + "<br />");
</script>
这些程序调用findSubstringIterative()和findSubstringRecursive(),它们返回3,因为这是在My cat Zophie中找到cat的索引:
3
3
本节中的程序表明,将任何循环转换为等价的递归函数总是可能的。虽然用递归替换循环是可能的,但我建议不要这样做。这是为了递归而递归,而且由于递归通常比迭代代码更难理解,代码的可读性会下降。
案例研究:计算指数
尽管递归不一定会产生更好的代码,但采用递归方法可以让你对编程问题有新的见解。作为一个案例研究,让我们来看看如何计算指数。
指数是通过将一个数字乘以自身来计算的。例如,指数“三的六次方”,或 3?,等于将 3 乘以自身六次:3 × 3 × 3 × 3 × 3 × 3 = 729。这是一个如此常见的操作,以至于 Python 有**运算符,JavaScript 有内置的Math.pow()函数来执行指数运算。我们可以用 Python 代码3 ** 6和 JavaScript 代码Math.pow(3, 6)来计算 3?。
但让我们编写我们自己的指数计算代码。解决方案很简单:创建一个循环,重复地将一个数字乘以自身,并返回最终的乘积。下面是一个迭代的exponentByIteration.py Python 程序:
Python
def exponentByIteration(a, n):
result = 1
for i in range(n):
result *= a
return result
print(exponentByIteration(3, 6))
print(exponentByIteration(10, 3))
print(exponentByIteration(17, 10))
这里是一个等价的 JavaScriptexponentByIteration.html程序:
JavaScript
<script type="text/javascript">
function exponentByIteration(a, n) {
let result = 1;
for (let i = 0; i < n; i++) {
result *= a;
}
return result;
}
document.write(exponentByIteration(3, 6) + "<br />");
document.write(exponentByIteration(10, 3) + "<br />");
document.write(exponentByIteration(17, 10) + "<br />");
</script>
当你运行这些程序时,输出如下:
729
1000
2015993900449
这是一个直接的计算,我们可以很容易地用循环来编写。使用循环的缺点是,随着指数变大,函数的速度变慢:计算 312需要的时间是 3?的两倍,而 3???需要的时间是 3?的一百倍。在下一节中,我们将通过递归来解决这个问题。
创建一个递归指数函数
让我们想一想,比如说,3?的指数的递归解决方案会是什么样的。由于乘法的结合性质,3 × 3 × 3 × 3 × 3 × 3 与(3 × 3 × 3) × (3 × 3 × 3)是相同的,这与(3 × 3 × 3)2是相同的。由于(3 × 3 × 3)与 33是相同的,我们可以确定 3?与(33)2是相同的。这是数学所称的幂规则的一个例子:(a(*m*))(n) = a(*mn*)。数学还给了我们*乘法规则*:*a*(n) × a^(m) = a^(n) ^(+ m),包括a^(n) × a = a^(n) ^(+ 1)。
我们可以使用这些数学规则来制作一个exponentByRecursion()函数。如果调用exponentByRecursion(3, 6),它与exponentByRecursion(3, 3) * exponentByRecursion(3, 3)是相同的。当然,我们实际上不必进行两次exponentByRecursion(3, 3)调用:我们可以将返回值保存到一个变量中,然后将其乘以自身。
这对于偶数次幂有效,但对于奇数次幂呢?如果我们必须计算 3?,或 3 × 3 × 3 × 3 × 3 × 3 × 3,这与(3 × 3 × 3 × 3 × 3 × 3) × 3 相同,或(3?) × 3。然后我们可以进行相同的递归调用来计算 3?。
这些是递归情况,但基本情况是什么?从数学上讲,任何数的零次幂被定义为 1,而任何数的一次幂就是这个数本身。因此,对于任何函数调用exponentByRecursion(a, n),如果n是0或1,我们可以简单地返回1或a,因为a``0总是1,而a``1总是a。
利用所有这些信息,我们可以为exponentByRecursion()函数编写代码。以下是带有 Python 代码的exponentByRecursion.py文件:
Python
def exponentByRecursion(a, n):
if n == 1:
# BASE CASE
return a
elif n % 2 == 0:
# RECURSIVE CASE (When n is even.)
result = exponentByRecursion(a, n // 2)
return result * result
elif n % 2 == 1:
# RECURSIVE CASE (When n is odd.)
result = exponentByRecursion(a, n // 2)
return result * result * a
print(exponentByRecursion(3, 6))
print(exponentByRecursion(10, 3))
print(exponentByRecursion(17, 10))
以下是exponentByRecursion.html中等效的 JavaScript 代码:
JavaScript
<script type="text/javascript">
function exponentByRecursion(a, n) {
if (n === 1) {
// BASE CASE
return a;
} else if (n % 2 === 0) {
// RECURSIVE CASE (When n is even.)
result = exponentByRecursion(a, n / 2);
return result * result;
} else if (n % 2 === 1) {
// RECURSIVE CASE (When n is odd.)
result = exponentByRecursion(a, Math.floor(n / 2));
return result * result * a;
}
}
document.write(exponentByRecursion(3, 6));
document.write(exponentByRecursion(10, 3));
document.write(exponentByRecursion(17, 10));
</script>
当运行此代码时,输出与迭代版本相同:
729
1000
2015993900449
每个递归调用实际上将问题规模减半。这就是使我们的递归指数算法比迭代版本更快的原因;迭代地计算 31???需要 1000 次乘法操作,而递归计算只需要 23 次乘法和除法。在性能分析器下运行 Python 代码时,迭代地计算 31???100,000 次需要 10.633 秒,但递归计算只需要 0.406 秒。这是一个巨大的改进!
基于递归洞察力创建一个迭代指数函数
我们最初的迭代指数函数采用了一种直接的方法:循环的次数与指数幂相同。然而,这对于更大的幂并不适用。我们的递归实现迫使我们考虑如何将这个问题分解为更小的子问题。这种方法事实证明更加高效。
因为每个递归算法都有一个等效的迭代算法,我们可以基于递归算法使用的幂规则创建一个新的迭代指数函数。以下exponentWithPowerRule.py程序有这样一个函数:
Python
def exponentWithPowerRule(a, n):
# Step 1: Determine the operations to be performed.
opStack = []
while n > 1:
if n % 2 == 0:
# n is even.
opStack.append('square')
n = n // 2
elif n % 2 == 1:
# n is odd.
n -= 1
opStack.append('multiply')
# Step 2: Perform the operations in reverse order.
result = a # Start result at `a`.
while opStack:
op = opStack.pop()
if op == 'multiply':
result *= a
elif op == 'square':
result *= result
return result
print(exponentWithPowerRule(3, 6))
print(exponentWithPowerRule(10, 3))
print(exponentWithPowerRule(17, 10))
以下是exponentWithPowerRule.html中等效的 JavaScript 程序:
JavaScript
<script type="text/javascript">
function exponentWithPowerRule(a, n) {
// Step 1: Determine the operations to be performed.
let opStack = [];
while (n > 1) {
if (n % 2 === 0) {
// n is even.
opStack.push("square");
n = Math.floor(n / 2);
} else if (n % 2 === 1) {
// n is odd.
n -= 1;
opStack.push("multiply");
}
}
// Step 2: Perform the operations in reverse order.
let result = a; // Start result at `a`.
while (opStack.length > 0) {
let op = opStack.pop();
if (op === "multiply") {
result = result * a;
} else if (op === "square") {
result = result * result;
}
}
return result;
}
document.write(exponentWithPowerRule(3, 6) + "<br />");
document.write(exponentWithPowerRule(10, 3) + "<br />");
document.write(exponentWithPowerRule(17, 10) + "<br />");
</script>
我们的算法通过将“n”减半(如果它是偶数)或减 1(如果它是奇数)来不断减少“n”,直到它变为“1”。这给了我们必须执行的平方或乘以“a”的操作。完成此步骤后,我们按相反的顺序执行这些操作。通用的堆栈数据结构(与调用堆栈分开)对于颠倒这些操作的顺序非常有用,因为它是一种先进后出的数据结构。第一步将平方或乘以“a”的操作推送到“opStack”变量中的堆栈。在第二步中,它在弹出堆栈时执行这些操作。
例如,调用“exponentWithPowerRule(6, 5)”来计算 6?,将“a”设置为“6”,将“n”设置为“5”。函数注意到“n”是奇数。这意味着我们应该从“n”中减去“1”得到“4”,并将一个乘以“a”的操作推送到“opStack”。现在“n”是“4”(偶数),我们将其除以“2”得到“2”,并将一个平方操作推送到“opStack”。由于“n”现在是“2”并且再次是偶数,我们将其除以“2”得到“1”,并将另一个平方操作推送到“opStack”。现在“n”是“1”,我们已经完成了这一步。
要执行第二步,我们将“result”开始为“a”(即“6”)。我们弹出 opStack 堆栈以获得一个平方操作,告诉程序将“result”设置为“result * result”(即“result”2)或“36”。我们弹出 opStack 的下一个操作,又是一个平方操作,所以程序将“result”中的“36”更改为“36 * 36”,或“1296”。我们弹出 opStack 的最后一个操作,它是一个乘以“a”的操作,所以我们将“result”中的“1296”乘以“a”(即“6”)得到“7776”。opStack 上没有更多的操作,所以函数现在已经完成。当我们再次检查我们的数学时,我们发现 6?确实是 7,776。
opStack 中的堆栈在函数调用“exponentWithPowerRule(6, 5)”执行时看起来像图 2-4。
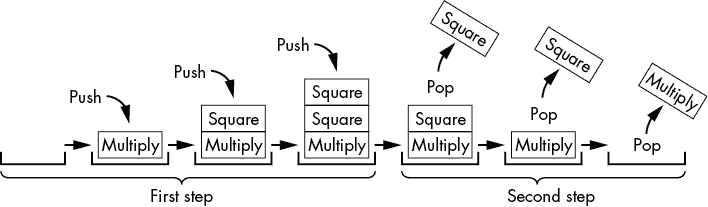
图 2-4:在函数调用“exponentWithPowerRule(6, 5)”期间 opStack 中的堆栈
当您运行此代码时,输出与其他指数程序相同:
729
1000
2015993900449
使用幂规则的迭代指数函数具有递归算法的改进性能,同时不会遭受堆栈溢出的风险。如果没有递归思维的见解,我们可能不会想到这种新的、改进的迭代算法。
何时需要使用递归?
您永远不需要使用递归。没有编程问题需要递归。本章已经表明,递归没有魔力可以做迭代代码和堆栈数据结构中的循环无法做的事情。实际上,递归函数可能是您尝试实现的内容的过于复杂的解决方案。
然而,正如我们在上一节中创建的指数函数所示,递归可以为我们如何思考编程问题提供新的见解。编程问题的三个特征,当存在时,使其特别适合递归方法:
-
它涉及树状结构。
-
它涉及回溯。
-
它并不是如此深度递归,以至于可能导致堆栈溢出。
树具有自相似结构:分叉点看起来类似于较小子树的根。递归通常涉及自相似性和可以分解为更小、相似子问题的问题。树的根类似于对递归函数的第一次调用,分叉点类似于递归情况,叶子类似于没有更多递归调用的基本情况。
迷宫也是一个具有树状结构并需要回溯的问题的很好例子。在迷宫中,分叉点出现在您必须选择许多路径中的一个时。如果您到达了死胡同,那么您已经遇到了基本情况。然后您必须回溯到先前的分叉点,选择一个不同的路径继续前进。
图 2-5 显示了一个迷宫的路径在视觉上形变成生物树的样子。尽管迷宫路径和树形路径在视觉上有所不同,但它们的分叉点在数学上是相关的。从数学上讲,这些图是等价的。
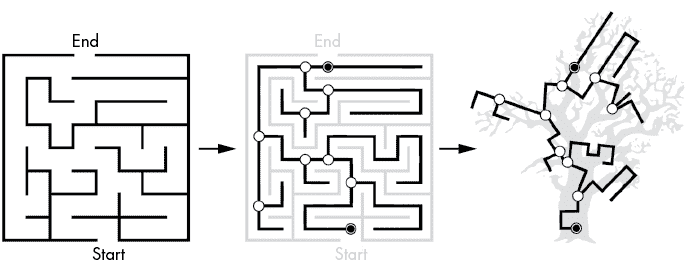
图 2-5:一个迷宫(左)以及其内部路径(中)形变成生物树的形状(右)
许多编程问题都具有这种树状结构。例如,文件系统具有树状结构;子文件夹看起来像较小文件系统的根文件夹。图 2-6 将文件系统与树进行了比较。
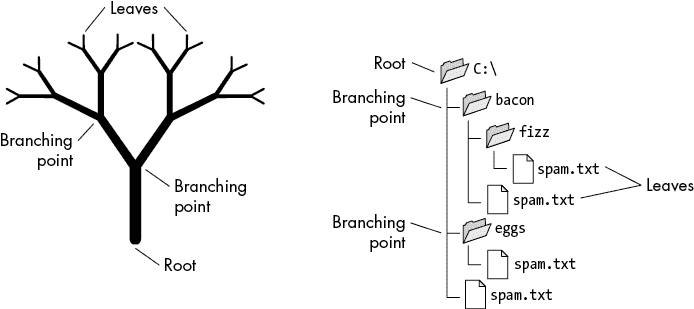
图 2-6:文件系统类似于树结构。
在文件夹中搜索特定文件名是一个递归问题:您搜索文件夹,然后递归搜索文件夹的子文件夹。没有子文件夹的文件夹是导致递归搜索停止的基本情况。如果您的递归算法找不到它正在寻找的文件名,它会回溯到先前的父文件夹,并从那里继续搜索。
第三点是实用性问题。如果您的树结构具有如此多层的分支,以至于递归函数在到达叶子之前就会导致堆栈溢出,那么递归就不是一个合适的解决方案。
另一方面,递归是创建编程语言编译器的最佳方法。编译器设计是一个庞大的课题,超出了本书的范围。但是编程语言有一组语法规则,可以将源代码分解成类似于语法规则可以将英语句子分解成树状图的树状结构。递归是应用于编译器的理想技术。
我们将在本书中识别许多递归算法,它们通常具有树状结构或回溯特性,非常适合递归。
提出递归算法
希望本章让您对递归函数与您可能更熟悉的迭代算法有了一个坚实的概念。本书的其余部分将深入探讨各种递归算法的细节。但是,您应该如何编写自己的递归函数呢?
第一步总是要确定递归情况和基本情况。您可以采用自顶向下的方法,将问题分解为与原始问题相似但更小的子问题;这就是您的递归情况。然后考虑子问题何时足够小以获得一个微不足道的答案;这就是您的基本情况。您的递归函数可能有多个递归情况或基本情况,但所有递归函数都至少有一个递归情况和至少一个基本情况。
递归斐波那契算法就是一个例子。斐波那契数是前两个斐波那契数的和。我们可以将查找斐波那契数的问题分解为查找两个较小斐波那契数的子问题。我们知道前两个斐波那契数都是 1,所以一旦子问题足够小,就可以得到基本情况的答案。
有时候,先采用自下而上的方法考虑基本情况,然后再看如何从中构建和解决更大的问题。递归阶乘问题就是一个例子。1 的阶乘是 1。这形成了基本情况。下一个阶乘是 2!,你可以通过将 1!乘以 2 来创建它。之后的阶乘,3!,是通过将 2!乘以 3 来创建的,依此类推。通过这种一般模式,我们可以找出我们算法的递归情况会是什么。
总结
在这一章中,我们涵盖了计算阶乘和斐波那契数列,这两个经典的递归编程问题。本章介绍了这些算法的迭代和递归实现。尽管它们是递归的经典示例,但它们的递归算法存在严重的缺陷。递归阶乘函数可能会导致堆栈溢出,而递归斐波那契函数执行了太多的冗余计算,以至于在现实世界中效率太低。
我们探讨了如何从迭代算法创建递归算法,以及如何从递归算法创建迭代算法。迭代算法使用循环,任何递归算法都可以通过使用循环和堆栈数据结构来进行迭代执行。递归通常是一个过于复杂的解决方案,但涉及树状结构和回溯的编程问题特别适合递归实现。
编写递归函数是一种随着练习和经验而提高的技能。本书的其余部分涵盖了几个众所周知的递归示例,并探讨了它们的优势和局限性。
进一步阅读
您可以在 Computerphile YouTube 频道的视频“Programming Loops vs. Recursion”中找到有关比较迭代和递归的更多信息,网址为youtu.be/HXNhEYqFo0o。如果您想比较迭代和递归函数的性能,您需要学习如何使用分析器。Python 分析器在我的书Beyond the Basic Stuff with Python(No Starch Press, 2020)的第十三章中有解释,可以在inventwithpython.com/beyond/chapter13.html上阅读。官方的 Python 文档也涵盖了分析器,网址为docs.python.org/3/library/profile.html。Mozilla 网站上解释了 JavaScript 的 Firefox 分析器,网址为developer.mozilla.org/en-US/docs/Tools/Performance。其他浏览器也有类似于 Firefox 的分析器。
练习问题
通过回答以下问题来测试您的理解:
-
4 的阶乘是多少?
-
你如何使用(n – 1)的阶乘来计算n的阶乘?
-
递归阶乘函数的关键弱点是什么?
-
斐波那契数列的前五个数字是什么?
-
为了得到第n个斐波那契数,你需要加上哪两个数字?
-
递归斐波那契函数的关键弱点是什么?
-
迭代算法总是使用什么?
-
总是可以将迭代算法转换为递归算法吗?
-
总是可以将递归算法转换为迭代算法吗?
-
任何递归算法都可以通过使用哪两种方法来进行迭代执行?
-
适合递归解决方案的编程问题具有哪三个特征?
-
何时需要递归来解决编程问题?
练习项目
练习时,为以下每个任务编写一个函数:
-
迭代计算从
1到n的整数序列的和。这类似于factorial()函数,只是它执行加法而不是乘法。例如,sumSeries(1)返回1,sumSeries(2)返回3(即1 + 2),sumSeries(3)返回6(即1 + 2 + 3),依此类推。这个函数应该使用循环而不是递归。可以参考本章的factorialByIteration.py程序。 -
编写
sumSeries()的递归形式。这个函数应该使用递归函数调用而不是循环。可以参考本章的factorialByRecursion.py程序。 -
在一个名为
sumPowersOf2()的函数中迭代计算前n个 2 的幂的和。2 的幂是 2、4、8、16、32 等等。在 Python 中,这些是通过2 ** 1、2 ** 2、2 ** 3、2 ** 4、2 ** 5等等计算的。在 JavaScript 中,这些是通过Math.pow(2, 1)、Math.pow(2, 2)等等计算的。例如,sumPowersOf2(1)返回2,sumPowersOf2(2)返回6(即2 + 4),sumPowersOf2(3)返回14(即2 + 4 + 8),依此类推。 -
编写
sumPowersOf2()的递归形式。这个函数应该使用递归函数调用而不是循环。
三、经典递归算法
原文:Chapter 3 - Classic Recursion Algorithms
译者:飞龙

如果你上了计算机科学课,递归单元肯定会涵盖本章介绍的一些经典算法。编码面试(由于缺乏合适的评估候选人的方法,通常抄袭大一计算机科学课程笔记)也可能涉及到它们。本章介绍了递归中的六个经典问题以及它们的解决方案。
我们首先介绍三个简单的算法:对数组中的数字求和、反转文本字符串以及检测字符串是否为回文。然后我们探讨解决汉诺塔难题的算法,实现泛洪填充绘图算法,并解决荒谬的递归 Ackermann 函数。
在这个过程中,你将学习到递归函数参数中的头尾技术。当尝试提出递归解决方案时,我们还会问自己三个问题:什么是基本情况?递归函数调用传递了什么参数?递归函数调用传递的参数如何接近基本情况?随着经验的增加,回答这些问题应该会更加自然。
对数组中的数字求和
我们的第一个例子很简单:给定一个整数列表(在 Python 中)或一个整数数组(在 JavaScript 中),返回所有整数的总和。例如,像sum([5, 2, 4, 8])这样的调用应该返回19。
这个问题用循环很容易解决,但用递归解决需要更多的思考。在阅读第二章之后,你可能也会注意到这个算法与递归的能力不够匹配,无法证明递归的复杂性。然而,在编码面试中,对数组中的数字求和(或者基于线性数据结构处理数据的其他计算)是一个常见的递归问题,值得我们关注。
为了解决这个问题,让我们来看看实现递归函数的头尾技术。这个技术将递归函数的数组参数分成两部分:头(数组的第一个元素)和尾(包括第一个元素之后的所有内容的新数组)。我们定义递归的sum()函数来通过将头部添加到尾部数组的总和来找到数组参数的整数的总和。为了找出尾部数组的总和,我们将其递归地作为数组参数传递给sum()。
因为尾部数组比原始数组参数少一个元素,所以我们最终将调用递归函数并传递一个空数组。空数组参数很容易求和,不需要更多的递归调用;它只是0。根据这些事实,我们对三个问题的答案如下:
-
什么是基本情况?一个空数组,其和为
0。 -
递归函数调用传递了什么参数?原始数字数组的尾部,比原始数组参数少一个数字。
-
这个参数如何变得更接近基本情况?数组参数每次递归调用都会减少一个元素,直到变成长度为零的空数组。
这是sumHeadTail.py,一个用于对数字列表求和的 Python 程序:
Python
def sum(numbers):
if len(numbers) == 0: # BASE CASE
return 0 # ?
else: # RECURSIVE CASE
head = numbers[0] # ?
tail = numbers[1:] # ?
return head + sum(tail) # ?
nums = [1, 2, 3, 4, 5]
print('The sum of', nums, 'is', sum(nums))
nums = [5, 2, 4, 8]
print('The sum of', nums, 'is', sum(nums))
nums = [1, 10, 100, 1000]
print('The sum of', nums, 'is', sum(nums))
这是等效的 JavaScript 程序sumHeadTail.html:
JavaScript
<script type="text/javascript">
function sum(numbers) {
if (numbers.length === 0) { // BASE CASE
return 0; // ?
} else { // RECURSIVE CASE
let head = numbers[0]; // ?
let tail = numbers.slice(1, numbers.length); // ?
return head + sum(tail); // ?
}
}
let nums = [1, 2, 3, 4, 5];
document.write('The sum of ' + nums + ' is ' + sum(nums) + "<br />");
nums = [5, 2, 4, 8];
document.write('The sum of ' + nums + ' is ' + sum(nums) + "<br />");
nums = [1, 10, 100, 1000];
document.write('The sum of ' + nums + ' is ' + sum(nums) + "<br />");
</script>
这些程序的输出如下所示:
The sum of [1, 2, 3, 4, 5] is 15
The sum of [5, 2, 4, 8] is 19
The sum of [1, 10, 100, 1000] is 1111
当使用空数组参数调用时,我们的函数的基本情况简单地返回0?。在递归情况中,我们从原始的numbers参数中形成头?和尾部?。请记住,tail的数据类型是一个数字数组,就像numbers参数一样。但是head的数据类型只是一个单一的数字值,而不是一个带有一个数字值的数组。sum()函数的返回值也是一个单一的数字值,而不是一个数字数组;这就是为什么我们可以在递归情况中将head和sum(tail)相加?。
每次递归调用都将一个越来越小的数组传递给sum(),使其更接近空数组的基本情况。例如,图 3-1 显示了对sum([5, 2, 4, 8])的调用堆栈的状态。
在这个图中,堆栈中的每张卡片代表一个函数调用。每张卡片的顶部是函数名和调用时传递的参数。其下是局部变量:numbers参数,以及在调用过程中创建的head和tail局部变量。卡片底部是函数调用返回的head + sum(tail)表达式。当创建一个新的递归函数时,一个新的卡片被推到堆栈上。当函数调用返回时,顶部的卡片从堆栈中弹出。
![一系列代表调用堆栈上的帧对象的卡片堆叠。依次,新的顶部卡片代表对 sum()传递[5, 2, 4, 8]的调用,然后传递[2, 4, 8],然后传递[4, 8],然后传递[8],然后传递一个空列表。然后顶部卡片被移除,首先移除空列表卡片,然后[8]卡片,然后[4, 8]卡片,然后[2, 4, 8]卡片,然后[5, 2, 4, 8]卡片。](https://img-blog.csdnimg.cn/img_convert/c126597a7dd5f2aebee75688c054eab6.png)
图 3-1:当运行sum([5, 2, 4, 8])时调用堆栈的状态
我们可以使用sum()函数作为应用头尾技术到其他递归函数的模板。例如,你可以将sum()函数从对数字数组求和的函数更改为concat()函数,用于将字符串数组连接在一起。基本情况将返回一个空字符串作为空数组参数,而递归情况将返回头字符串与传递尾部的递归调用的返回值连接在一起。
回想一下第二章,递归特别适用于涉及树状结构和回溯的问题。数组、字符串或其他线性数据结构可以被视为树状结构,尽管这是一个只有一个分支的树,就像图 3-2 中所示的那样。
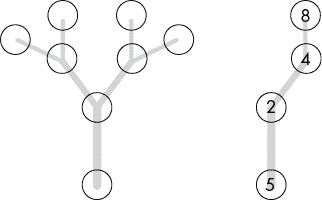
图 3-2:一个[5, 2, 4, 8]数组(右侧)就像一个只有一个分支的树状数据结构(左侧)。
我们的递归函数不必要的关键“告诉”是它从不在处理的数据上进行任何回溯。它对数组中的每个元素进行单次遍历,这是基本循环可以完成的事情。此外,Python 递归求和函数比直接迭代算法慢大约 100 倍。即使性能不是问题,递归sum()函数如果传递一个要求求和的数目为数万的列表会导致堆栈溢出。递归是一种高级技术,但并不总是最佳方法。
在第五章中,我们将研究使用分而治之策略的递归求和函数,在第八章中,我们将研究使用尾调用优化的递归函数。这些替代的递归方法解决了本章中求和函数的一些问题。
反转字符串
像对数组中的数字求和一样,反转字符串是另一个经常被引用的递归算法,尽管迭代解决方案很简单。因为字符串本质上是一个由单个字符组成的数组,所以我们将为我们的rev()函数采用头部和尾部的方法,就像我们为求和算法所做的那样。
让我们从可能的最小的字符串开始。一个空字符串和一个单字符字符串已经是它们自己的反转。这自然形成了我们的基本情况:如果字符串参数是''或′A′这样的字符串,我们的函数应该简单地返回字符串参数。
对于更长的字符串,让我们尝试将字符串分割成头部(仅为第一个字符)和尾部(第一个字符之后的所有字符)。对于一个两个字符的字符串,比如′XY′,′X′是头部,′Y′是尾部。要反转字符串,我们需要将头部放在尾部后面:′YX′。
这个算法对更长的字符串有效吗?要反转像′CAT′这样的字符串,我们会将它分成头部′C′和尾部′AT′。但仅仅将头部放在尾部后面并不能反转字符串;它给我们的是′ATC′。实际上,我们想要做的是将头部放在尾部的反转后面。换句话说,′AT′会反转成′TA′,然后将头部添加到末尾会产生反转后的字符串′TAC′。
我们如何反转尾部?嗯,我们可以递归调用rev()并将尾部传递给它。暂时忘记我们函数的实现,专注于它的输入和输出:rev()接受一个字符串参数,并返回一个将参数的字符反转的字符串。
考虑如何实现像rev()这样的递归函数可能很困难,因为它涉及到一个鸡和蛋的问题。为了编写rev()的递归情况,我们需要调用一个反转字符串的函数,也就是rev()。只要我们对我们的递归函数的参数和返回值有一个坚实的理解,我们就可以使用“信任飞跃”技术来解决这个鸡和蛋问题,即使我们还没有完成编写它。
在递归中进行信任飞跃并不是一个可以保证您的代码无错误的神奇技术。它只是一种观点,可以打破您在思考如何实现递归函数时可能遇到的心理程序员障碍。信任飞跃要求您对递归函数的参数和返回值有坚定的理解。
请注意,信任飞跃技术只有在编写递归情况时才有帮助。您必须将一个接近基本情况的参数传递给递归调用。您不能简单地传递递归函数接收到的相同参数,就像这样:
def rev(theString):
return rev(theString) # This won't magically work.
继续我们的′CAT′例子,当我们将尾部′AT′传递给rev()时,在那个函数调用中,头部是′A′,尾部是′T′。我们已经知道单个字符字符串的反转就是它自己;这是我们的基本情况。因此,对rev()的第二次调用将′AT′反转为′TA′,这正是之前对rev()的调用所需要的。图 3-3 显示了在所有对rev()的递归调用期间调用堆栈的状态。
让我们问rev()函数的三个递归算法问题:
-
基本情况是什么?零个或一个字符的字符串。
-
递归函数调用传递了什么参数?原始字符串参数的尾部,比原始字符串参数少一个字符。
-
这个参数如何变得更接近基本情况?每次递归调用时,数组参数都会减少一个元素,直到成为一个零长度的数组。
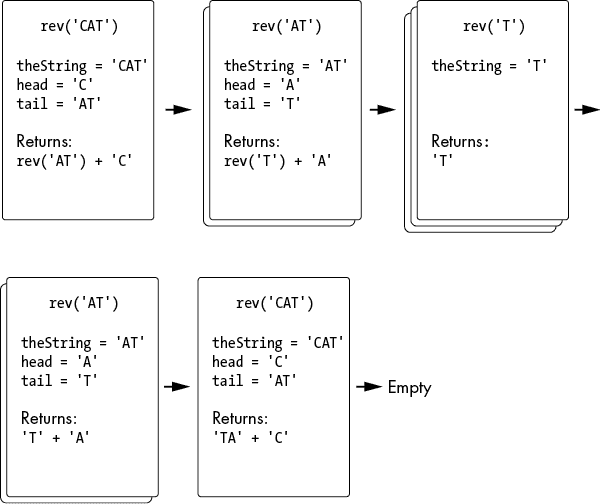
图 3-3:rev()函数反转CAT字符串时调用堆栈的状态
这是一个用于反转字符串的 Python 程序reverseString.py:
Python
def rev(theString):
if len(theString) == 0 or len(theString) == 1: # ?
# BASE CASE
return theString
else:
# RECURSIVE CASE
head = theString[0] # ?
tail = theString[1:] # ?
return rev(tail) + head # ?
print(rev('abcdef'))
print(rev('Hello, world!'))
print(rev(''))
print(rev('X'))
这是reverseString.html中等效的 JavaScript 代码:
JavaScript
<script type="text/javascript">
function rev(theString) {
if (theString.length === 0 || theString.length === 1) { // ?
// BASE CASE
return theString;
} else {
// RECURSIVE CASE
var head = theString[0]; // ?
var tail = theString.substring(1, theString.length); // ?
return rev(tail) + head; // ?
}
}
document.write(rev("abcdef") + "<br />");
document.write(rev("Hello, world!") + "<br />");
document.write(rev("") + "<br />");
document.write(rev("X") + "<br />");
</script>
这些程序的输出如下:
fedcba
!dlrow ,olleH
X
我们的递归函数rev()返回与参数theString相反的字符串。让我们考虑最简单的字符串进行反转:空字符串和单个字符字符串会“反转”成它们自己。这是我们将开始的两个基本情况(尽管我们将它们与or或||布尔运算符结合在一起)。对于递归情况,我们从theString中的第一个字符形成head,从第一个字符之后的每个字符形成tail。然后递归情况返回tail的反转,后跟head字符。
检测回文
回文是一个正向和反向拼写相同的单词或短语。Level、race car、taco cat和a man, a plan, a canal . . . Panama都是回文的例子。如果您想要检测一个字符串是否是回文,您可以编写一个递归的isPalindrome()函数。
基本情况是零个或一个字符的字符串,根据其性质,无论是正向还是反向,它总是相同的。我们将使用类似于头尾技术的方法,只是我们将把字符串参数分成头部、中间和尾部字符串。如果头部和尾部字符相同,并且中间字符也形成回文,那么字符串就是回文。递归来自将中间字符串传递给isPalindrome()。
让我们问isPalindrome()函数的三个递归算法问题:
-
基本情况是什么?零个或一个字符的字符串,它返回
True,因为它总是一个回文。 -
递归函数调用传递了什么参数?字符串参数的中间字符。
-
这个参数如何变得更接近基本情况?每次递归调用时,字符串参数都会减少两个字符,直到成为零个或一个字符的字符串。
这是一个用于检测回文的 Python 程序palindrome.py:
Python
def isPalindrome(theString):
if len(theString) == 0 or len(theString) == 1:
# BASE CASE
return True
else:
# RECURSIVE CASE
head = theString[0] # ?
middle = theString[1:-1] # ?
last = theString[-1] # ?
return head == last and isPalindrome(middle) # ?
text = 'racecar'
print(text + ' is a palindrome: ' + str(isPalindrome(text)))
text = 'amanaplanacanalpanama'
print(text + ' is a palindrome: ' + str(isPalindrome(text)))
text = 'tacocat'
print(text + ' is a palindrome: ' + str(isPalindrome(text)))
text = 'zophie'
print(text + ' is a palindrome: ' + str(isPalindrome(text)))
以下是palindrome.html中等效的 JavaScript 代码:
JavaScript
<script type="text/javascript">
function isPalindrome(theString) {
if (theString.length === 0 || theString.length === 1) {
// BASE CASE
return true;
} else {
// RECURSIVE CASE
var head = theString[0]; // ?
var middle = theString.substring(1, theString.length -1); // ?
var last = theString[theString.length - 1]; // ?
return head === last && isPalindrome(middle); // ?
}
}
text = "racecar";
document.write(text + " is a palindrome: " + isPalindrome(text) + "<br />");
text = "amanaplanacanalpanama";
document.write(text + " is a palindrome: " + isPalindrome(text) + "<br />");
text = "tacocat";
document.write(text + " is a palindrome: " + isPalindrome(text) + "<br />");
text = "zophie";
document.write(text + " is a palindrome: " + isPalindrome(text) + "<br />");
</script>
这些程序的输出如下:
racecar is a palindrome: True
amanaplanacanalpanama is a palindrome: True
tacocat is a palindrome: True
zophie is a palindrome: False
基本情况返回True,因为零个或一个字符的字符串总是回文。否则,字符串参数被分成三部分:第一个字符?,最后一个字符?,以及它们之间的中间字符?。
递归情况下的return语句?利用了布尔短路,这是几乎所有编程语言的特性。在使用and或&&布尔运算符连接的表达式中,如果左侧表达式为False,则右侧表达式是True还是False都无所谓,因为整个表达式都将是False。布尔短路是一种优化,如果左侧为False,则跳过and运算符的右侧表达式的评估。因此,在表达式head == last and isPalindrome(middle)中,如果head == last为False,则递归调用isPalindrome()将被跳过。这意味着一旦头部和尾部字符串不匹配,递归就会停止并简单地返回False。
这个递归算法仍然是顺序的,就像前面章节中的求和和反转字符串函数一样,只是不是从数据的开始到结束,而是从数据的两端向中间移动。使用简单循环的迭代版本更加直接。我们在本书中介绍递归版本,因为这是一个常见的编码面试问题。
解决汉诺塔
汉诺塔是一个涉及堆叠的塔的难题。难题以最大的圆盘在底部开始,圆盘尺寸逐渐减小。每个圆盘的中心都有一个孔,这样圆盘可以在杆上相互堆叠。图 3-4 显示了一个木制的汉诺塔难题。

图 3-4:木制汉诺塔难题套装
要解决这个难题,玩家必须遵循三条规则将圆盘从一根杆移动到另一根杆:
-
玩家一次只能移动一个圆盘。
-
玩家只能将圆盘移动到塔的顶部或从塔的顶部移动。
-
玩家永远不能将较大的圆盘放在较小的圆盘上。
Python 的内置turtledemo模块有一个汉诺塔演示,您可以通过在 Windows 上运行python -m turtledemo或在 macOS/Linux 上运行python3 -m turtledemo,然后从示例菜单中选择minimum_hanoi来查看。汉诺塔动画也可以通过互联网搜索轻松找到。
解决汉诺塔难题的递归算法并不直观。让我们从最小的情况开始:一个只有一个圆盘的汉诺塔。解决方案很简单:将圆盘移动到另一个杆上,然后完成。解决两个圆盘的情况稍微复杂一些:将较小的圆盘移动到一个杆上(我们称之为临时杆),将较大的圆盘移动到另一个杆上(我们称之为结束杆),最后将较小的圆盘从临时杆移动到结束杆。现在两个圆盘按正确顺序放在结束杆上。
一旦解决了三个圆盘的塔,你会发现出现了一个模式。要解决从起始杆到结束杆的n个圆盘的塔,必须执行以下操作:
-
通过将这些圆盘从起始杆移动到临时杆来解决n - 1 个圆盘的难题。
-
将第n个圆盘从起始杆移动到结束杆。
-
通过将这些圆盘从临时杆移动到结束杆来解决n - 1 个圆盘的难题。
就像斐波那契算法一样,汉诺塔算法的递归情况不是只做一次递归调用,而是做两次。如果我们画出一个解决四个盘子汉诺塔问题的操作的树形图,它看起来像图 3-6。解决四个盘子的难题需要与解决三个盘子的难题相同的步骤,以及移动第四个盘子和再次执行解决三个盘子难题的步骤。同样,解决三个盘子的难题需要与解决两个盘子的难题相同的步骤,再加上移动第三个盘子,依此类推。解决一个盘子的难题是微不足道的基本情况:它只涉及移动盘子。
图 3-5 中的树状结构暗示了递归方法对于解决汉诺塔难题是理想的。在这棵树中,执行从上到下,从左到右移动。
虽然对于人类来说,解决三个盘子或四个盘子的汉诺塔很容易,但是盘子数量的增加需要指数级增加的操作次数才能完成。对于n个盘子,至少需要 2n - 1 次移动才能解决。这意味着 31 个盘子的塔需要超过十亿次移动才能完成!
图 3-5:解决四个盘子汉诺塔的一系列操作
让我们为创建递归解决方案提出三个问题:
-
基本情况是什么?解决一个盘子的塔。
-
传递给递归函数调用的参数是什么?解决一个比当前大小小一个盘子的塔。
-
这个参数如何变得更接近基本情况?要解决的塔的大小每递归调用一次减少一个盘子,直到它是一个只有一个盘子的塔。
以下的towerOfHanoiSolver.py程序解决了汉诺塔难题,并显示了每一步的可视化:
import sys
# Set up towers A, B, and C. The end of the list is the top of the tower.
TOTAL_DISKS = 6 ?
# Populate Tower A:
TOWERS = {'A': list(reversed(range(1, TOTAL_DISKS + 1))), ?
'B': [],
'C': []}
def printDisk(diskNum):
# Print a single disk of width diskNum.
emptySpace = ' ' * (TOTAL_DISKS - diskNum)
if diskNum == 0:
# Just draw the pole.
sys.stdout.write(emptySpace + '||' + emptySpace)
else:
# Draw the disk.
diskSpace = '@' * diskNum
diskNumLabel = str(diskNum).rjust(2, '_')
sys.stdout.write(emptySpace + diskSpace + diskNumLabel + diskSpace + emptySpace)
def printTowers():
# Print all three towers.
for level in range(TOTAL_DISKS, -1, -1):
for tower in (TOWERS['A'], TOWERS['B'], TOWERS['C']):
if level >= len(tower):
printDisk(0)
else:
printDisk(tower[level])
sys.stdout.write('\n')
# Print the tower labels A, B, and C.
emptySpace = ' ' * (TOTAL_DISKS)
print('%s A%s%s B%s%s C\n' % (emptySpace, emptySpace, emptySpace, emptySpace, emptySpace))
def moveOneDisk(startTower, endTower):
# Move the top disk from startTower to endTower.
disk = TOWERS[startTower].pop()
TOWERS[endTower].append(disk)
def solve(numberOfDisks, startTower, endTower, tempTower):
# Move the top numberOfDisks disks from startTower to endTower.
if numberOfDisks == 1:
# BASE CASE
moveOneDisk(startTower, endTower) ?
printTowers()
return
else:
# RECURSIVE CASE
solve(numberOfDisks - 1, startTower, tempTower, endTower) ?
moveOneDisk(startTower, endTower) ?
printTowers()
solve(numberOfDisks - 1, tempTower, endTower, startTower) ?
return
# Solve:
printTowers()
solve(TOTAL_DISKS, 'A', 'B', 'C')
# Uncomment to enable interactive mode:
#while True:
# printTowers()
# print('Enter letter of start tower and the end tower. (A, B, C) Or Q to quit.')
# move = input().upper()
# if move == 'Q':
# sys.exit()
# elif move[0] in 'ABC' and move[1] in 'ABC' and move[0] != move[1]:
# moveOneDisk(move[0], move[1])
这个towerOfHanoiSolver.html程序包含了等效的 JavaScript 代码:
<script type="text/javascript">
// Set up towers A, B, and C. The end of the array is the top of the tower.
var TOTAL_DISKS = 6; // ?
var TOWERS = {"A": [], // ?
"B": [],
"C": []};
// Populate Tower A:
for (var i = TOTAL_DISKS; i > 0; i--) {
TOWERS["A"].push(i);
}
function printDisk(diskNum) {
// Print a single disk of width diskNum.
var emptySpace = " ".repeat(TOTAL_DISKS - diskNum);
if (diskNum === 0) {
// Just draw the pole.
document.write(emptySpace + "||" + emptySpace);
} else {
// Draw the disk.
var diskSpace = "@".repeat(diskNum);
var diskNumLabel = String("___" + diskNum).slice(-2);
document.write(emptySpace + diskSpace + diskNumLabel + diskSpace + emptySpace);
}
}
function printTowers() {
// Print all three towers.
var towerLetters = "ABC";
for (var level = TOTAL_DISKS; level >= 0; level--) {
for (var towerLetterIndex = 0; towerLetterIndex < 3; towerLetterIndex++) {
var tower = TOWERS[towerLetters[towerLetterIndex]];
if (level >= tower.length) {
printDisk(0);
} else {
printDisk(tower[level]);
}
}
document.write("<br />");
}
// Print the tower labels A, B, and C.
var emptySpace = " ".repeat(TOTAL_DISKS);
document.write(emptySpace + " A" + emptySpace + emptySpace +
" B" + emptySpace + emptySpace + " C<br /><br />");
}
function moveOneDisk(startTower, endTower) {
// Move the top disk from startTower to endTower.
var disk = TOWERS[startTower].pop();
TOWERS[endTower].push(disk);
}
function solve(numberOfDisks, startTower, endTower, tempTower) {
// Move the top numberOfDisks disks from startTower to endTower.
if (numberOfDisks == 1) {
// BASE CASE
moveOneDisk(startTower, endTower); ?
printTowers();
return;
} else {
// RECURSIVE CASE
solve(numberOfDisks - 1, startTower, tempTower, endTower); ?
moveOneDisk(startTower, endTower); ?
printTowers();
solve(numberOfDisks - 1, tempTower, endTower, startTower); ?
return;
}
}
// Solve:
document.write("<pre>");
printTowers();
solve(TOTAL_DISKS, "A", "B", "C");
document.write("</pre>");
</script>
当您运行此代码时,输出显示了每个盘子的移动,直到整个塔从 A 塔移动到 B 塔为止:
|| || ||
@_1@ || ||
@@_2@@ || ||
@@@_3@@@ || ||
@@@@_4@@@@ || ||
@@@@@_5@@@@@ || ||
@@@@@@_6@@@@@@ || ||
A B C
|| || ||
|| || ||
@@_2@@ || ||
@@@_3@@@ || ||
@@@@_4@@@@ || ||
@@@@@_5@@@@@ || ||
@@@@@@_6@@@@@@ || @_1@
A B C
--snip--
|| || ||
|| || ||
|| || ||
|| || ||
|| @@_2@@ ||
@_1@ @@@_3@@@ ||
@@@@@@_6@@@@@@ @@@@_4@@@@ @@@@@_5@@@@@
--snip--
A B C
|| || ||
|| @_1@ ||
|| @@_2@@ ||
|| @@@_3@@@ ||
|| @@@@_4@@@@ ||
|| @@@@@_5@@@@@ ||
|| @@@@@@_6@@@@@@ ||
A B C
Python 版本也有交互模式,您可以在towerOfHanoiSolver.py的末尾取消注释代码行以玩交互版本。
您可以通过将程序顶部的TOTAL_DISKS常量?设置为1或2来从较小的情况开始运行程序。在我们的程序中,Python 中的整数列表和 JavaScript 中的整数数组表示一个柱子。整数表示一个盘子,较大的整数表示较大的盘子。列表或数组的起始整数在柱子的底部,结束整数在柱子的顶部。例如,[6, 5, 4, 3, 2, 1]表示具有六个盘子的起始柱子,最大的盘子在底部,而[]表示没有盘子的柱子。TOWERS变量包含这三个列表?。
基本情况只是将最小的盘子从起始柱移动到结束柱?。n个盘子的递归情况执行三个步骤:解决n - 1 的情况?,移动第n个盘子?,然后再次解决n - 1 的情况?。
使用泛洪填充
图形程序通常使用泛洪填充算法来填充任意形状的相同颜色区域为另一种颜色。图 3-6 显示了左上角的一个这样的形状。随后的面板显示了用灰色填充的形状的三个不同部分。泛洪填充从一个白色像素开始,一直扩散,直到遇到非白色像素,填充封闭空间。
泛洪填充算法是递归的:它从将单个像素更改为新颜色开始。然后在具有相同旧颜色的像素的任何邻居上调用递归函数。然后移动到邻居的邻居,依此类推,将每个像素转换为新颜色,直到填充封闭空间。
基本情况是像素的颜色是图像的边缘,或者不是旧颜色。由于达到基本情况是停止图像中每个像素的递归调用“传播”的唯一方法,因此该算法具有将所有连续像素从旧颜色更改为新颜色的紧急行为。
让我们问一下关于floodFill()函数的三个递归算法问题:
-
什么是基本情况?当 x 和 y 坐标是不是旧颜色的像素,或者在图像的边缘时。
-
递归函数调用传递了哪些参数?当前像素的四个相邻像素的 x 和 y 坐标是四个递归调用的参数。
-
这些参数如何接近基本情况?相邻像素的颜色与旧颜色或图像边缘不同。无论哪种情况,最终算法都会用完要检查的像素。
图 3-6:图形编辑器中的原始形状(左上角)和填充了三个不同区域的相同形状,颜色为浅灰色
我们的示例程序不是图像,而是使用单字符字符串列表来形成文本字符的 2D 网格,以表示“图像”。每个字符串代表一个“像素”,特定字符代表“颜色”。floodfill.py Python 程序实现了泛洪填充算法、图像数据和一个在屏幕上打印图像的函数:
Python
import sys
# Create the image (make sure it's rectangular!)
im = [list('..########################...........'), # ?
list('..#......................#...#####...'),
list('..#..........########....#####...#...'),
list('..#..........#......#............#...'),
list('..#..........########.........####...'),
list('..######......................#......'),
list('.......#..#####.....###########......'),
list('.......####...#######................')]
HEIGHT = len(im)
WIDTH = len(im[0])
def floodFill(image, x, y, newChar, oldChar=None):
if oldChar == None:
# oldChar defaults to the character at x, y.
oldChar = image[y][x] # ?
if oldChar == newChar or image[y][x] != oldChar:
# BASE CASE
return
image[y][x] = newChar # Change the character.
# Uncomment to view each step:
#printImage(image)
# Change the neighboring characters.
if y + 1 < HEIGHT and image[y + 1][x] == oldChar:
# RECURSIVE CASE
floodFill(image, x, y + 1, newChar, oldChar) # ?
if y - 1 >= 0 and image[y - 1][x] == oldChar:
# RECURSIVE CASE
floodFill(image, x, y - 1, newChar, oldChar) # ?
if x + 1 < WIDTH and image[y][x + 1] == oldChar:
# RECURSIVE CASE
floodFill(image, x + 1, y, newChar, oldChar) # ?
if x - 1 >= 0 and image[y][x - 1] == oldChar:
# RECURSIVE CASE
floodFill(image, x - 1, y, newChar, oldChar) # ?
return # BASE CASE # ?
def printImage(image):
for y in range(HEIGHT):
# Print each row.
for x in range(WIDTH):
# Print each column.
sys.stdout.write(image[y][x])
sys.stdout.write('\n')
sys.stdout.write('\n')
printImage(im)
floodFill(im, 3, 3, 'o')
printImage(im)
floodfill.html程序包含了等效的 JavaScript 代码:
JavaScript
<script type="text/javascript">
// Create the image (make sure it's rectangular!)
var im = ["..########################...........".split(""), // ?
"..#......................#...#####...".split(""),
"..#..........########....#####...#...".split(""),
"..#..........#......#............#...".split(""),
"..#..........########.........####...".split(""),
"..######......................#......".split(""),
".......#..#####.....###########......".split(""),
".......####...#######................".split("")];
var HEIGHT = im.length;
var WIDTH = im[0].length;
function floodFill(image, x, y, newChar, oldChar) {
if (oldChar === undefined) {
// oldChar defaults to the character at x, y.
oldChar = image[y][x]; // ?
}
if ((oldChar == newChar) || (image[y][x] != oldChar)) {
// BASE CASE
return;
}
image[y][x] = newChar; // Change the character.
// Uncomment to view each step:
//printImage(image);
// Change the neighboring characters.
if ((y + 1 < HEIGHT) && (image[y + 1][x] == oldChar)) {
// RECURSIVE CASE
floodFill(image, x, y + 1, newChar, oldChar); // ?
}
if ((y - 1 >= 0) && (image[y - 1][x] == oldChar)) {
// RECURSIVE CASE
floodFill(image, x, y - 1, newChar, oldChar); // ?
}
if ((x + 1 < WIDTH) && (image[y][x + 1] == oldChar)) {
// RECURSIVE CASE
floodFill(image, x + 1, y, newChar, oldChar); // ?
}
if ((x - 1 >= 0) && (image[y][x - 1] == oldChar)) {
// RECURSIVE CASE
floodFill(image, x - 1, y, newChar, oldChar); // ?
}
return; // BASE CASE # ?
}
function printImage(image) {
document.write("<pre>");
for (var y = 0; y < HEIGHT; y++) {
// Print each row.
for (var x = 0; x < WIDTH; x++) {
// Print each column.
document.write(image[y][x]);
}
document.write("\n");
}
document.write("\n</ pre>");
}
printImage(im);
floodFill(im, 3, 3, "o");
printImage(im);
</script>
当运行此代码时,程序从坐标 3,3 开始填充由#字符绘制的形状的内部。它用o字符替换所有句号字符(.)。以下输出显示了之前和之后的图像:
..########################...........
..#......................#...#####...
..#..........########....#####...#...
..#..........#......#............#...
..#..........########.........####...
..######......................#......
.......#..#####.....###########......
.......####...#######................
..########################...........
..#oooooooooooooooooooooo#...#####...
..#oooooooooo########oooo#####ooo#...
..#oooooooooo#......#oooooooooooo#...
..#oooooooooo########ooooooooo####...
..######oooooooooooooooooooooo#......
.......#oo#####ooooo###########......
.......####...#######................
如果要查看泛洪填充算法在填充新字符时的每一步,请取消注释floodFill()函数中的printImage(image)行?,然后再次运行程序。
图像由一个字符串字符的 2D 数组表示。我们可以将这个image数据结构、一个x坐标和一个y坐标以及一个新字符传递给floodFill()函数。函数会注意当前在x和y坐标处的字符,并将其保存到oldChar变量中?。
如果image中坐标x和y处的当前字符与oldChar不同,这是我们的基本情况,函数就简单地返回。否则,函数继续进行四个递归情况:传递当前坐标的底部?、顶部?、右侧?和左侧?邻居的 x 和 y 坐标。在进行了这四个潜在的递归调用之后,函数的结尾是一个隐式的基本情况,在我们的程序中通过return语句?明确表示。
泛洪填充算法不一定要是递归的。对于大图像,递归函数可能会导致堆栈溢出。如果我们使用循环和堆栈来实现泛洪填充,堆栈将以起始像素的 x 和 y 坐标开始。循环中的代码将弹出堆栈顶部的坐标,如果该坐标的像素与oldChar匹配,它将推送四个相邻像素的坐标。当堆栈为空时,因为基本情况不再将邻居推送到堆栈中,循环就结束了。
然而,泛洪填充算法不一定要使用堆栈。先进后出堆栈的推送和弹出对于回溯行为是有效的,但在泛洪填充算法中处理像素的顺序可以是任意的。这意味着我们同样可以有效地使用一个随机删除元素的集合数据结构。你可以在nostarch.com/recursive-book-recursion的可下载资源中找到这些迭代泛洪填充算法的实现,分别是 floodFillIterative.py 和 floodFillIterative.html。
使用 Ackermann 函数
Ackermann 函数 是以其发现者威廉·阿克曼命名的。数学家大卫·希尔伯特的学生(我们在第九章讨论的希尔伯特曲线分形),阿克曼于 1928 年发表了他的函数。数学家罗莎·彼得和拉斐尔·罗宾逊后来开发了本节中所介绍的函数的版本。
虽然 Ackermann 函数在高等数学中有一些应用,但它主要以高度递归函数的例子而闻名。即使是对其两个整数参数的轻微增加也会导致其递归调用次数大幅增加。
Ackermann 函数接受两个参数 m 和 n,并且当 m 为 0 时有一个基本情况,返回 n + 1。有两种递归情况:当 n 为 0 时,函数返回 ackermann(m - 1, 1),当 n 大于 0 时,函数返回 ackermann(m - 1, ackermann(m, n - 1))。这些情况可能对你来说没有意义,但可以说,Ackermann 函数的递归调用次数增长得很快。调用 ackermann(1, 1) 会导致三次递归函数调用。调用 ackermann(2, 3) 会导致 43 次递归函数调用。调用 ackermann(3, 5) 会导致 42,437 次递归函数调用。调用 ackermann(5, 7) 会导致… 好吧,实际上我不知道有多少次递归函数调用,因为这将需要计算几倍于宇宙年龄的时间。
让我们回答构建递归算法时提出的三个问题:
-
什么是基本情况?当
m为0时。 -
递归函数调用传递了什么参数?下一个
m参数传递了要么m要么m - 1;下一个n参数传递了1、n - 1或ackermann(m, n - 1)的返回值。 -
这些参数如何接近基本情况?
m参数总是要么减小,要么保持相同的大小,所以它最终会达到0。
以下是一个 ackermann.py Python 程序:
def ackermann(m, n, indentation=None):
if indentation is None:
indentation = 0
print('%sackermann(%s, %s)' % (' ' * indentation, m, n))
if m == 0:
# BASE CASE
return n + 1
elif m > 0 and n == 0:
# RECURSIVE CASE
return ackermann(m - 1, 1, indentation + 1)
elif m > 0 and n > 0:
# RECURSIVE CASE
return ackermann(m - 1, ackermann(m, n - 1, indentation + 1), indentation + 1)
print('Starting with m = 1, n = 1:')
print(ackermann(1, 1))
print('Starting with m = 2, n = 3:')
print(ackermann(2, 3))
以下是等效的 ackermann.html JavaScript 程序:
<script type="text/javascript">
function ackermann(m, n, indentation) {
if (indentation === undefined) {
indentation = 0;
}
document.write(" ".repeat(indentation) + "ackermann(" + m + ", " + n + ")\n");
if (m === 0) {
// BASE CASE
return n + 1;
} else if ((m > 0) && (n === 0)) {
// RECURSIVE CASE
return ackermann(m - 1, 1, indentation + 1);
} else if ((m > 0) && (n > 0)) {
// RECURSIVE CASE
return ackermann(m - 1, ackermann(m, n - 1, indentation + 1), indentation + 1);
}
}
document.write("<pre>");
document.write("Starting with m = 1, n = 1:<br />");
document.write(ackermann(1, 1) + "<br />");
document.write("Starting with m = 2, n = 3:<br />");
document.write(ackermann(2, 3) + "<br />");
document.write("</pre>");
</script>
当你运行这段代码时,输出的缩进(由 indentation 参数设置)告诉你给定递归函数调用在调用堆栈上的深度:
Starting with m = 1, n = 1:
ackermann(1, 1)
ackermann(1, 0)
ackermann(0, 1)
ackermann(0, 2)
3
Starting with m = 2, n = 3:
ackermann(2, 3)
ackermann(2, 2)
ackermann(2, 1)
ackermann(2, 0)
--snip--
ackermann(0, 6)
ackermann(0, 7)
ackermann(0, 8)
9
你也可以尝试 ackermann(3, 3),但任何更大的参数可能需要太长时间来计算。为了加快计算速度,尝试注释掉除了打印 ackermann() 的最终返回值之外的所有 print() 和 document.write() 调用。
请记住,即使像 Ackermann 函数这样的递归算法也可以作为迭代函数实现。迭代 Ackermann 算法在nostarch.com/recursive-book-recursion的可下载资源中实现为 ackermannIterative.py 和 ackermannIterative.html。
摘要
本章涵盖了一些经典的递归算法。对于每一个,我们都提出了三个重要的问题,你在设计自己的递归函数时应该总是问的:什么是基本情况?递归函数调用传递了什么参数?这些参数如何接近基本情况?如果它们没有,你的函数将继续递归,直到导致堆栈溢出。
求和、字符串反转和回文检测递归函数都可以很容易地用简单的循环实现。关键的线索是它们都只对给定的数据进行一次遍历,没有回溯。正如第二章所解释的,递归算法特别适用于涉及类似树状结构并需要回溯的问题。
解决汉诺塔难题的树状结构表明它涉及回溯,因为程序执行从树的顶部到底部,从左到右运行。这使得它成为递归的一个主要候选者,特别是因为解决方案需要对较小的塔进行两次递归调用。
洪水填充算法直接适用于图形和绘图程序,以及检测连续区域形状的其他算法。如果你在图形程序中使用了油漆桶工具,你可能使用了洪水填充算法的一个版本。
阿克曼函数是递归函数在输入增加时增长速度之快的一个很好的例子。虽然它在日常编程中没有太多实际应用,但没有讨论递归的讨论是不完整的。但是,就像所有递归函数一样,它可以用循环和栈来实现。
进一步阅读
维基百科上有更多关于汉诺塔问题的信息,网址为en.wikipedia.org/wiki/Tower_of_Hanoi,而 Computerphile 的视频“Recursion ‘Super Power’ (in Python)”则介绍了如何在 Python 中解决汉诺塔问题,网址为youtu.be/8lhxIOAfDss。3Blue1Brown 的两部视频系列“Binary, Hanoi, and Sierpiński”通过探索汉诺塔、二进制数和谢尔宾斯基三角形分形之间的关系,提供了更详细的信息,网址为youtu.be/2SUvWfNJSsM。
维基百科上有一个关于洪水填充算法在小图像上运行的动画,网址为en.wikipedia.org/wiki/Flood_fill。
Computerphile 的视频“The Most Difficult Program to Compute?”讨论了阿克曼函数,网址为youtu.be/i7sm9dzFtEI。如果你想了解更多关于阿克曼函数在可计算性理论中的地位,Hackers in Cambridge 频道有一个关于原始递归和部分递归函数的五部视频系列,网址为youtu.be/yaDQrOUK-KY。该系列需要观众进行大量的数学思考,但你不需要太多的先前数学知识。
练习问题
通过回答以下问题来测试你的理解:
-
数组或字符串的头部是什么?
-
数组或字符串的尾部是什么?
-
本章对每个递归算法提出了哪三个问题?
-
递归中的信任飞跃是什么?
-
你在进行递归函数编写之前需要了解什么才能做出信任的飞跃?
-
线性数据结构(如数组或字符串)如何类似于树状结构?
-
递归的
sum()函数是否涉及对其处理的数据的回溯? -
在洪水填充程序中,尝试更改
im变量的字符串,创建一个未完全封闭的C形状。当你尝试从C的中间进行洪水填充时会发生什么? -
回答本章中每个递归算法的三个问题:
-
基本情况是什么?
-
递归函数调用传递了什么参数?
-
这个论点如何接近基本情况?
然后重新创建本章的递归算法,而不查看原始代码。
实践项目
为以下每个任务编写一个函数:
-
使用头尾技术,创建一个递归的
concat()函数,该函数接受一个字符串数组,并将这些字符串连接成一个字符串返回。例如,concat(['Hello', 'World'])应返回HelloWorld。 -
使用头尾技术,创建一个递归的
product()函数,该函数接受一个整数数组,并返回它们的总乘积。这段代码几乎与本章中的sum()函数相同。但是,请注意,只有一个整数的数组的基本情况返回整数,空数组的基本情况返回1。 -
使用泛洪填充算法,计算二维网格中的“房间”或封闭空间的数量。您可以通过创建嵌套的
for循环,在网格中的每个字符上调用泛洪填充函数(如果是句点),以将句点更改为井字符。例如,以下数据将导致程序在网格中找到六个句点的位置,这意味着有五个房间(以及所有房间之外的空间)。
...##########....................................
...#........#....####..................##########
...#........#....#..#...############...#........#
...##########....#..#...#..........#...##.......#
.......#....#....####...#..........#....##......#
.......#....#....#......############.....##.....#
.......######....#........................##....#
.................####........####..........######
四、回溯和树遍历算法
原文:Chapter 4 - Backtracking and Tree Traversal Algorithms
译者:飞龙

在前几章中,您已经了解到递归特别适用于涉及树状结构和回溯的问题,例如解迷宫算法。要了解原因,请考虑树干分成多个分支。这些分支本身又分成其他分支。换句话说,树具有递归的、自相似的形状。
迷宫可以用树数据结构表示,因为迷宫分支成不同的路径,这些路径又分成更多的路径。当您到达迷宫的死胡同时,必须回溯到较早的分叉点。
遍历树图的任务与许多递归算法紧密相关,例如本章中的解迷宫算法和第十一章中的迷宫生成程序。我们将研究树遍历算法,并使用它们来在树数据结构中查找特定名称。我们还将使用树遍历算法来获取树中最深的节点的算法。最后,我们将看到迷宫可以表示为树数据结构,并使用树遍历和回溯来找到从迷宫起点到出口的路径。
使用树遍历
如果您在 Python 和 JavaScript 中编程,通常会使用列表、数组和字典数据结构。只有在处理特定计算机科学算法的低级细节时,才会遇到树数据结构,例如抽象语法树、优先队列、Adelson-Velsky-Landis(AVL)树等概念,超出了本书的范围。但是,树本身是非常简单的概念。
树 数据结构是由节点组成的数据结构,这些节点通过边连接到其他节点。节点包含数据,而边表示与另一个节点的关系。节点也称为顶点。树的起始节点称为根,末端的节点称为叶子。树始终只有一个根。
顶部的父节点与它们下面的零个或多个子节点之间有边。因此,叶子是没有子节点的节点,父节点是非叶节点,子节点是所有非根节点。树中的节点可以有多个子节点。将子节点连接到根节点的父节点也称为子节点的祖先。父节点和叶节点之间的子节点称为父节点的后代。树中的父节点可以有多个子节点。但是,除了根节点外,每个子节点都只有一个父节点。在树中,任何两个节点之间只能存在一条路径。
图 4-1 显示了一棵树的示例,以及三个不是树的结构示例。
四个图。第一个标有“树”的图有一个 A 节点,有两个子节点 B 和 C;B 有一个子节点 D;C 有两个子节点 E 和 F;E 有两个子节点 G 和 H。第二个图标有“不是树(子节点有多个父节点)”,有一个 A 节点,有两个子节点 B 和 C;B 有两个子节点 D 和 E;C 有两个子节点 E 和 F;E 有两个子节点 G 和 H。第三个图标有“不是树(子节点循环到祖先节点)”,有一个 A 节点,有两个子节点 B 和 C;B 有一个子节点 D;C 有两个子节点 E 和 F;D 有一个子节点 A;E 有两个子节点 G 和 H。第四个图标有“不是树(多个根节点)”,有两个根节点 Z 和 A;Z 有一个子节点 B;A 有两个子节点 B 和 C;B 有一个子节点 D;C 有两个子节点 E 和 F;E 有两个子节点 G 和 H。
图 4-1:一棵树(左)和三个非树的示例
正如你所看到的,子节点必须有一个父节点,不能有创建循环的边,否则该结构将不再被视为树。我们在本章中涵盖的递归算法仅适用于树数据结构。
Python 和 JavaScript 中的树形数据结构
树形数据结构通常向下生长,根在顶部。图 4-2 显示了使用以下 Python 代码(也是有效的 JavaScript 代码)创建的树:
root = {'data': 'A', 'children': []}
node2 = {'data': 'B', 'children': []}
node3 = {'data': 'C', 'children': []}
node4 = {'data': 'D', 'children': []}
node5 = {'data': 'E', 'children': []}
node6 = {'data': 'F', 'children': []}
node7 = {'data': 'G', 'children': []}
node8 = {'data': 'H', 'children': []}
root['children'] = [node2, node3]
node2['children'] = [node4]
node3['children'] = [node5, node6]
node5['children'] = [node7, node8]
树形图和节点的先序、后序和中序遍历顺序。树的根节点是 A,有两个子节点 B 和 C。B 有一个子节点 D。C 有两个子节点 E 和 F,E 有两个子节点 G 和 H。先序遍历:A,B,D,C,E,G,H,F。后序遍历:D,B,G,H,E,F,C,A。中序遍历:D,B,A,G,E,H,C,F。
图 4-2:根为A,叶为D,G,H和F的树,以及其遍历顺序
树中的每个节点包含一段数据(从A到H的字母字符串)和其子节点的列表。图 4-2 中的先序、后序和中序信息将在后续章节中解释。
在这棵树的代码中,每个节点由一个 Python 字典(或 JavaScript 对象)表示,其中键data存储节点的数据,键children有其他节点的列表。我使用root和node2到node8变量来存储每个节点,并使代码更易读,但这不是必需的。以下 Python/JavaScript 代码等同于前面的代码清单,尽管对人类来说更难阅读:
root = {'data': 'A', 'children': [{'data': 'B', 'children':
[{'data': 'D', 'children': []}]}, {'data': 'C', 'children':
[{'data': 'E', 'children': [{'data': 'G', 'children': []},
{'data': 'H', 'children': []}]}, {'data': 'F', 'children': []}]}]}
图 4-2 中的树是一种特定类型的数据结构,称为有向无环图(DAG)。在数学和计算机科学中,图是节点和边的集合,树是图的一种。图是有向的,因为其边有一个方向:从父节点到子节点。DAG 中的边不是无向的,即双向的。(一般树没有这个限制,可以有双向的边,包括从子节点返回到父节点。)图是无环的,因为没有从子节点到其祖先节点的循环,或循环;树的“分支”必须保持在同一方向上不断增长。
您可以将列表、数组和字符串视为线性树;根是第一个元素,节点只有一个子节点。这种线性树在其一个叶节点处终止。这些线性树称为链表,因为每个节点只有一个“下一个”节点,直到列表的末尾。图 4-3 显示了存储单词HELLO中字符的链表。
线性树图有五个节点。根节点“H”有一个子节点“E”,它有一个子节点“L”,它有一个子节点“L”,它有一个子节点“O”。
图 4-3:存储HELLO的链表数据结构。链表可以被认为是一种树数据结构。
我们将使用图 4-2 中的树代码作为本章的示例。树遍历算法将通过跟随边访问树中的每个节点,从根节点开始。
遍历树
我们可以编写代码从root中的根节点开始访问任何节点的数据。例如,在将树代码输入 Python 或 JavaScript 交互式 shell 后,运行以下命令:
>>> root['children'][1]['data']
'C'
>>> root['children'][1]['children'][0]['data']
'E'
我们的树遍历代码可以写成一个递归函数,因为树数据结构具有自相似的结构:父节点有子节点,每个子节点都是其自己子节点的父节点。树遍历算法确保您的程序可以访问或修改树中每个节点的数据,无论其形状或大小如何。
让我们针对树遍历代码提出三个关于递归算法的问题:
-
什么是基本情况?叶节点,它没有更多的子节点,也不需要更多的递归调用,导致算法回溯到先前的父节点。
-
传递给递归函数调用的参数是什么?要遍历的节点,其子节点将是下一个要遍历的节点。
-
这个参数如何变得更接近基本情况?DAG 中没有循环,因此遵循后代节点将始终最终到达叶节点。
请记住,特别深的树数据结构会导致堆栈溢出,因为算法遍历更深的节点。这是因为每个更深入树的层级都需要另一个函数调用,太多的函数调用而没有返回会导致堆栈溢出。然而,广泛、平衡良好的树不太可能会那么深。如果 1000 级深的树中的每个节点都有两个子节点,那么树将有大约 21???个节点。这比宇宙中的原子还多,而且您的树数据结构不太可能那么大。
树有三种树遍历算法:先序、后序和中序。我们将在接下来的三个部分讨论每一个。
先序树遍历
先序树遍历算法在遍历子节点之前访问节点的数据。如果您的算法需要在访问子节点的数据之前访问父节点的数据,则使用先序遍历。例如,在创建树数据结构的副本时使用先序遍历,因为您需要在副本树中创建子节点之前创建父节点。
以下的preorderTraversal.py程序有一个preorderTraverse()函数,它在访问节点数据之前首先遍历每个子节点,然后将其打印到屏幕上:
Python
root = {'data': 'A', 'children': [{'data': 'B', 'children':
[{'data': 'D', 'children': []}]}, {'data': 'C', 'children':
[{'data': 'E', 'children': [{'data': 'G', 'children': []},
{'data': 'H', 'children': []}]}, {'data': 'F', 'children': []}]}]}
def preorderTraverse(node):
print(node['data'], end=' ') # Access this node's data.
if len(node['children']) > 0: # ?
# RECURSIVE CASE
for child in node['children']:
preorderTraverse(child) # Traverse child nodes.
# BASE CASE
return # ?
preorderTraverse(root)
等效的 JavaScript 程序在preorderTraversal.html中:
JavaScript
<script type="text/javascript">
root = {"data": "A", "children": [{"data": "B", "children":
[{"data": "D", "children": []}]}, {"data": "C", "children":
[{"data": "E", "children": [{"data": "G", "children": []},
{"data": "H", "children": []}]}, {"data": "F", "children": []}]}]};
function preorderTraverse(node) {
document.write(node["data"] + " "); // Access this node's data.
if (node["children"].length > 0) { // ?
// RECURSIVE CASE
for (let i = 0; i < node["children"].length; i++) {
preorderTraverse(node["children"][i]); // Traverse child nodes.
}
}
// BASE CASE
return; // ?
}
preorderTraverse(root);
</script>
这些程序的输出是按照先序顺序的节点数据:
A B D C E G H F
当您查看图 4-1 中的树时,请注意先序遍历顺序在显示右节点之前显示左节点,并且在显示顶部节点之前显示底部节点。
所有树遍历都是通过将根节点传递给递归函数开始的。该函数进行递归调用,并将每个根节点的子节点作为参数传递。由于这些子节点有自己的子节点,遍历将继续直到到达没有子节点的叶节点。在这一点上,函数调用简单地返回。
如果节点有任何子节点?,则递归情况发生,在这种情况下,将使用每个子节点作为节点参数进行递归调用。无论节点是否有子节点,基本情况始终发生在函数结束时返回?。
后序树遍历
后序树遍历在访问节点数据之前遍历节点的子节点。例如,在删除树并确保不通过首先删除其父节点而使子节点“孤立”来访问根节点的情况下使用此遍历。以下 postorderTraversal.py 程序中的代码类似于前一节中的先序遍历代码,只是递归函数调用在 print()调用之前。
Python
root = {'data': 'A', 'children': [{'data': 'B', 'children':
[{'data': 'D', 'children': []}]}, {'data': 'C', 'children':
[{'data': 'E', 'children': [{'data': 'G', 'children': []},
{'data': 'H', 'children': []}]}, {'data': 'F', 'children': []}]}]}
def postorderTraverse(node):
for child in node['children']:
# RECURSIVE CASE
postorderTraverse(child) # Traverse child nodes.
print(node['data'], end=' ') # Access this node's data.
# BASE CASE
return
postorderTraverse(root)
postorderTraversal.html 程序包含等效的 JavaScript 代码:
JavaScript
<script type="text/javascript">
root = {"data": "A", "children": [{"data": "B", "children":
[{"data": "D", "children": []}]}, {"data": "C", "children":
[{"data": "E", "children": [{"data": "G", "children": []},
{"data": "H", "children": []}]}, {"data": "F", "children": []}]}]};
function postorderTraverse(node) {
for (let i = 0; i < node["children"].length; i++) {
// RECURSIVE CASE
postorderTraverse(node["children"][i]); // Traverse child nodes.
}
document.write(node["data"] + " "); // Access this node's data.
// BASE CASE
return;
}
postorderTraverse(root);
</script>
这些程序的输出是节点数据按后序顺序排列:
D B G H E F C A
节点的后序遍历顺序显示左节点的数据在右节点之前,底部节点在顶部节点之前。当我们比较 postorderTraverse()和 preorderTraverse()函数时,我们发现名称有点不准确:pre 和 post 不是指节点被访问的顺序。节点总是以相同的顺序遍历;我们首先遍历子节点(称为深度优先搜索),而不是在深入之前访问每个级别的节点(称为广度优先搜索)。pre 和 post 指的是节点的数据何时被访问:在遍历节点的子节点之前或之后。
中序树遍历
二叉树是最多有两个子节点的树数据结构,通常称为左子节点和右子节点。中序树遍历遍历左子节点,然后访问节点数据,然后遍历右子节点。这种遍历在处理二叉搜索树的算法中使用(这超出了本书的范围)。inorderTraversal.py 程序包含执行这种遍历的 Python 代码:
Python
root = {'data': 'A', 'children': [{'data': 'B', 'children':
[{'data': 'D', 'children': []}]}, {'data': 'C', 'children':
[{'data': 'E', 'children': [{'data': 'G', 'children': []},
{'data': 'H', 'children': []}]}, {'data': 'F', 'children': []}]}]}
def inorderTraverse(node):
if len(node['children']) >= 1:
# RECURSIVE CASE
inorderTraverse(node['children'][0]) # Traverse the left child.
print(node['data'], end=' ') # Access this node's data.
if len(node['children']) >= 2:
# RECURSIVE CASE
inorderTraverse(node['children'][1]) # Traverse the right child.
# BASE CASE
return
inorderTraverse(root)
inorderTraversal.html 程序包含等效的 JavaScript 代码:
JavaScript
<script type="text/javascript">
root = {"data": "A", "children": [{"data": "B", "children":
[{"data": "D", "children": []}]}, {"data": "C", "children":
[{"data": "E", "children": [{"data": "G", "children": []},
{"data": "H", "children": []}]}, {"data": "F", "children": []}]}]};
function inorderTraverse(node) {
if (node["children"].length >= 1) {
// RECURSIVE CASE
inorderTraverse(node["children"][0]); // Traverse the left child.
}
document.write(node["data"] + " "); // Access this node's data.
if (node["children"].length >= 2) {
// RECURSIVE CASE
inorderTraverse(node["children"][1]); // Traverse the right child.
}
// BASE CASE
return;
}
inorderTraverse(root);
</script>
这些程序的输出如下:
D B A G E H C F
中序遍历通常指的是二叉树的遍历,尽管在遍历第一个节点之后和遍历最后一个节点之前处理节点数据将计为任何大小的树的中序遍历。
在树中查找八个字母的名称
我们可以使用深度优先搜索来查找树数据结构中的特定数据,而不是在遍历它们时打印出每个节点中的数据。我们将编写一个算法,用于在图 4-4 中搜索具有确切八个字母的名称的树。这是一个相当牵强的例子,但它展示了算法如何使用树遍历从树数据结构中检索数据。
图 4-4:存储在我们的 depthFirstSearch.py 和 depthFirstSearch.html 程序中的名称的树
让我们对我们的树遍历代码的递归算法提出三个问题。它们的答案类似于树遍历算法的答案:
-
基本情况是什么?要么是叶节点导致算法回溯,要么是包含八个字母名称的节点。
-
递归函数调用传递了什么参数?要遍历到的节点,其子节点将是下一个要遍历的节点。
-
这个参数如何接近基本情况?DAG 中没有循环,因此遵循后代节点将始终最终到达叶节点。
深度优先搜索.py 程序包含执行先序遍历的 Python 代码:
Python
root = {'name': 'Alice', 'children': [{'name': 'Bob', 'children':
[{'name': 'Darya', 'children': []}]}, {'name': 'Caroline',
'children': [{'name': 'Eve', 'children': [{'name': 'Gonzalo',
'children': []}, {'name': 'Hadassah', 'children': []}]}, {'name': 'Fred', 'children': []}]}]}
def find8LetterName(node):
print(' Visiting node ' + node['name'] + '...')
# Preorder depth-first search:
print('Checking if ' + node['name'] + ' is 8 letters...')
if len(node['name']) == 8: return node['name'] # BASE CASE # ?
if len(node['children']) > 0:
# RECURSIVE CASE
for child in node['children']:
returnValue = find8LetterName(child)
if returnValue != None:
return returnValue
# Postorder depth-first search:
#print('Checking if ' + node['name'] + ' is 8 letters...')
#if len(node['name']) == 8: return node['name'] # BASE CASE # ?
# Value was not found or there are no children.
return None # BASE CASE
print('Found an 8-letter name: ' + str(find8LetterName(root)))
depthFirstSearch.html 程序包含等效的 JavaScript 程序:
JavaScript
<script type="text/javascript">
root = {'name': 'Alice', 'children': [{'name': 'Bob', 'children':
[{'name': 'Darya', 'children': []}]}, {'name': 'Caroline',
'children': [{'name': 'Eve', 'children': [{'name': 'Gonzalo',
'children': []}, {'name': 'Hadassah', 'children': []}]}, {'name': 'Fred', 'children': []}]}]};
function find8LetterName(node, value) {
document.write("Visiting node " + node.name + "...<br />");
// Preorder depth-first search:
document.write("Checking if " + node.name + " is 8 letters...<br />");
if (node.name.length === 8) return node.name; // BASE CASE // ?
if (node.children.length > 0) {
// RECURSIVE CASE
for (let child of node.children) {
let returnValue = find8LetterName(child);
if (returnValue != null) {
return returnValue;
}
}
}
// Postorder depth-first search:
document.write("Checking if " + node.name + " is 8 letters...<br />");
//if (node.name.length === 8) return node.name; // BASE CASE // ?
// Value was not found or there are no children.
return null; // BASE CASE
}
document.write("Found an 8-letter name: " + find8LetterName(root));
</script>
这些程序的输出如下:
Visiting node Alice...
Checking if Alice is 8 letters...
Visiting node Bob...
Checking if Bob is 8 letters...
Visiting node Darya...
Checking if Darya is 8 letters...
Visiting node Caroline...
Checking if Caroline is 8 letters...
Found an 8-letter name: Caroline
find8LetterName()函数的操作方式与我们先前的树遍历函数相同,只是不打印节点的数据,而是检查节点中存储的名称,并返回它找到的第一个八个字母的名称。您可以通过注释掉先前的名称长度比较和Checking if行?,并取消注释后面的名称长度比较和Checking if行?,将先序遍历更改为后序遍历。当您进行此更改时,函数找到的第一个八个字母的名称是Hadassah:
Visiting node Alice...
Visiting node Bob...
Visiting node Darya...
Checking if Darya is 8 letters...
Checking if Bob is 8 letters...
Visiting node Caroline...
Visiting node Eve...
Visiting node Gonzalo...
Checking if Gonzalo is 8 letters...
Visiting node Hadassah...
Checking if Hadassah is 8 letters...
Found an 8-letter name: Hadassah
虽然两种遍历顺序都可以正确找到一个八个字母的名称,但更改树遍历的顺序可能会改变程序的行为。
获取最大树深度
算法可以通过递归询问其子节点有多深来确定树中最深的分支。节点的深度是它与根节点之间的边的数量。根节点本身的深度为 0,根节点的直接子节点的深度为 1,依此类推。您可能需要这些信息作为更大算法的一部分,或者为了收集关于树数据结构的一般大小的信息。
我们可以有一个名为getDepth()的函数,以一个节点作为参数,并返回其最深子节点的深度。叶节点(基本情况)只返回0。
例如,给定图 4-1 中树的根节点,我们可以调用getDepth()并将其传递给根节点(A节点)。这将返回其子节点B和C节点的深度,再加一。函数必须递归调用getDepth()来获取这些信息。最终,A节点将在C上调用getDepth(),它将在E上调用它。当E用其两个子节点G和H调用getDepth()时,它们都返回0,因此在E上调用getDepth()返回1,使得在C上调用getDepth()返回2,并使在A(根节点)上调用getDepth()返回3。我们树的最大深度为三级。
让我们为getDepth()函数提出三个递归算法问题:
-
什么是基本情况?没有子节点的叶节点,其本质上具有一级深度。
-
递归函数调用传递了什么参数?我们想要找到最大深度的节点。
-
这个参数如何变得更接近基本情况?DAG 没有循环,因此跟随后代节点最终会到达一个叶节点。
以下getDepth.py程序包含了一个递归的getDepth()函数,返回树中最深节点包含的级数:
Python
root = {'data': 'A', 'children': [{'data': 'B', 'children':
[{'data': 'D', 'children': []}]}, {'data': 'C', 'children':
[{'data': 'E', 'children': [{'data': 'G', 'children': []},
{'data': 'H', 'children': []}]}, {'data': 'F', 'children': []}]}]}
def getDepth(node):
if len(node['children']) == 0:
# BASE CASE
return 0
else:
# RECURSIVE CASE
maxChildDepth = 0
for child in node['children']:
# Find the depth of each child node:
childDepth = getDepth(child)
if childDepth > maxChildDepth:
# This child is deepest child node found so far:
maxChildDepth = childDepth
return maxChildDepth + 1
print('Depth of tree is ' + str(getDepth(root)))
getDepth.html程序包含了 JavaScript 等效代码:
JavaScript
<script type="text/javascript">
root = {"data": "A", "children": [{"data": "B", "children":
[{"data": "D", "children": []}]}, {"data": "C", "children":
[{"data": "E", "children": [{"data": "G", "children": []},
{"data": "H", "children": []}]}, {"data": "F", "children": []}]}]};
function getDepth(node) {
if (node.children.length === 0) {
// BASE CASE
return 0;
} else {
// RECURSIVE CASE
let maxChildDepth = 0;
for (let child of node.children) {
// Find the depth of each child node:
let childDepth = getDepth(child);
if (childDepth > maxChildDepth) {
// This child is deepest child node found so far:
maxChildDepth = childDepth;
}
}
return maxChildDepth + 1;
}
}
document.write("Depth of tree is " + getDepth(root) + "<br />");
</script>
这些程序的输出如下:
Depth of tree is 3
这与我们在图 4-2 中看到的相匹配:从根节点A到最低节点G和H的级数是三级。
解决迷宫
虽然迷宫的形状和大小各不相同,简单连通迷宫,也称为完美迷宫,不包含循环。完美迷宫在任何两点之间都有且仅有一条路径,例如开始和出口。这些迷宫可以用 DAG 表示。
例如,图 4-5 显示了我们的迷宫程序解决的迷宫,图 4-6 显示了其 DAG 形式。大写的S标记着迷宫的开始,大写的E标记着出口。迷宫中标有小写字母的一些交叉点对应于 DAG 中的节点。
图 4-5:本章中我们的迷宫程序解决的迷宫。一些交叉点有小写字母,对应于图 4-6 中的节点。

图 4-6:在迷宫的 DAG 表示中,节点表示交叉点,边表示从交叉点到北、南、东或西的路径。一些节点具有小写字母,以对应图 4-5 中的交叉点。
由于这种结构上的相似性,我们可以使用树遍历算法来解决迷宫。这个树图中的节点表示迷宫解算器可以选择要遵循到下一个交叉点的北、南、东或西路径之一。根节点是迷宫的起点,叶节点表示死胡同。
递归情况发生在树遍历算法从一个节点移动到下一个节点时。如果树遍历到达叶节点(迷宫中的死胡同),算法已经达到了一个基本情况,并且必须回溯到较早的节点并跟随不同的路径。一旦算法到达出口节点,它从根节点到出口节点的路径代表了迷宫的解决方案。让我们问我们的三个递归算法关于解迷宫算法的问题:
-
什么是基本情况?到达死胡同或迷宫的出口。
-
递归函数调用传递了什么参数?x,y 坐标,迷宫数据以及已经访问过的 x,y 坐标的列表。
-
这个参数如何变得更接近基本情况?像泛洪填充算法一样,x,y 坐标不断移动到相邻的坐标,直到最终到达死胡同或最终出口。
这个mazeSolver.py程序包含了 Python 代码,用于解决存储在MAZE变量中的迷宫:
Python
# Create the maze data structure:
# You can copy-paste this from inventwithpython.com/examplemaze.txt
MAZE = """
#######################################################################
#S# # # # # # # # # #
# ##### ######### # ### ### # # # # ### # # ##### # ### # # ##### # ###
# # # # # # # # # # # # # # # # # # # #
# # # ##### # ########### ### # ##### ##### ######### # # ##### ### # #
# # # # # # # # # # # # # # # # #
######### # # # ##### # ### # ########### ####### # # ##### ##### ### #
# # # # # # # # # # # # # # # # # #
# # ##### # # ### # # ####### # # # # # # # ##### ### ### ######### # #
# # # # # # # # # # # # # # # # # # #
### # # # # ### # # ##### ####### ########### # ### # ##### ##### ### #
# # # # # # # # # # # # # # # # #
# ### ####### ##### ### ### ####### ##### # ######### ### ### ##### ###
# # # # # # # # # # # # # # # # #
### ########### # ####### ####### ### # ##### # # ##### # # ### # ### #
# # # # # # # # # # # # # # # # # #
# ### # # ####### # ### ##### # ####### ### ### # # ####### # # # ### #
# # # # # # # # # E#
#######################################################################
""".split('\n')
# Constants used in this program:
EMPTY = ' '
START = 'S'
EXIT = 'E'
PATH = '.'
# Get the height and width of the maze:
HEIGHT = len(MAZE)
WIDTH = 0
for row in MAZE: # Set WIDTH to the widest row's width.
if len(row) > WIDTH:
WIDTH = len(row)
# Make each row in the maze a list as wide as the WIDTH:
for i in range(len(MAZE)):
MAZE[i] = list(MAZE[i])
if len(MAZE[i]) != WIDTH:
MAZE[i] = [EMPTY] * WIDTH # Make this a blank row.
def printMaze(maze):
for y in range(HEIGHT):
# Print each row.
for x in range(WIDTH):
# Print each column in this row.
print(maze[y][x], end='')
print() # Print a newline at the end of the row.
print()
def findStart(maze):
for x in range(WIDTH):
for y in range(HEIGHT):
if maze[y][x] == START:
return (x, y) # Return the starting coordinates.
def solveMaze(maze, x=None, y=None, visited=None):
if x == None or y == None:
x, y = findStart(maze)
maze[y][x] = EMPTY # Get rid of the 'S' from the maze.
if visited == None:
visited = [] # Create a new list of visited points. # ?
if maze[y][x] == EXIT:
return True # Found the exit, return True.
maze[y][x] = PATH # Mark the path in the maze.
visited.append(str(x) + ',' + str(y)) # ?
#printMaze(maze) # Uncomment to view each forward step. # ?
# Explore the north neighboring point:
if y + 1 < HEIGHT and maze[y + 1][x] in (EMPTY, EXIT) and \
str(x) + ',' + str(y + 1) not in visited:
# RECURSIVE CASE
if solveMaze(maze, x, y + 1, visited):
return True # BASE CASE
# Explore the south neighboring point:
if y - 1 >= 0 and maze[y - 1][x] in (EMPTY, EXIT) and \
str(x) + ',' + str(y - 1) not in visited:
# RECURSIVE CASE
if solveMaze(maze, x, y - 1, visited):
return True # BASE CASE
# Explore the east neighboring point:
if x + 1 < WIDTH and maze[y][x + 1] in (EMPTY, EXIT) and \
str(x + 1) + ',' + str(y) not in visited:
# RECURSIVE CASE
if solveMaze(maze, x + 1, y, visited):
return True # BASE CASE
# Explore the west neighboring point:
if x - 1 >= 0 and maze[y][x - 1] in (EMPTY, EXIT) and \
str(x - 1) + ',' + str(y) not in visited:
# RECURSIVE CASE
if solveMaze(maze, x - 1, y, visited):
return True # BASE CASE
maze[y][x] = EMPTY # Reset the empty space.
#printMaze(maze) # Uncomment to view each backtrack step. # ?
return False # BASE CASE
printMaze(MAZE)
solveMaze(MAZE)
printMaze(MAZE)
mazeSolver.html程序包含了 JavaScript 等效代码:
JavaScript
<script type="text/javascript">
// Create the maze data structure:
// You can copy-paste this from inventwithpython.com/examplemaze.txt
let MAZE = `
#######################################################################
#S# # # # # # # # # #
# ##### ######### # ### ### # # # # ### # # ##### # ### # # ##### # ###
# # # # # # # # # # # # # # # # # # # #
# # # ##### # ########### ### # ##### ##### ######### # # ##### ### # #
# # # # # # # # # # # # # # # # #
######### # # # ##### # ### # ########### ####### # # ##### ##### ### #
# # # # # # # # # # # # # # # # # #
# # ##### # # ### # # ####### # # # # # # # ##### ### ### ######### # #
# # # # # # # # # # # # # # # # # # #
### # # # # ### # # ##### ####### ########### # ### # ##### ##### ### #
# # # # # # # # # # # # # # # # #
# ### ####### ##### ### ### ####### ##### # ######### ### ### ##### ###
# # # # # # # # # # # # # # # # #
### ########### # ####### ####### ### # ##### # # ##### # # ### # ### #
# # # # # # # # # # # # # # # # # #
# ### # # ####### # ### ##### # ####### ### ### # # ####### # # # ### #
# # # # # # # # # E#
#######################################################################
`.split("\n");
// Constants used in this program:
const EMPTY = " ";
const START = "S";
const EXIT = "E";
const PATH = ".";
// Get the height and width of the maze:
const HEIGHT = MAZE.length;
let maxWidthSoFar = MAZE[0].length;
for (let row of MAZE) { // Set WIDTH to the widest row's width.
if (row.length > maxWidthSoFar) {
maxWidthSoFar = row.length;
}
}
const WIDTH = maxWidthSoFar;
// Make each row in the maze a list as wide as the WIDTH:
for (let i = 0; i < MAZE.length; i++) {
MAZE[i] = MAZE[i].split("");
if (MAZE[i].length !== WIDTH) {
MAZE[i] = EMPTY.repeat(WIDTH).split(""); // Make this a blank row.
}
}
function printMaze(maze) {
document.write("<pre>");
for (let y = 0; y < HEIGHT; y++) {
// Print each row.
for (let x = 0; x < WIDTH; x++) {
// Print each column in this row.
document.write(maze[y][x]);
}
document.write("\n"); // Print a newline at the end of the row.
}
document.write("\n</ pre>");
}
function findStart(maze) {
for (let x = 0; x < WIDTH; x++) {
for (let y = 0; y < HEIGHT; y++) {
if (maze[y][x] === START) {
return [x, y]; // Return the starting coordinates.
}
}
}
}
function solveMaze(maze, x, y, visited) {
if (x === undefined || y === undefined) {
[x, y] = findStart(maze);
maze[y][x] = EMPTY; // Get rid of the 'S' from the maze.
}
if (visited === undefined) {
visited = []; // Create a new list of visited points. // ?
}
if (maze[y][x] == EXIT) {
return true; // Found the exit, return true.
}
maze[y][x] = PATH; // Mark the path in the maze.
visited.push(String(x) + "," + String(y)); // ?
//printMaze(maze) // Uncomment to view each forward step. # ?
// Explore the north neighboring point:
if ((y + 1 < HEIGHT) && ((maze[y + 1][x] == EMPTY) ||
(maze[y + 1][x] == EXIT)) &&
(visited.indexOf(String(x) + "," + String(y + 1)) === -1)) {
// RECURSIVE CASE
if (solveMaze(maze, x, y + 1, visited)) {
return true; // BASE CASE
}
}
// Explore the south neighboring point:
if ((y - 1 >= 0) && ((maze[y - 1][x] == EMPTY) ||
(maze[y - 1][x] == EXIT)) &&
(visited.indexOf(String(x) + "," + String(y - 1)) === -1)) {
// RECURSIVE CASE
if (solveMaze(maze, x, y - 1, visited)) {
return true; // BASE CASE
}
}
// Explore the east neighboring point:
if ((x + 1 < WIDTH) && ((maze[y][x + 1] == EMPTY) ||
(maze[y][x + 1] == EXIT)) &&
(visited.indexOf(String(x + 1) + "," + String(y)) === -1)) {
// RECURSIVE CASE
if (solveMaze(maze, x + 1, y, visited)) {
return true; // BASE CASE
}
}
// Explore the west neighboring point:
if ((x - 1 >= 0) && ((maze[y][x - 1] == EMPTY) ||
(maze[y][x - 1] == EXIT)) &&
(visited.indexOf(String(x - 1) + "," + String(y)) === -1)) {
// RECURSIVE CASE
if (solveMaze(maze, x - 1, y, visited)) {
return true; // BASE CASE
}
}
maze[y][x] = EMPTY; // Reset the empty space.
//printMaze(maze); // Uncomment to view each backtrack step. # ?
return false; // BASE CASE
}
printMaze(MAZE);
solveMaze(MAZE);
printMaze(MAZE);
</script>
这段代码与递归解迷宫算法无直接关系。MAZE变量将迷宫数据存储为多行字符串,其中井号表示墙壁,S表示起点,E表示出口。这个字符串被转换为一个包含字符串列表的列表,每个字符串表示迷宫中的一个单个字符。这使我们能够访问MAZE[y][x](注意y在前)以获取原始MAZE字符串中 x,y 坐标处的字符。printMaze()函数可以接受这个列表-列表数据结构并在屏幕上显示迷宫。findStart()函数接受这个数据结构并返回S起点的 x,y 坐标。随意编辑迷宫字符串——但请记住,为了使解决算法起作用,迷宫不能有任何循环。
递归算法在solveMaze()函数中。这个函数的参数是迷宫数据结构,当前的 x 和 y 坐标,以及一个visited列表(如果没有提供,则创建)?。visited列表包含先前访问过的所有坐标,因此当算法从死胡同回溯到较早的交叉点时,它知道它以前尝试过哪些路径,并且可以尝试不同的路径。从起点到出口的路径通过用句点(来自PATH常量)替换迷宫数据结构中的空格(匹配EMPTY常量)来标记。
解迷宫算法类似于我们在第三章中的泛洪填充程序,它“扩散”到相邻的坐标,但当它到达死胡同时,它会回溯到较早的交叉点。solveMaze()函数接收指示算法当前位置的 x,y 坐标。如果这是出口,函数返回True,导致所有递归调用也返回True。迷宫数据结构保持标记为解决方案路径。
否则,算法会在迷宫数据结构中标记当前的 x,y 坐标,并将这些坐标添加到“visited”列表中?。然后它会查看当前坐标北面的 x,y 坐标,看看那个点是否没有超出地图边缘,是空白或出口空间,并且以前没有被访问过。如果满足这些条件,算法将使用北面的坐标进行递归调用solveMaze()。如果不满足这些条件或递归调用solveMaze()返回False,算法将继续检查南、东和西坐标。与泛洪填充算法一样,使用相邻坐标进行递归调用。
要更好地了解这个算法的工作原理,请取消solveMaze()函数内的两个printMaze(MAZE)调用? ?。这将显示迷宫数据结构在尝试新路径、到达死胡同、回溯和尝试不同路径时的情况。
总结
本章探讨了几种使用树数据结构和回溯的算法,这些算法是适合使用递归算法解决的问题的特点。我们介绍了树数据结构,它由包含数据的节点和将节点联系在一起的边组成,这些边以父-子关系相互关联。特别是,我们研究了一种特定类型的树,称为有向无环图(DAG),它经常在递归算法中使用。递归函数调用类似于在树中遍历到子节点,而从递归函数调用返回类似于回溯到以前的父节点。
虽然递归在简单的编程问题中被滥用,但它非常适合涉及类似树的结构和回溯的问题。利用这些类似树的结构的想法,我们编写了几个用于遍历、搜索和确定树结构深度的算法。我们还展示了一个简单连通的迷宫具有类似树的结构,并利用递归和回溯来解决迷宫。
进一步阅读
树和树遍历远不止本章中介绍的 DAG 的简要描述。维基百科的文章en.wikipedia.org/wiki/Tree_(data_structure)和en.wikipedia.org/wiki/Tree_traversal为这些概念提供了额外的背景信息,这些概念在计算机科学中经常使用。
Computerphile YouTube 频道还有一个名为“Maze Solving”的视频,讨论了这些概念。V. Anton Spraul,Think Like a Programmer(No Starch Press,2012)的作者,还有一个名为“Backtracking”的迷宫解决视频,网址为youtu.be/gBC_Fd8EE8A。freeCodeCamp 组织(freeCodeCamp.org)在youtu.be/A80YzvNwqXA上有一个关于回溯算法的视频系列。
除了解迷宫外,递归回溯算法还使用递归生成迷宫。您可以在en.wikipedia.org/wiki/Maze_generation_algorithm#Recursive_backtracker找到更多关于这个和其他迷宫生成算法的信息。
练习问题
通过回答以下问题来测试您的理解能力:
-
节点和边是什么?
-
根节点和叶节点是什么?
-
树遍历有哪三种顺序?
-
DAG代表什么?
-
什么是循环,DAG 有循环吗?
-
什么是二叉树?
-
二叉树中的子节点称为什么?
-
如果父节点有一条边指向子节点,并且子节点有一条边返回父节点,这个图被认为是 DAG 吗?
-
树遍历算法中的回溯是什么?
对于以下树遍历问题,您可以使用第四章“Python 和 JavaScript 中的树数据结构”中的 Python/JavaScript 代码作为您的树,以及mazeSolver.py和mazeSolver.html程序中的多行MAZE字符串作为迷宫数据。
-
回答本章中每个递归算法的三个问题:
-
什么是基本情况?
-
递归函数调用传递了什么参数?
-
这个论点如何更接近基本情况?
然后,重新创建本章中的递归算法,而不看原始代码。
练习项目
练习时,为以下每个任务编写一个函数:
-
创建一个逆中序搜索,执行中序遍历,但在遍历左子节点之前遍历右子节点。
-
创建一个函数,给定一个根节点作为参数,通过向原始树的每个叶节点添加一个子节点,使树深度增加一级。这个函数需要执行树遍历,检测是否已经到达叶节点,然后向叶节点添加一个且仅一个子节点。确保不要继续向这个新叶节点添加子节点,因为这最终会导致堆栈溢出。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 苹果MacOS12系统 Monterey最新正式版下载 MacOS12系统镜像包
- 华为OD机试真题-最长子字符串的长度(二)-2023年OD统一考试(C卷)
- MySQL -- Linux Ubuntu 环境安装MySQL数据库
- vue前端开发自学,子组件传递数据给父组件,使用$emit
- uView SwipeAction 滑动单元格
- redis.conf 默认出厂内容
- #头歌 数据结构 实验十二 排序的实现
- XXL-JOB相关问题及答案(2024)
- 易趋产品升级(EasyTrack 11_V1.3) | 集成飞书、WPS、个性化设置,增强团队协作和用户体验
- QQ录屏保存在哪个文件夹?教你轻松找回!