【霹雳吧啦】手把手带你入门语义分割の番外11:U2-Net 源码讲解(PyTorch)—— 代码的使用
目录
前言
文章性质:学习笔记 📖
视频教程:U2-Net 源码解析(Pytorch)- 1 代码的使用
主要内容:根据 视频教程 中提供的 U2-Net?源代码(PyTorch),对 train.py?文件进行具体讲解。
Preparation
在原官方的代码中只提供了训练脚本,并且训练脚本中没有提供验证功能,也就是说,只能去训练,而不知道它具体的验证指标。但在霹雳吧啦提供的项目代码中,补充了 评价验证指标 的功能。

U2-Net 的文件结构:
├── src: 搭建网络相关代码
├── train_utils: 训练以及验证相关代码
├── my_dataset.py: 自定义数据集读取相关代码
├── predict.py: 简易的预测代码
├── train.py: 单GPU或CPU训练代码
├── train_multi_GPU.py: 多GPU并行训练代码
├── validation.py: 单独验证模型相关代码
├── transforms.py: 数据预处理相关代码
└── requirements.txt: 项目依赖
【说明】validation.py 文件中是可以用来单独验证模型相关代码,在我们的训练样本中也包含了验证部分代码,只不过在 validation.py 这个文件中单独将验证部分的内容提取出来了。

【说明】霹雳吧啦搭建网络的方法与官方的仓库代码有所不同,按照霹雳吧啦提供的代码去搭建网络后,权重的名称将发生变化,因此提供了转换好的模型权重,分别是标准的 u2net_full.pth 和轻量的 u2net_lite.pth 。
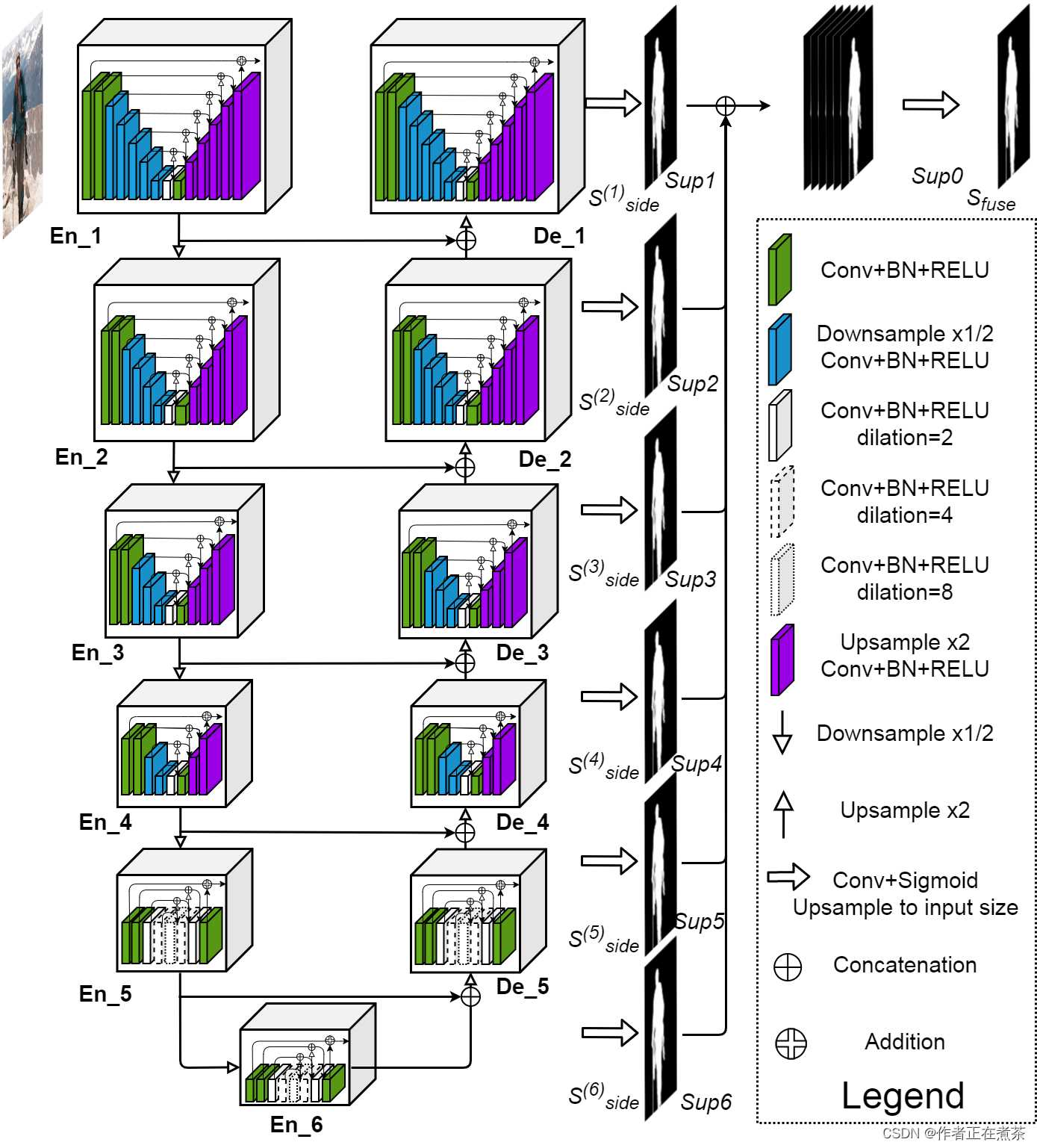
一、U2-Net 网络结构图
原论文提供的 U2-Net 网络结构图如下所示:?
二、U2-Net 网络源代码
1、train.py
(1)parse_args 参数

【代码解析】对?parse_args 参数设置的具体讲解(结合上图):
- data-path 指向 DUTS 数据集的根目录
- device 默认值设置为 cuda,若是有 GPU 则默认使用第一块 GPU 进行训练,否则默认使用 CPU 进行训练
- batch-size 默认值设置为 16
- weight-decay 是指权重衰减,是设置优化器时的超参数
- epochs 默认值设置为 360,也就是进行 360 轮训练
- eval-interval 默认值设置为 10,也就是每训练 10 轮进行一次验证
- lr 是指初始学习率,默认值设置为 0.001
- print-freq?用于设置打印输出的频率,默认值设置为 50
- resume 是指在训练中由于某些原因导致训练中断,将 default 参数设置为最近一次保存的权重,从而能够接着往后进行训练
- start-epoch 是指默认从第几个 epoch 开始训练,默认值设置为 0
- amp 表示是否去使用混合精度训练,使用混合精度训练能够加速训练过程,并且对显存的占用也更少
(2)SODPresetTrain 类
SODPresetTrain 类对应了训练集的预处理以及数据增强的部分。

【代码解析】对 SODPresetTrain 类代码的具体讲解(结合上图):?
在初始化?__init__ 方法中,传入了基础尺寸 base_size、裁剪后的尺寸 crop_size、水平翻转的概率 hflip_prob、图像每个通道的均值 mean、图像每个通道的标准差 std 等参数。在初始化 __init__ 方法中,定义了一个 transforms 变量,并使用 torchvision.transforms.Compose 函数,将多个图像变换操作 组合 在一起,这些变换操作包括:
- ?T.ToTensor() 可将 PIL 图像或数组转换为张量(Tensor)形式
- ?T.Resize(base_size, resize_mask=True) 将图像缩放到?base_size 尺寸,因为?resize_mask 为 True ,对?target 目标也进行相应缩放
- ?T.RandomCrop(crop_size) 将图像和 target 目标进行随机裁剪,裁剪成?crop_size 尺寸
- ?T.RandomHorizontalFlip(hflip_prob) 将图像和 target 目标进行水平方向上的随机翻转,从而增加数据的多样性
- ?T.Normalize(mean=mean, std=std) 使用给定的 mean 均值和 std 标准差对图像进行归一化
在 __call__ 方法中,将输入的图像和目标都传递给之前定义的 transforms 变量,实现对图像和目标的数据预处理,最终返回其结果。
(3)SODPresetEval 类
SODPresetEval 类对应了验证集的预处理以及数据增强的部分。

【代码解析】对 ?SODPresetEval 类代码的具体讲解(结合上图):
在初始化?__init__ 方法中,传入了基础尺寸 base_size、图像每个通道的均值 mean、图像每个通道的标准差 std 等参数。在初始化 __init__ 方法中,定义了一个 transforms 变量,并使用 torchvision.transforms.Compose 函数,将多个图像变换操作 组合 在一起,这些变换操作包括:
- ?T.ToTensor() 可将 PIL 图像或数组转换为张量(Tensor)形式
- ?T.Resize(base_size, resize_mask=False) 将图像缩放到?base_size 尺寸,由于?resize_mask 为 False,不对?target 目标也进行相应缩放
- ?T.Normalize(mean=mean, std=std) 使用给定的 mean 均值和 std 标准差对图像进行归一化
在 __call__ 方法中,将输入的图像和目标都传递给之前定义的 transforms 变量,实现对图像和目标的数据预处理,最终返回其结果。?
(4)main 函数

【代码解析1】对 main 主函数代码的具体讲解(结合上图):?
- ?检查我们所使用的机器中是否有可用的 GPU 设备,若有则按照传入的 device 去利用对应的 GPU 设备,否则默认使用 CPU
- ?根据时间戳去生成 results{}.txt 文件,后续会将训练结果保存到这个文件中
- ?用 DUTSDataset 去实例化 train_dataset 训练集和 val_dataset 验证集,这个 DUTSDataset 就是自定义数据集读取的部分?
- ?确定数据集加载器中使用的 num_workers 工作线程数量,它取决于计算机的 CPU 核心数、批次大小以及最大允许的工作线程数量
- ?用 data.DataLoader 去创建 train_data_loader 训练数据加载器和 val_data_loader 验证数据加载器,用于按批次加载数据
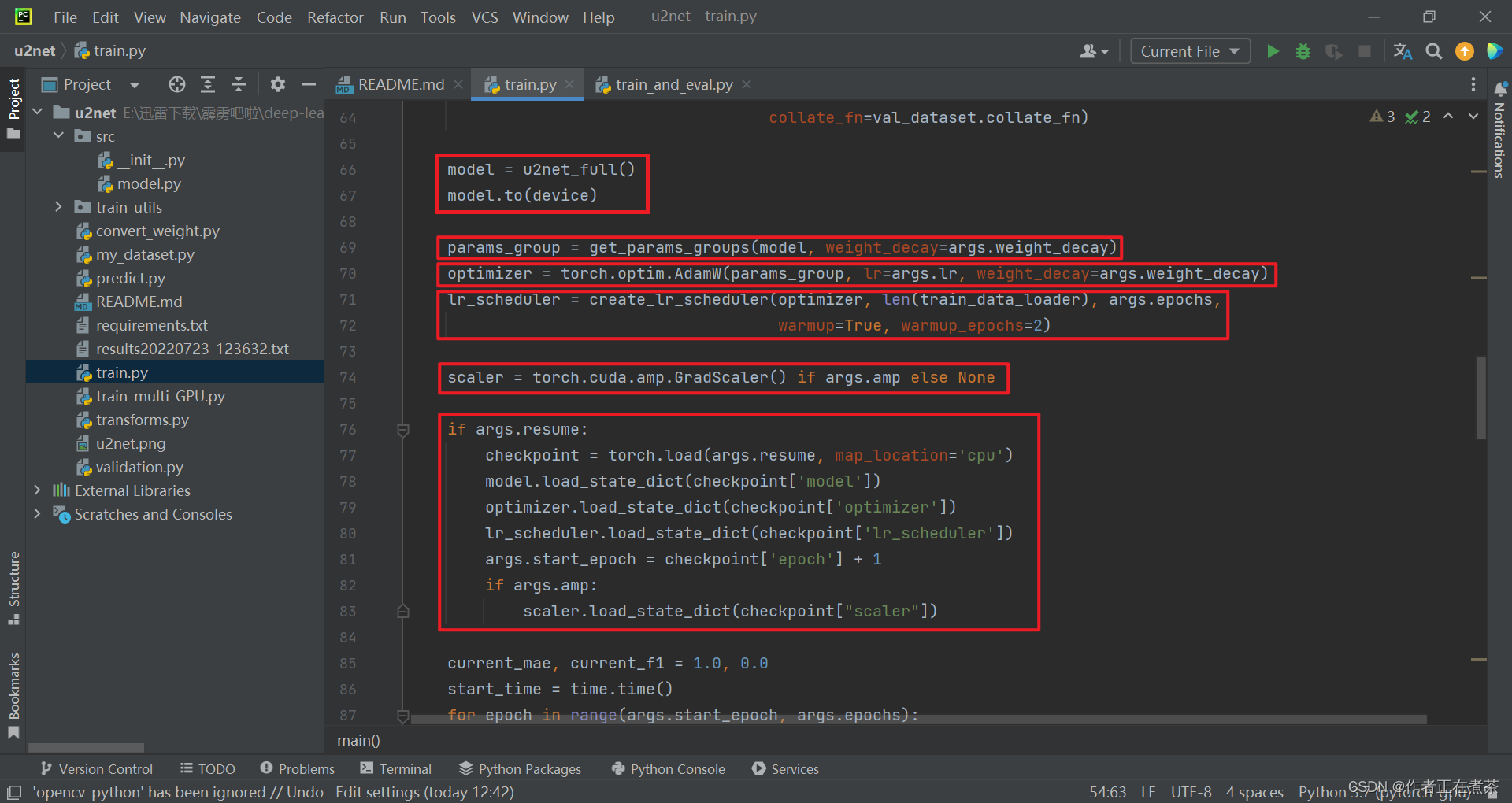
【代码解析2】对 main 主函数代码的具体讲解(结合上图):?
- ?用 u2net_full 创建模型对象,并将模型指定到对应的训练设备上
- ?根据指定的权重衰减系数,将模型参数进行分组,并返回 params_group 参数组列表
- ?创建优化器 optimizer 对象,这里我们采用的是?AdamW 优化器
- ?创建学习率变化策略?lr_scheduler 对象,先进行 warm up 热身训练,再以 cosine 的形式进行衰减
- ?根据 args.amp 的值判断是否启用混合精度训练,若是则用 torch.cuda.amp.GradScaler 创建梯度缩放器对象,否则为 None
- ?根据 args.resume 的值判断是否载入最近一次对应的权重、优化器、学习率变化策略等训练过程中需要使用到的信息

【代码解析3】对 main 主函数代码的具体讲解(结合上图):?
初始化平均绝对误差指标?MAE 和 max F-measure 指标?F1 ,MAE 越趋于 0 代表模型的效果越好,而 F1 越趋于 1 代表模型的效果越好,区间都在 0 和 1 之间?。在训练过程中,每间隔一定的 epoch 进行一次验证,若当前的 MAE 比我们记录的小,且 F1 比我们记录的大,就代表我们当前所得到的模型权重比之前记录的好,因此我们可以保存最近一次权重。

【代码解析4】对 main 主函数代码的具体讲解(结合上图):?
- ?在训练的迭代过程中,根据传入的 args.start_epoch 和 args.epochs 进行迭代,每迭代一轮,就在训练集上训练一次
- ?每进行一轮训练,就返回对应的平均损失 mean_loss 和当前的学习率 lr
- ?判断当前的 epoch 是否为 args.eval_interval 的整数倍,或者是否是最后一轮,若是则对模型进行评估和保存

【代码解析5】对 main 主函数代码的具体讲解(结合上图):
若当前的 MAE 大于等于验证集的 MAE,并且当前的 F1 小于等于验证集的 F1,则保存模型参数到文件;此外还会保存最近 10 轮的权重。
(5)train.py 源代码
import os
import time
import datetime
from typing import Union, List
import torch
from torch.utils import data
from src import u2net_full
from train_utils import train_one_epoch, evaluate, get_params_groups, create_lr_scheduler
from my_dataset import DUTSDataset
import transforms as T
class SODPresetTrain:
def __init__(self, base_size: Union[int, List[int]], crop_size: int,
hflip_prob=0.5, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
self.transforms = T.Compose([
T.ToTensor(),
T.Resize(base_size, resize_mask=True),
T.RandomCrop(crop_size),
T.RandomHorizontalFlip(hflip_prob),
T.Normalize(mean=mean, std=std)
])
def __call__(self, img, target):
return self.transforms(img, target)
class SODPresetEval:
def __init__(self, base_size: Union[int, List[int]], mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
self.transforms = T.Compose([
T.ToTensor(),
T.Resize(base_size, resize_mask=False),
T.Normalize(mean=mean, std=std),
])
def __call__(self, img, target):
return self.transforms(img, target)
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
batch_size = args.batch_size
# 用来保存训练以及验证过程中信息
results_file = "results{}.txt".format(datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
train_dataset = DUTSDataset(args.data_path, train=True, transforms=SODPresetTrain([320, 320], crop_size=288))
val_dataset = DUTSDataset(args.data_path, train=False, transforms=SODPresetEval([320, 320]))
num_workers = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
train_data_loader = data.DataLoader(train_dataset,
batch_size=batch_size,
num_workers=num_workers,
shuffle=True,
pin_memory=True,
collate_fn=train_dataset.collate_fn)
val_data_loader = data.DataLoader(val_dataset,
batch_size=1, # must be 1
num_workers=num_workers,
pin_memory=True,
collate_fn=val_dataset.collate_fn)
model = u2net_full()
model.to(device)
params_group = get_params_groups(model, weight_decay=args.weight_decay)
optimizer = torch.optim.AdamW(params_group, lr=args.lr, weight_decay=args.weight_decay)
lr_scheduler = create_lr_scheduler(optimizer, len(train_data_loader), args.epochs,
warmup=True, warmup_epochs=2)
scaler = torch.cuda.amp.GradScaler() if args.amp else None
if args.resume:
checkpoint = torch.load(args.resume, map_location='cpu')
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])
args.start_epoch = checkpoint['epoch'] + 1
if args.amp:
scaler.load_state_dict(checkpoint["scaler"])
current_mae, current_f1 = 1.0, 0.0
start_time = time.time()
for epoch in range(args.start_epoch, args.epochs):
mean_loss, lr = train_one_epoch(model, optimizer, train_data_loader, device, epoch,
lr_scheduler=lr_scheduler, print_freq=args.print_freq, scaler=scaler)
save_file = {"model": model.state_dict(),
"optimizer": optimizer.state_dict(),
"lr_scheduler": lr_scheduler.state_dict(),
"epoch": epoch,
"args": args}
if args.amp:
save_file["scaler"] = scaler.state_dict()
if epoch % args.eval_interval == 0 or epoch == args.epochs - 1:
# 每间隔eval_interval个epoch验证一次,减少验证频率节省训练时间
mae_metric, f1_metric = evaluate(model, val_data_loader, device=device)
mae_info, f1_info = mae_metric.compute(), f1_metric.compute()
print(f"[epoch: {epoch}] val_MAE: {mae_info:.3f} val_maxF1: {f1_info:.3f}")
# write into txt
with open(results_file, "a") as f:
# 记录每个epoch对应的train_loss、lr以及验证集各指标
write_info = f"[epoch: {epoch}] train_loss: {mean_loss:.4f} lr: {lr:.6f} " \
f"MAE: {mae_info:.3f} maxF1: {f1_info:.3f} \n"
f.write(write_info)
# save_best
if current_mae >= mae_info and current_f1 <= f1_info:
torch.save(save_file, "save_weights/model_best.pth")
# only save latest 10 epoch weights
if os.path.exists(f"save_weights/model_{epoch-10}.pth"):
os.remove(f"save_weights/model_{epoch-10}.pth")
torch.save(save_file, f"save_weights/model_{epoch}.pth")
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print("training time {}".format(total_time_str))
def parse_args():
import argparse
parser = argparse.ArgumentParser(description="pytorch u2net training")
parser.add_argument("--data-path", default="./", help="DUTS root")
parser.add_argument("--device", default="cuda", help="training device")
parser.add_argument("-b", "--batch-size", default=16, type=int)
parser.add_argument('--wd', '--weight-decay', default=1e-4, type=float,
metavar='W', help='weight decay (default: 1e-4)',
dest='weight_decay')
parser.add_argument("--epochs", default=360, type=int, metavar="N",
help="number of total epochs to train")
parser.add_argument("--eval-interval", default=10, type=int, help="validation interval default 10 Epochs")
parser.add_argument('--lr', default=0.001, type=float, help='initial learning rate')
parser.add_argument('--print-freq', default=50, type=int, help='print frequency')
parser.add_argument('--resume', default='', help='resume from checkpoint')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='start epoch')
# Mixed precision training parameters
parser.add_argument("--amp", action='store_true',
help="Use torch.cuda.amp for mixed precision training")
args = parser.parse_args()
return args
if __name__ == '__main__':
args = parse_args()
if not os.path.exists("./save_weights"):
os.mkdir("./save_weights")
main(args)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 直流有刷电机的简单高性能控制方法
- 6G:通往未来无线通信的新篇章
- 如何使用群晖Webdav将Obsidian笔记软件远程同步到公网访问
- 勾股数 - 华为OD统一考试
- windows发展历程
- 直播种类之图片直播
- VUE2 集成 Element
- 用户反映在浏览器中使用AI工具 Copilot 遇到严重卡顿问题,微软官方给出初步解释
- sql 语句查询今天、昨天、近7天、近30天、一个月内、上一月 数据 及 CONVERT 中数字参数用法
- 免费部署试用的低代码开发工具分享(100%源码)