ConcurrentSkipListMap 深度解析
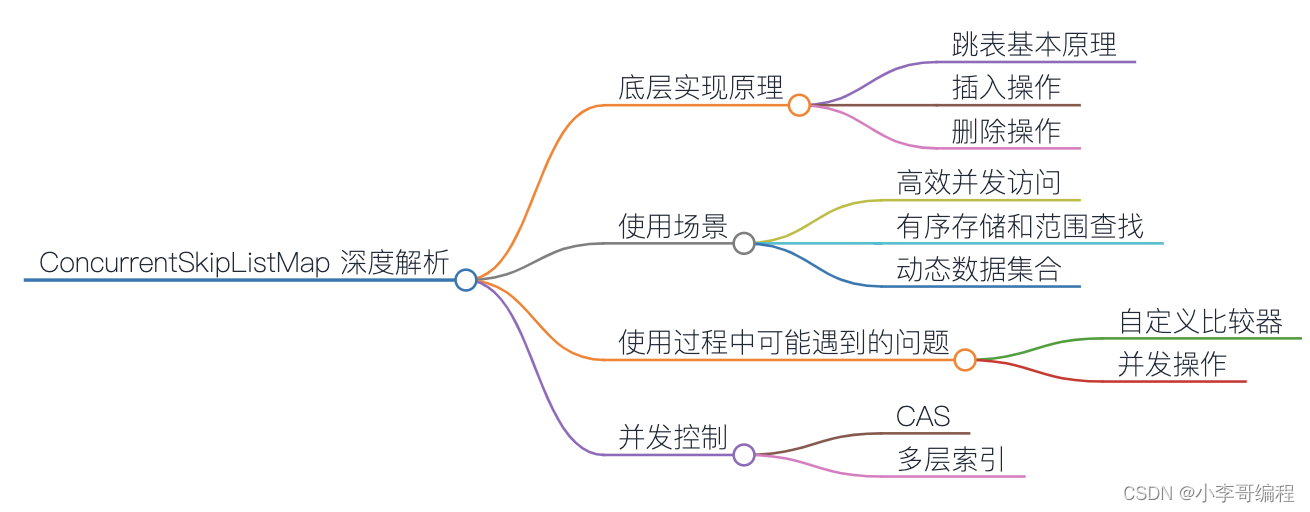
ConcurrentSkipListMap是Java集合框架中的一员,它实现了ConcurrentNavigableMap接口,基于跳表(Skip List)实现,并提供了高效的并发控制。在本文中,我们将深入研究ConcurrentSkipListMap的底层实现原理、适用场景、使用过程中可能遇到的问题,以及并发控制。
1. ConcurrentSkipListMap 的底层实现原理
1.1 跳表的基本原理
跳表是一种有序的数据结构,通过多层索引来加速查找。每一层都是一个有序的链表,最底层包含所有的元素。上层的链表包含的元素是下层链表元素的子集。这样,通过跳过一些元素,可以快速定位到目标元素。
1.2 插入操作
插入操作通过随机函数决定新节点是否提升到更高的层级,实现了O(log N)时间的插入操作。跳表通过不断地随机确定节点是否提升来保持平衡。
1.3 删除操作
删除操作也是O(log N)的操作。删除节点后,如果某一层的链表为空,需要将整个层级删除。
2. ConcurrentSkipListMap 的使用场景
2.1 并发环境中的高效并发访问
ConcurrentSkipListMap适用于需要在高并发环境中进行并发访问的场景。它通过使用CAS(Compare and Swap)等无锁算法,实现了对整个数据结构的高效并发控制。
2.2 有序存储和范围查找
类似于TreeMap,ConcurrentSkipListMap中的元素是有序的,支持按照键的范围进行查找,这使得它在范围查找的场景中非常有用。
2.3 动态数据集合
由于跳表的动态性,ConcurrentSkipListMap适用于动态数据集合,即数据的插入和删除频繁的场景。
3. 使用过程中可能遇到的问题
3.1 自定义比较器
与TreeMap类似,ConcurrentSkipListMap也支持自定义比较器。在构造函数中传入自定义的Comparator,以满足不同排序需求。
ConcurrentSkipListMap<Integer, String> customComparatorMap = new ConcurrentSkipListMap<>((o1, o2) -> o2 - o1);
3.2 并发操作
尽管ConcurrentSkipListMap提供了高效的并发控制,但在并发操作中,仍需要注意可能的竞态条件。对于一些复合操作,可能需要额外的同步。
4. 并发控制
4.1 CAS(Compare and Swap)
ConcurrentSkipListMap使用CAS等无锁算法进行并发控制。这种方式避免了传统锁的竞争,提高了并发性能。
4.2 多层索引
跳表的多层索引也是一种并发控制的手段。通过多层索引,可以在不影响整体结构的情况下,对部分节点进行修改。
ConcurrentSkipListMap<Integer, String> concurrentMap = new ConcurrentSkipListMap<>();
concurrentMap.put(1, "One");
concurrentMap.put(2, "Two");
// 高效并发操作
String value = concurrentMap.get(1);
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【LeetCode】每日一题 2023_12_13 字典序最小回文串(双指针,模拟)
- 基于杂交PSO算法的风光储微网日前优化调度(MATLAB实现)
- OS_lab——分页机制与内存管理
- 巨变!如何理解中国发起的“数据要素X”计划?
- 超简单的node爬虫小案例
- FPGA时序分析与时序约束(三)——I/O接口约束
- 《最新出炉》系列入门篇-Python+Playwright自动化测试-7-浏览器的相关操作
- flutter FractionallySizedBox / 百分比布局、根据父容器百分比布局 / 点击空白隐藏键盘
- MySQL事务管理
- 2. Git