数据分析概述2(详细介绍机器学习
1.名词解释:
1.1算法和模型
算法:用于训练模型的方法,分为有监督学习、无监督学习、半监督学习。
模型:模型是使用机器学习算法利用数据集训练出的结果,是算法的输出;数据集的不同,训练出来的模型也不同,这些模型的区别就在于参数取值不同。
1.2参数和超参数
参数可以分为算法参数(超参数)和模型参数(参数)
超参数:控制机器学习过程并确定最终学习得到的模型参数值的参数;超参数需要自己手动指定;例如:训练集和测试集的分割比例、优化算法中的学习率、聚类算法中的聚类数、多数算法中损失函数的选择、神经网络学习中激活函数的选择、神经网络中隐藏层数及迭代次数(epoch)等。
参数:训练出的结果;通常,同一个算法所训练出的模型的参数个数和类型是一致的,区别在于参数取值。
2.基础算法:
根据属性值是否为连续属性,将机器学习算法分为以下四类:
| 有监督学习 | 无监督学习 | |
|---|---|---|
| 连续型 | 聚类(k-means/GMM/LVQ/DBSCAN/AGNES)降维(SVD/PCA) | 回归(线性回归/多项式回归/决策树与随机森林) |
| 分类型 | 关联规则分析(Apriori/FP-Growth) | 分类(KNN/逻辑回归/朴素贝叶斯/SVM/决策树与随机森林 |
3.高级算法:
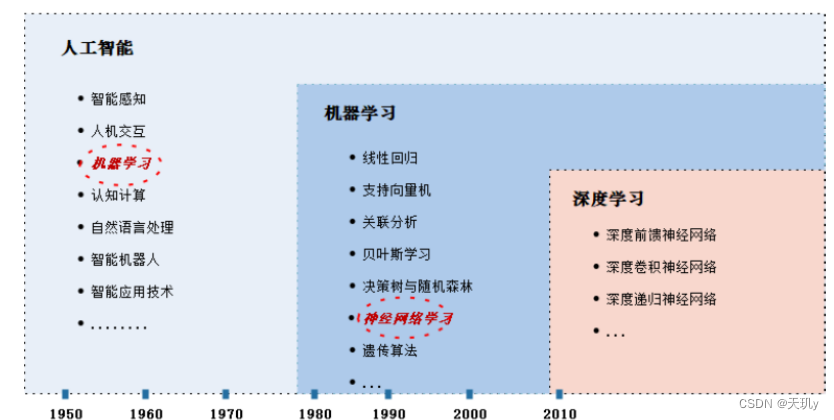
集成学习(Ensemble Learning,EL):由于上述基本算法在实际应用中容易导致过拟合或欠拟合,在数据分析中一般采用基于多个学习器来共同完成同一个数据分析任务。
深度学习(Deep Learing,DL):人工智能、机器学习和深度学习是数据分析中常用技术和方法,其区别和联系如上图所示。机器学习是人工智能的组成部分之一,而深度学习是机器学习的一种方法。
增强学习(Reinforcement Learning,RL):又称强化学习主要研究的是如何协助自治 Agent 的学习活动,进而达到选择最优动作的目的强化学习是通过反馈的结果信息不断调整之前的策略,从而算法能够学习到在什么样的状态下选择什么样的动作可以获得最好的结果。增强学习中讨论的Agent 需要具备与环境的交互能力和自治能力,当Agent 在其环境中做出每个动作时,施教者会提供奖赏或惩罚信息,以表示结果状态的正确与否。通常,强化学习任务用马尔可夫决策过程描述。常用的强化学习算法有蒙特卡洛强化学习和 Q-Learning 算法。
4.数据准备
数据准备包括数据整合、数据清洗 (数据标准化、数据标注、缺失值和异常值的处理)、数据转换、数据集划分等步骤。机器学习的数据集分为训练集、测试集和 验证集 3 种。也就是说,基于机器学习的数据分析工作需要将数据随机地拆分为 3 个子集——训练集、测试集和验证集。3 个子集的占比没有规定的比例,但训练集的占比应最大经验分配比例为7:1.5:1.5或9.5:0.25:0.25。
训练集(Training Set):用于模型训练;训练出模型。
测试集(Testing Set):用于模型评估;生成混淆矩阵,并计算精度和召回率。从而判断模型是否存在过拟合或欠拟合。
验证集(Validation Set):用于算法选择和超参调整。
5.常用python包



小结:
关注我给大家分享更多有趣的知识,以下是个人公众号,提供 ||代码兼职|| ||代码问题求解||
由于本号流量还不足以发表推广,搜我的公众号即可:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Docker入门概述
- 基于Java的毕业设计,可作课程设计,已通过验收可运行
- 在千万级别数据库查询中,从数据库设计,SQL 语句, java 等层面提高查询效率
- 安装mariadb
- 爬取彼案壁纸
- C++/C中的‘extern’关键词
- Qt QWidget窗口基类
- Guix Studio 中的Attach 和 Show
- Vue Methods 方法的使用(VUE学习5)
- 函数式编程的Java编码实践:利用惰性写出高性能且抽象的代码