[自用代码]labelme--人脸关键点标注--json转xml--xml转txt
发布时间:2023年12月24日
1. labelme标注人脸:
(翻个白眼先)用“Create rectangle”和“Create Point”,类别分别为“face, le, re, no, lm, rm”(脸,左眼,右眼,鼻子,左嘴角,右嘴角);
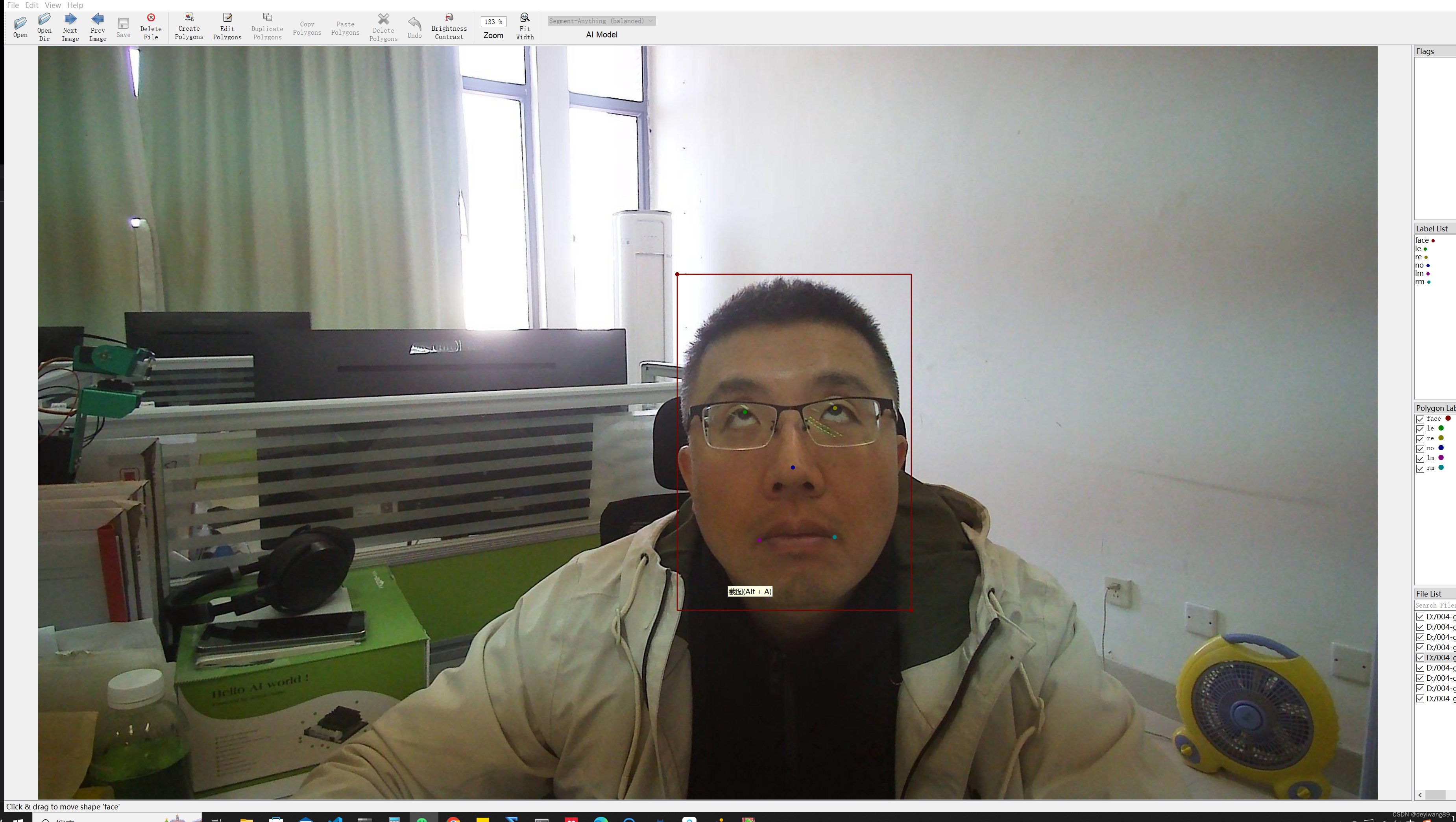
标注好后会生成json文件内容具体如下:
{
"version": "5.3.1",
"flags": {},
"shapes": [
{
"label": "face",
"points": [
[
1222.1052631578948,
447.4436090225564
],
[
1677.7443609022555,
1112.1052631578948
]
],
"group_id": null,
"description": "",
"shape_type": "rectangle",
"flags": {}
},
{
"label": "le",
"points": [
[
1383.7593984962405,
757.9699248120301
]
],
"group_id": null,
"description": "",
"shape_type": "point",
"flags": {}
},
{
"label": "re",
"points": [
[
1558.1954887218044,
758.7218045112782
]
],
"group_id": null,
"description": "",
"shape_type": "point",
"flags": {}
},
{
"label": "no",
"points": [
[
1477.7443609022555,
864.7368421052631
]
],
"group_id": null,
"description": "",
"shape_type": "point",
"flags": {}
},
{
"label": "lm",
"points": [
[
1400.3007518796992,
979.7744360902255
]
],
"group_id": null,
"description": "",
"shape_type": "point",
"flags": {}
},
{
"label": "rm",
"points": [
[
1540.9022556390976,
979.7744360902255
]
],
"group_id": null,
"description": "",
"shape_type": "point",
"flags": {}
}
],
"imagePath": "WIN_20231224_10_14_05_Pro.jpg",
2 解析 json 文件
生成VOC格式的文件夹,参考一些代码,进行修改,实现对“point”和“bndbox”类别的读取,并生成xml文件,运行命令:python labelme2voc.py temp_face wider --label label.txt
#!/usr/bin/env python
from __future__ import print_function
import argparse
import glob
import os
import os.path as osp
import sys
import imgviz
import labelme
try:
import lxml.builder
import lxml.etree
except ImportError:
print("Please install lxml:\n\n pip install lxml\n")
sys.exit(1)
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("input_dir", help="input annotated directory")
parser.add_argument("output_dir", help="output dataset directory")
parser.add_argument("--labels", help="labels file", required=True)
parser.add_argument(
"--noviz", help="no visualization", action="store_true"
)
args = parser.parse_args()
if osp.exists(args.output_dir):
print("Output directory already exists:", args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir)
os.makedirs(osp.join(args.output_dir, "JPEGImages"))
os.makedirs(osp.join(args.output_dir, "Annotations"))
if not args.noviz:
os.makedirs(osp.join(args.output_dir, "AnnotationsVisualization"))
print("Creating dataset:", args.output_dir)
class_names = []
class_name_to_id = {}
for i, line in enumerate(open(args.labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip()
class_name_to_id[class_name] = class_id
if class_id == -1:
assert class_name == "__ignore__"
continue
elif class_id == 0:
assert class_name == "_background_"
class_names.append(class_name)
class_names = tuple(class_names)
print("class_names:", class_names)
out_class_names_file = osp.join(args.output_dir, "class_names.txt")
with open(out_class_names_file, "w") as f:
f.writelines("\n".join(class_names))
print("Saved class_names:", out_class_names_file)
for filename in glob.glob(osp.join(args.input_dir, "*.json")):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")
out_xml_file = osp.join(args.output_dir, "Annotations", base + ".xml")
if not args.noviz:
out_viz_file = osp.join(
args.output_dir, "AnnotationsVisualization", base + ".jpg"
)
img = labelme.utils.img_data_to_arr(label_file.imageData)
imgviz.io.imsave(out_img_file, img)
maker = lxml.builder.ElementMaker()
xml = maker.annotation(
maker.folder(),
maker.filename(base + ".jpg"),
maker.database(), # e.g., The VOC2007 Database
maker.annotation(), # e.g., Pascal VOC2007
maker.image(), # e.g., flickr
maker.size(
maker.height(str(img.shape[0])),
maker.width(str(img.shape[1])),
maker.depth(str(img.shape[2])),
),
maker.segmented(),
)
bboxes = []
labels = []
for shape in label_file.shapes:
# if shape["shape_type"] != "rectangle":
# print(
# "Skipping shape: label={label}, "
# "shape_type={shape_type}".format(**shape)
# )
# continue
if shape["shape_type"] == "rectangle":
class_name = shape["label"]
class_id = class_names.index(class_name)
(xmin, ymin), (xmax, ymax) = shape["points"]
# swap if min is larger than max.
xmin, xmax = sorted([xmin, xmax])
ymin, ymax = sorted([ymin, ymax])
bboxes.append([ymin, xmin, ymax, xmax])
labels.append(class_id)
xml.append(
maker.object(
maker.name(shape["label"]),
maker.pose(),
maker.truncated(),
maker.difficult(),
maker.bndbox(
maker.xmin(str(xmin)),
maker.ymin(str(ymin)),
maker.xmax(str(xmax)),
maker.ymax(str(ymax)),
),
)
)
elif shape["shape_type"] == "point":
class_name = shape["label"]
class_id = class_names.index(class_name)
# print(shape["points"])
[[x,y]]= shape["points"]
xml.append(
maker.object(
maker.name(shape["label"]),
maker.pose(),
maker.truncated(),
maker.difficult(),
maker.point(
maker.x(str(x)),
maker.y(str(y)),
),
)
)
else:
continue
if not args.noviz:
captions = [class_names[label] for label in labels]
viz = imgviz.instances2rgb(
image=img,
labels=labels,
bboxes=bboxes,
captions=captions,
font_size=15,
)
imgviz.io.imsave(out_viz_file, viz)
with open(out_xml_file, "wb") as f:
f.write(lxml.etree.tostring(xml, pretty_print=True))
if __name__ == "__main__":
main()
生成如下的xml文件:
<annotation>
<folder/>
<filename>WIN_20231224_10_14_05_Pro.jpg</filename>
<database/>
<annotation/>
<image/>
<size>
<height>1440</height>
<width>2560</width>
<depth>3</depth>
</size>
<segmented/>
<object>
<name>face</name>
<pose/>
<truncated/>
<difficult/>
<bndbox>
<xmin>1222.1052631578948</xmin>
<ymin>447.4436090225564</ymin>
<xmax>1677.7443609022555</xmax>
<ymax>1112.1052631578948</ymax>
</bndbox>
</object>
<object>
<name>le</name>
<pose/>
<truncated/>
<difficult/>
<point>
<x>1383.7593984962405</x>
<y>757.9699248120301</y>
</point>
</object>
<object>
<name>re</name>
<pose/>
<truncated/>
<difficult/>
<point>
<x>1558.1954887218044</x>
<y>758.7218045112782</y>
</point>
</object>
<object>
<name>no</name>
<pose/>
<truncated/>
<difficult/>
<point>
<x>1477.7443609022555</x>
<y>864.7368421052631</y>
</point>
</object>
<object>
<name>lm</name>
<pose/>
<truncated/>
<difficult/>
<point>
<x>1400.3007518796992</x>
<y>979.7744360902255</y>
</point>
</object>
<object>
<name>rm</name>
<pose/>
<truncated/>
<difficult/>
<point>
<x>1540.9022556390976</x>
<y>979.7744360902255</y>
</point>
</object>
</annotation>
3. xml 转换成 txt
借助人工智能写出代码框架,再进行调整,实现功能
import xml.etree.ElementTree as ET
import os
def operate(dir_path,file,result_path):
file_name = os.path.join(dir_path, file)
# 解析XML文件
tree = ET.parse(file_name)
root = tree.getroot()
# 获取图片名称
filename = root.find('filename').text
# 遍历XML数据并转换为txt格式
# fff = dir_path.replace("Annotations","JPEGImages") + "/"
# txt_data = f"# {fff}{filename}\n"
txt_data = f"# {filename}\n"
for obj in root.findall('object'):
name = obj.find('name').text
if name == 'face':
bndbox = obj.find('bndbox')
xmin = float(bndbox.find('xmin').text)
ymin = float(bndbox.find('ymin').text)
xmax = float(bndbox.find('xmax').text)
ymax = float(bndbox.find('ymax').text)
txt_data += f"{int(xmin)} {int(ymin)} {int(xmax-xmin)} {int(ymax-ymin)} "
for obj in root.findall('object'):
name = obj.find('name').text
if name in ["le"]:
point = obj.find('point')
x = float(point.find('x').text)
y = float(point.find('y').text)
txt_data += f"{int(x)} {int(y)} "
txt_data += "0.0 "
for obj in root.findall('object'):
name = obj.find('name').text
if name in ["re"]:
point = obj.find('point')
x = float(point.find('x').text)
y = float(point.find('y').text)
txt_data += f"{int(x)} {int(y)} "
txt_data += "0.0 "
for obj in root.findall('object'):
name = obj.find('name').text
if name in ["no"]:
point = obj.find('point')
x = float(point.find('x').text)
y = float(point.find('y').text)
txt_data += f"{int(x)} {int(y)} "
txt_data += "0.0 "
for obj in root.findall('object'):
name = obj.find('name').text
if name in ["lm"]:
point = obj.find('point')
x = float(point.find('x').text)
y = float(point.find('y').text)
txt_data += f"{int(x)} {int(y)} "
txt_data += "0.0 "
for obj in root.findall('object'):
name = obj.find('name').text
if name in ["rm"]:
point = obj.find('point')
x = float(point.find('x').text)
y = float(point.find('y').text)
txt_data += f"{int(x)} {int(y)} "
txt_data += "0.0 "
# 将转换后的txt数据写入文件
with open(result_path, "a+",encoding="utf-8") as file:
file.write(txt_data)
file.write("\n")
dir_path = "wider/Annotations"
result_file_path = "result.txt"
dirs=os.listdir(dir_path)
for file in dirs:
operate(dir_path,file,result_file_path)
得到如下内容的 .txt 文件
# WIN_20231224_10_14_05_Pro.jpg
1222 447 455 664 1383 757 0.0 1558 758 0.0 1477 864 0.0 1400 979 0.0 1540 979 0.0
# WIN_20231224_10_14_06_Pro.jpg
1221 447 460 674 1386 762 0.0 1563 762 0.0 1479 866 0.0 1405 985 0.0 1551 988 0.0
# WIN_20231224_10_14_07_Pro.jpg
1214 445 494 673 1497 774 0.0 1657 753 0.0 1617 875 0.0 1522 1005 0.0 1651 985 0.0
# WIN_20231224_10_14_08_Pro.jpg
1203 451 475 684 1296 774 0.0 1471 778 0.0 1379 884 0.0 1331 1002 0.0 1466 1009 0.0
# WIN_20231224_10_14_09_Pro.jpg
1221 436 447 642 1350 699 0.0 1522 691 0.0 1442 805 0.0 1378 944 0.0 1522 938 0.0
# WIN_20231224_10_14_10_Pro.jpg
1216 448 464 712 1376 841 0.0 1552 839 0.0 1468 971 0.0 1398 1055 0.0 1531 1051 0.0
# WIN_20231224_10_14_11_Pro.jpg
1201 446 466 665 1303 766 0.0 1493 761 0.0 1386 869 0.0 1331 988 0.0 1473 983 0.0
# WIN_20231224_10_14_12_Pro (2).jpg
1295 459 519 692 1681 810 0.0 1794 810 0.0 1783 927 0.0 1651 1037 0.0 1745 1029 0.0
# WIN_20231224_10_14_12_Pro.jpg
1216 454 469 672 1431 791 0.0 1603 778 0.0 1558 900 0.0 1469 1017 0.0 1601 1000 0.0
文章来源:https://blog.csdn.net/weixin_38757163/article/details/135185868
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python学习之路-Hello Python
- Python3 数字(Number)
- Python开发环境搭建
- 谈一谈网络协议中的传输层
- 14:00面试,14:06就出来了,问的问题有点变态。。。
- Allegro 将shape转换为line,将line转换成shape
- CentOS使用docker安装mysql并使用navicat 远程链接
- Vite与Webpack对比
- 实战:使用docker容器化服务与文件挂载-2
- js显示实时时间