Text2SQL学习整理(一) 综述
数据库由一张或多张表格构成,表格之间的关系通过共同的列(外键)关联,人们使用数据库来方便的记录和存储信息。SQL是广泛应用的关系型数据库查询语言,但是对于普通用户而言,编写SQL语句有一定的难度。
Text2SQL是近年来NLP领域一个比较热门的研究方向,该任务历史悠久,应用和落地性很强。该任务是在已知数据库的表名、列名其从属关系(这些统称为数据库的Schema)的前提下,将人类的自然语言问句(Question)转化为对应的数据库查询SQL语句。
如下图所示,模型接收一个Question问句和一个数据库作为输入,然后将其转化为可执行的结构化查询语句(即SQL语句)进行查询,最终返回结果给用户。
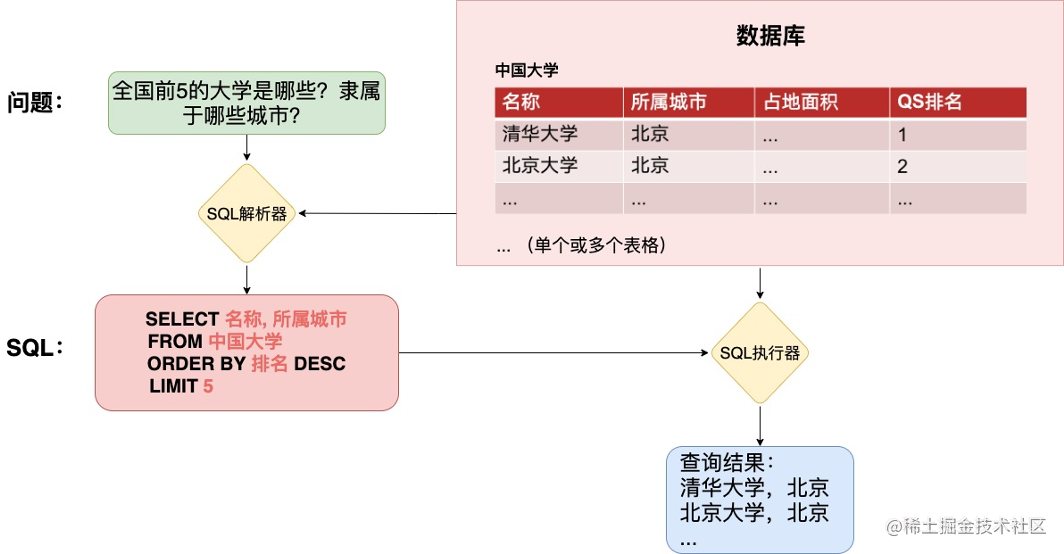
早期的Text2SQL数据集诸如ATIS(Airline Travel Information Systems,航空订票系统)、GeoQuery(地理查询系统)等都是限定于某个特定领域的数据库,仅能解决特定领域的问题,泛化性能较差。而现实世界中,关系型数据库已经广泛应用于社会的各行各业。为此,越来越多的多数据库、跨表查询的Text2SQL数据集被提出,比较知名的数据集有WikiSQL、Spider、SParC和CoSQL。这些数据集的提出极大地促进了该领域的发展,目前的SOTA模型也已经实现了非常好的表现。
这几个数据集的特性如下:
| 数据集 | 提出时间、会议 | 特点 |
|---|---|---|
| WikiSQL | arXiv,2017 | 多数据库、多表、单轮、简单语句 |
| Spider | EMNLP,2018 | 多数据库、多表、单轮、复杂语句 |
| SparC | ACL,2019 | 多数据库、多表、多轮、复杂语句 |
| CoSQL | EMNLP,2019 | 多数据库、多表、多轮、对话形式、复杂语句 |
从上表可以看出,所提出的数据集越来越复杂,难度越来越大,同时也越来越接近于现实世界中的真实数据库。
以下为Spider论文中的一个示例:
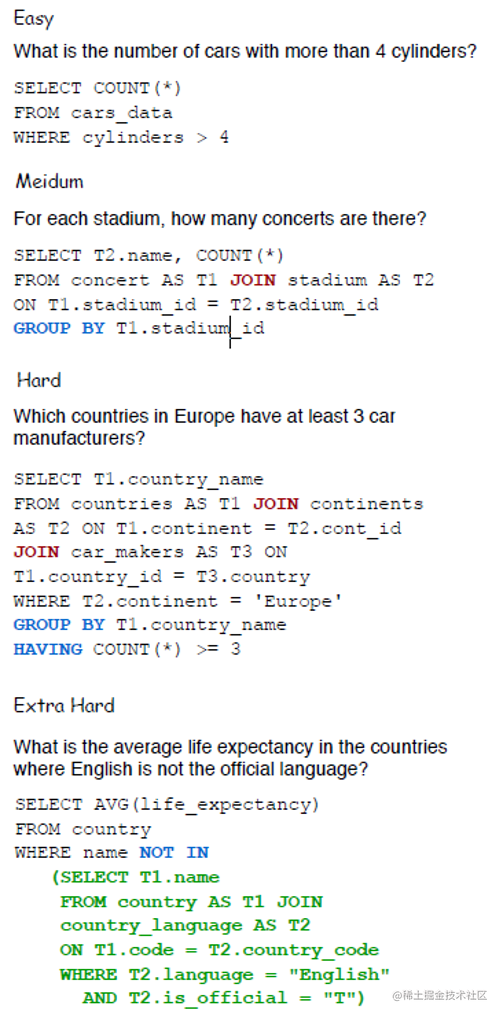
可以看出,对于Hard和Very Hard难度的SQL语句,里面存在着许许多多的多表链接、子句嵌入等SQL高级形式,即使是一位经验丰富的数据库工程师也无法很快写出这样的语句。因而,Text2SQL任务不仅可以帮助非专业用户进行查询,而且可以协助数据库工程师来减轻他们的工作量。
本系列博客将沿着近年来对这几个知名数据集上的研究论文来进行阅读总结,并从中归纳该领域的研究脉络。下一篇博客将开始从WikiSQL数据集入手,介绍在该数据集上当前的研究进展。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vue3-富文本编辑器(vue-quill)
- 78-C语言-完数的判断,以及输出其因子
- 【ZYNQ】AXI4总线接口协议学习
- 日常测试工作中哪些是必须知道的 SQL 语句?
- 京东年度数据报告-2023全年度烘干机十大热门品牌销量榜单
- PiflowX组件-JDBCWrite
- 乐意购项目前端开发 #3
- Unity 问题 之 ScrollView ,LayoutGroup,ContentSizeFitter 一起使用时,动态变化时无法及时刷新更新适配界面的问题
- TDSQL数据库使用限制有那些?需要注意什么?
- C# 图解教程 第5版 —— 第23章 异常