第六节课 OpenCompass 大模型评测(笔记)
发布时间:2024年01月24日
 一、关于评测的三个问题?
一、关于评测的三个问题?
1.为什么需要评测?
- 模型选型
- 模型能力提升
- 真是应用场景效果评测
2.我们需要测什么?
- 知识、推理、语言
- 长文本、智能体、多轮对话
- 情感、认知、价值观
3.怎么样测试大语言模型
- 自动化客观评测
- 人机交互评测
- 基于大模型的大模型评测
二、我们为什么需要评测?
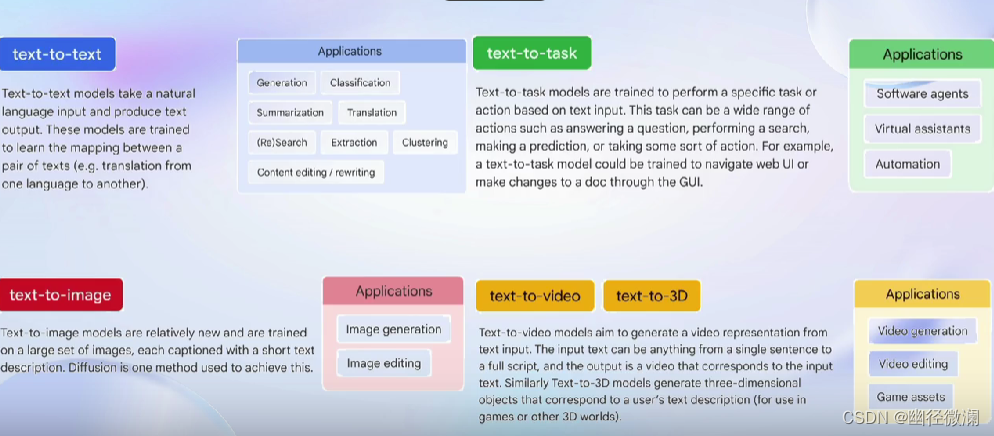

建立在公平的、全面的统一框架下
可以知道模型的能力边界
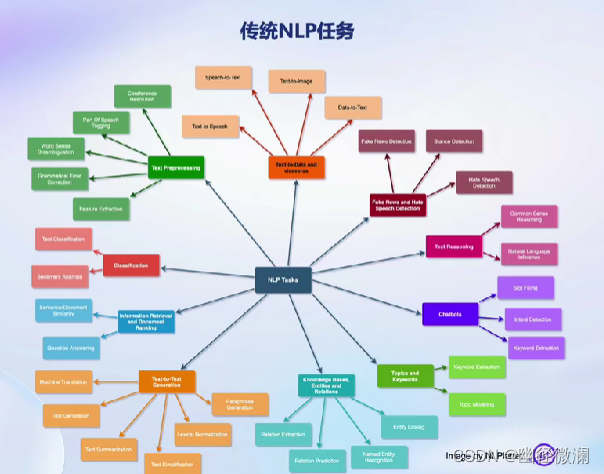
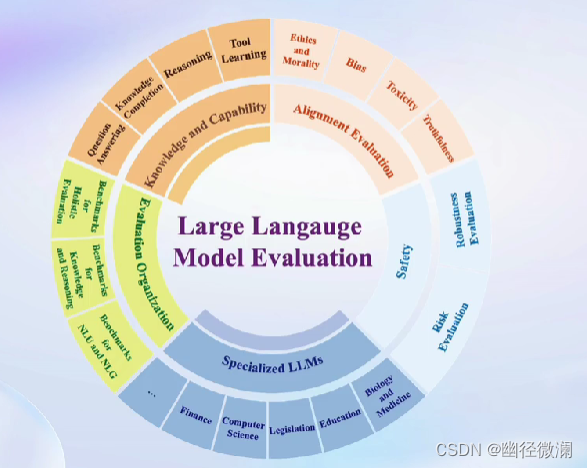
三、我们需要评测什么?
四、如何评测大语言模型
1.根据模型
- 基座模型
- 对话模型(经过指令微调的模型)
2.根据评测
- 客观评测(问答题、多选题、判断题/分类题/...)
- 主观评测(人类评价、模型评价)
3.提示词工程

?
五、主流大模型评测框架

六、OpenCompass 能力框架

Meta官方推荐,唯一由国内开发的大模型评测体系,其他三个分别是HuggingFace、Stanford和Google退出的测评体系。
架构:
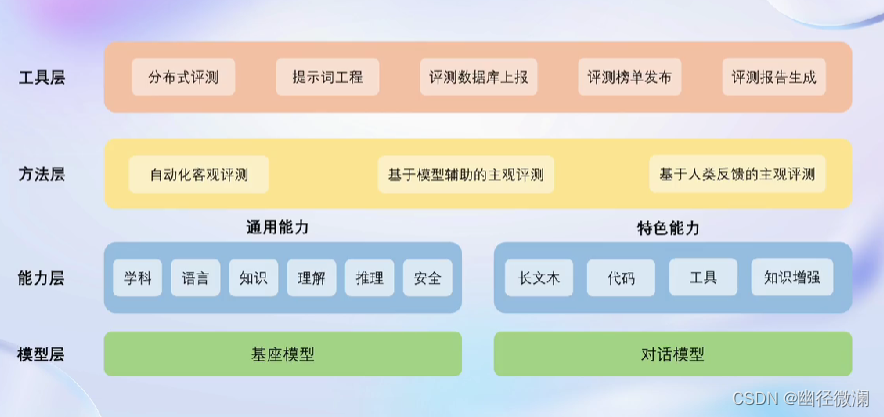
OpenCompass会将评测请求切分为多个独立执行的任务,从而最大化利用计算资源。
七、OpenCompass前沿探索
- 多模态(基于感知与推理将评估维度逐级细分)
- 法律领域(三维认知维度:法律知识理解、法律知识记忆、法律知识应用)
- 医疗领域(多来源基准评估维度)
八、大模型评测领域的挑战
- 缺少高质量中文评测集
- 难以准确提取答案
- 能力维度不足
- 测试集混入训练集
- 测试标准各异
- 人工测试成本高昂
文章来源:https://blog.csdn.net/2301_80618119/article/details/135721550
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- LLM大语言模型(三):使用ChatGLM3-6B的函数调用功能前先学会Python的装饰器
- 定时器中断控制的独立式键盘扫描实验
- 如何用GPT写代码?
- [ACM题目练习] 前后手
- 关于 log4net 日志功能使用方法
- BCELoss,BCEWithLogitsLoss和CrossEntropyLoss
- Datawhale 强化学习笔记(三)基于策略梯度(policy-based)的算法
- Java Swing手搓童年坦克大战游戏(II)
- 八大排序(插入排序 | 选择排序 | 冒泡排序)
- Appcelerator打包ipa有哪些优势