爬虫—抓取表情党热门栏目名称及链接
发布时间:2024年01月14日
爬虫—抓取表情党热门栏目名称及链接
表情党网址:https://qq.yh31.com/
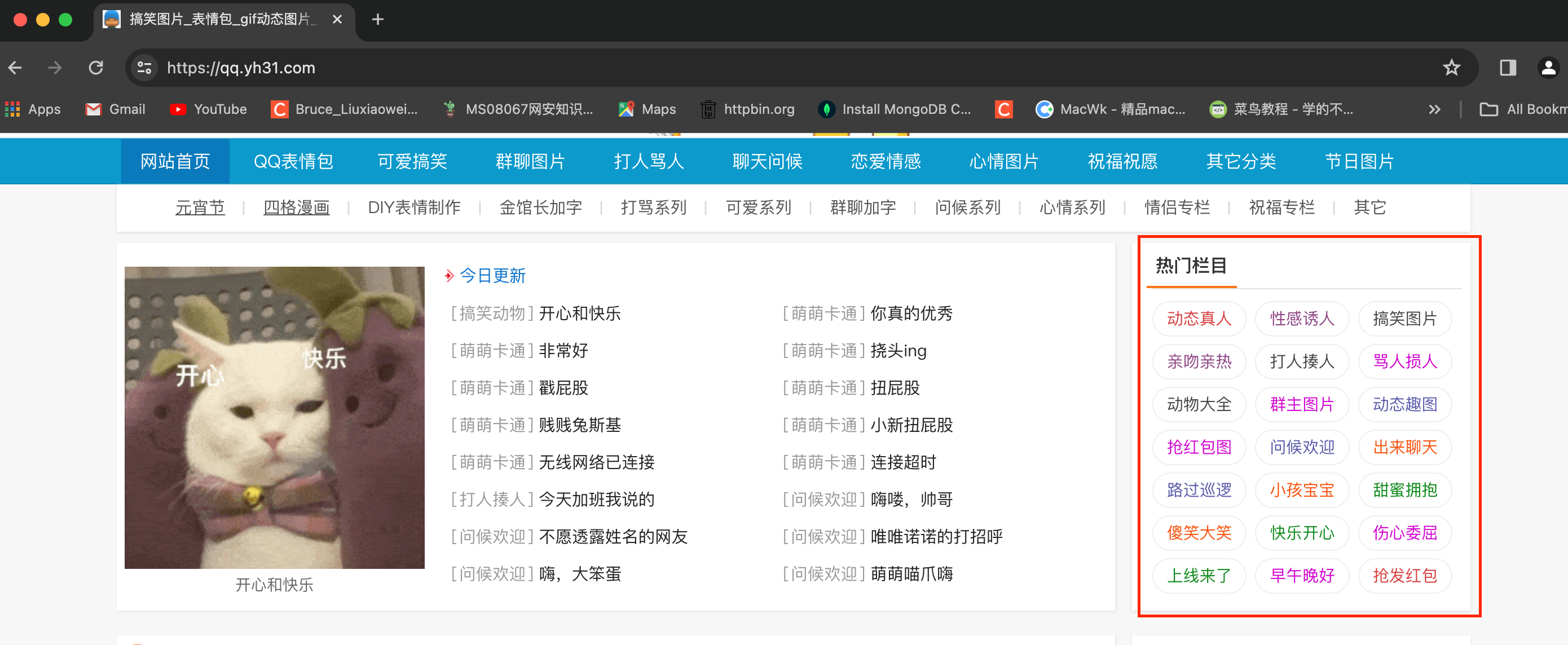
目标:抓取表情党主页的热门栏目名称及对应的链接,如下图所示:
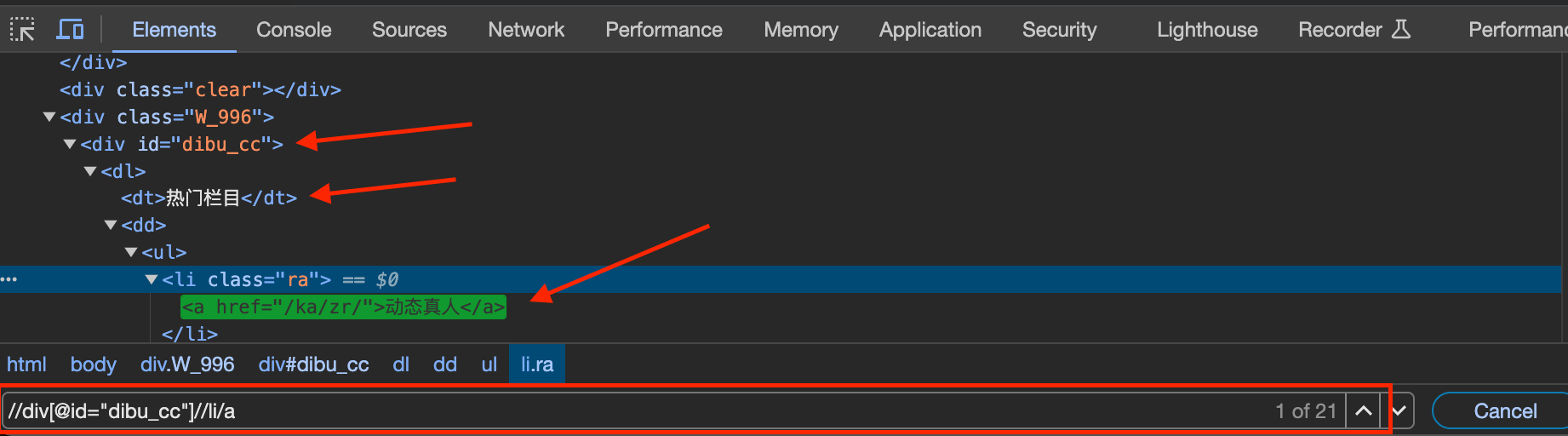
按F12(谷歌浏览器),进入开发者工具模式,进行页面分析,在Elements板块下,进入搜索栏(Ctrl+F),在框中输入“//div[@id=“dibu_cc”]//li/a“,可以匹配到所有的热门栏目a标签,如下图:
源码如下:
import requests
from lxml import etree
url = 'https://qq.yh31.com'
headers= {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
res = requests.get(url, headers=headers)
tree = etree.HTML(res.content)
rm_lst = tree.xpath('//div[@id="dibu_cc"]//li/a')
for rm in rm_lst:
print('热门栏目名称:', end=' ')
print(rm.xpath('./text()'))
print('热门栏目链接:', end=' ')
print(url + rm.xpath('./@href')[0])
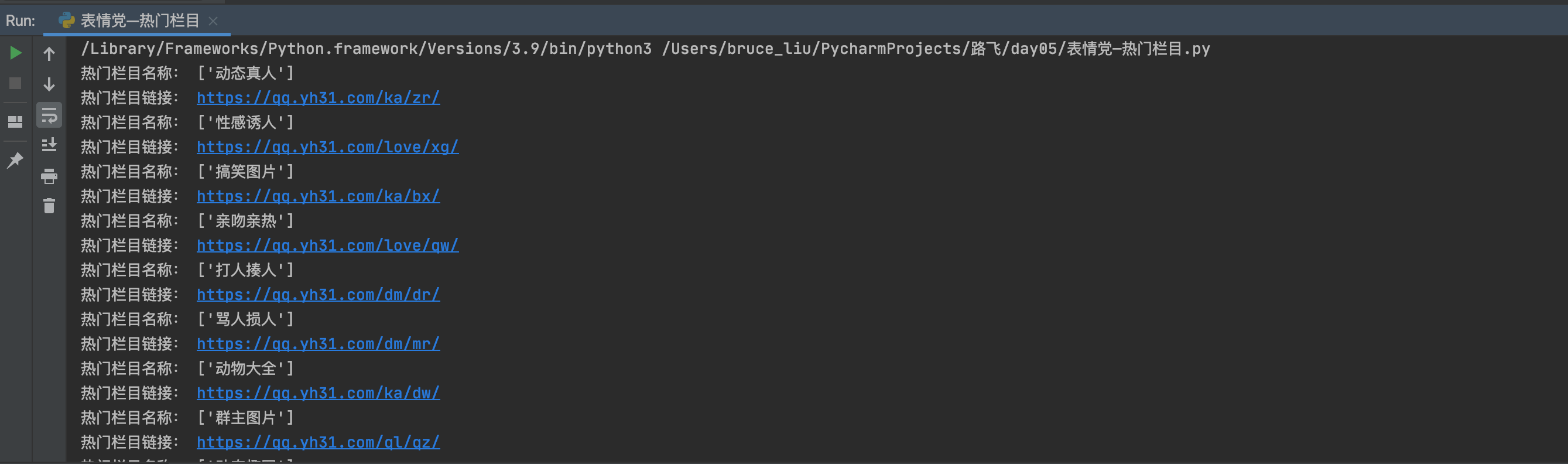
运行结果如下:
文章来源:https://blog.csdn.net/weixin_41905135/article/details/135579286
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【开源】基于JAVA语言的大学生相亲网站
- Go语言学习笔记:函数的定义和调用
- 为什么MOS管很容易失效?有哪些失效?
- 建立海外SD-WAN专线网络的成本分析
- Pandas.DataFrame.idxmin() 最小值索引 详解 含代码 含测试数据集 随Pandas版本持续更新
- c++ 字符串操作
- 应用于车载音响系统上的国产芯片D3121描述
- MK米客方德品牌 SD NAND在对讲机领域的引领作用
- 子母导弹反无人机集群制导策略
- python|切片