【Python机器学习系列】建立梯度提升模型预测心脏疾病(完整实现过程)
一、引言
????????对于表格数据,一套完整的机器学习建模流程如下:

????? ? 针对不同的数据集,有些步骤不适用即不需要做,其中橘红色框为必要步骤,由于数据质量较高,本文有些步骤跳过了,跳过的步骤将单独出文章总结!同时欢迎大家关注翻看我之前的一些相关文章。
前期相关原创文章回顾??点击标题可跳转
【Python机器学习系列】一文彻底搞懂机器学习中表格数据的输入形式(理论+源码)
【Python机器学习系列】一文带你了解机器学习中的Pipeline管道机制(理论+源码)
【Python机器学习系列】一文搞懂机器学习中的转换器和估计器(附案例)
【Python机器学习系列】一文讲透机器学习中的K折交叉验证(源码)
【Python机器学习系列】拟合和回归傻傻分不清?一文带你彻底搞懂它
【Python机器学习系列】建立决策树模型预测心脏疾病(完整实现过程)
【Python机器学习系列】建立支持向量机模型预测心脏疾病(完整实现过程)
【Python机器学习系列】建立逻辑回归模型预测心脏疾病(完整实现过程)
【Python机器学习系列】建立KNN模型预测心脏疾病(完整实现过程)
【Python机器学习系列】建立随机森林模型预测心脏疾病(完整实现过程)
????????GradientBoostingClassifier是一种基于梯度提升算法的分类器,它是scikit-learn库中的一个类。梯度提升是一种集成学习方法,通过组合多个弱学习器(通常是决策树,梯度提升决策树GBDT)来构建一个更强大的分类器。梯度提升模型的基本思想是利用梯度下降来最小化损失函数,以逐步优化模型的预测能力。在每一轮迭代中,模型会计算当前模型对样本的预测值与实际值之间的残差,然后使用一个新的弱学习器来拟合这个残差。通过迭代地拟合残差,每个弱学习器都会以一定的学习率加入到模型中,最终得到一个强大的集成模型。本文将实现基于心脏疾病数据集建立梯度提升模型对心脏疾病患者进行分类预测的完整过程。
二、实现过程
导入必要的库
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report1、准备数据
data = pd.read_csv(r'Dataset.csv')
df = pd.DataFrame(data)df:
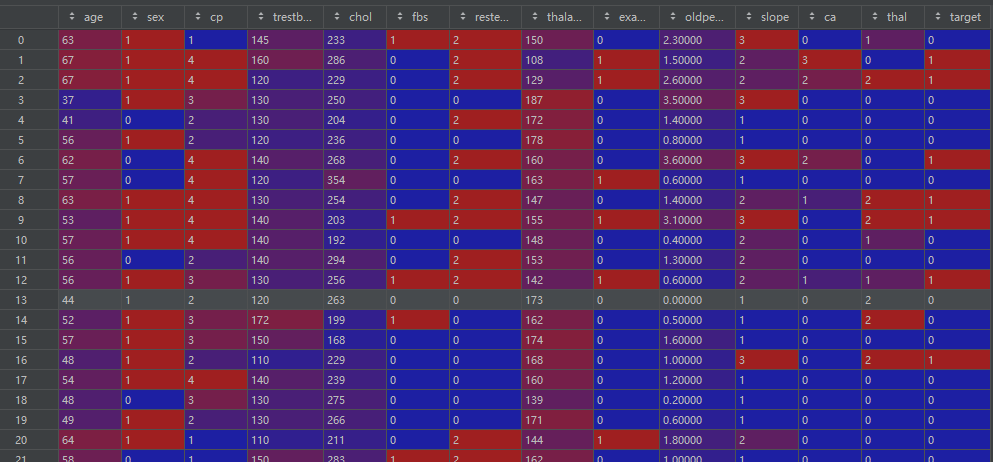
数据基本信息:
print(df.head())
print(df.info())
print(df.shape)
print(df.columns)
print(df.dtypes)
cat_cols = [col for col in df.columns if df[col].dtype == "object"] # 类别型变量名
num_cols = [col for col in df.columns if df[col].dtype != "object"] # 数值型变量名2、提取特征变量和目标变量
target = 'target'
features = df.columns.drop(target)
print(data["target"].value_counts())?#?顺便查看一下样本是否平衡3、数据集划分
# df = shuffle(df)
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=0)4、模型的构建与训练
# 模型的构建与训练
model = GradientBoostingClassifier()
model.fit(X_train, y_train)参数详解:
from sklearn.ensemble import GradientBoostingClassifier
# 全部参数
GradientBoostingClassifier(loss='log_loss',
learning_rate=0.1,
n_estimators=100,
subsample=1.0,
criterion='friedman_mse',
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_depth=3,
min_impurity_decrease=0.0,
init=None,
random_state=None,
max_features=None,
verbose=0,
max_leaf_nodes=None,
warm_start=False,
validation_fraction=0.1,
n_iter_no_change=None,
tol=0.0001,
????????????????????????????ccp_alpha=0.0)-
loss:损失函数的类型。默认为deviance,表示使用对数似然损失函数进行分类。可以选择exponential,表示使用指数损失函数进行分类。 -
learning_rate:学习率,控制每个弱学习器的贡献。较小的学习率会使模型收敛得更慢,但可能会获得更好的性能。默认为0.1。 -
n_estimators:弱学习器(决策树)的数量。默认为100。 -
subsample:用于训练每个弱学习器的样本子集的比例。默认为1.0,表示使用全部样本。可以设置小于1.0的值来降低方差,防止过拟合。 -
criterion:决策树节点分裂的标准。默认为friedman_mse,表示使用Friedman均方误差作为分裂标准。可以选择mse,表示使用均方误差,或mae,表示使用平均绝对误差。 -
max_depth:决策树的最大深度。默认为3。增加深度可以增加模型的复杂度,但也容易导致过拟合。 -
min_samples_split:决策树节点分裂所需的最小样本数。默认为2。如果某个节点的样本数少于该值,则不会再进行分裂。 -
min_samples_leaf:叶节点所需的最小样本数。默认为1。如果叶节点的样本数少于该值,则不会进行进一步的分裂。 -
max_features:每个决策树节点考虑的特征数量。可以是整数、浮点数或字符串。默认为None,表示考虑所有特征。可以选择sqrt,表示考虑特征数量的平方根,或log2,表示考虑特征数量的对数。 -
random_state:随机种子。可以用于重现实验结果。 -
verbose:控制训练过程中的输出信息的详细程度。默认为0,表示不输出任何信息。较大的值会增加输出信息的数量。
5、模型的推理与评价
y_pred = model.predict(X_test)
y_scores = model.predict_proba(X_test)
acc = accuracy_score(y_test, y_pred) # 准确率acc
cm = confusion_matrix(y_test, y_pred) # 混淆矩阵
cr = classification_report(y_test, y_pred) # 分类报告
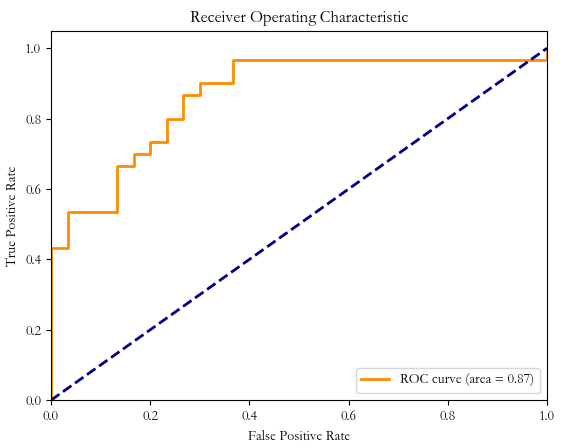
fpr, tpr, thresholds = roc_curve(y_test, y_scores[:, 1], pos_label=1) # 计算ROC曲线和AUC值,绘制ROC曲线
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()cm:
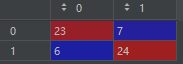
cr:

ROC:
三、小结
????????本文利用scikit-learn(一个常用的机器学习库)实现了基于心脏疾病数据集建立梯度提升模型对心脏疾病患者进行分类预测的完整过程。
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C语言数据结构(3)——线性表其二(单链表)
- RR、优先级调度、多级反馈队列调度算法-第二十二天
- 好用的网站性能监测与服务可用性监测工具盘点
- 王道计算机考研 数据结构C语言复现-第五章-栈
- C++类通过模板成员函数实现任意类型类实例的函数调用
- 我为什么不建议使用框架默认的 DefaultMeterObservationHandler
- STM32-06-STM32_GPIO
- 【贪心】最小生成树Kruskal算法Python实现
- 什么?Figma 的 fig 文件格式居然被破解出来了
- 数据库Mysql学习day01课堂笔记