UniversalTransformer with Adaptive Computation Time(ACT)
发布时间:2024年01月03日
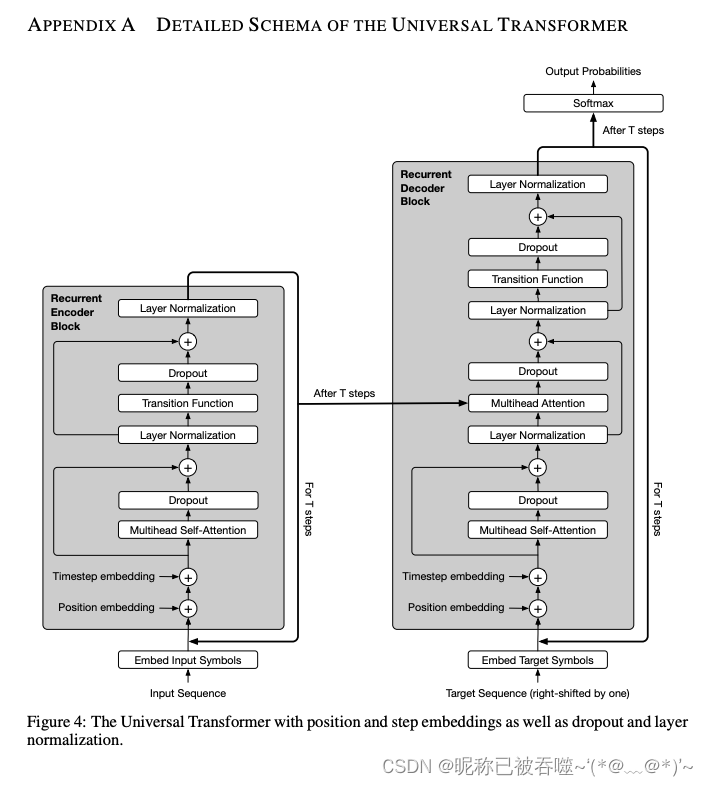
原论文链接:https://arxiv.org/abs/1807.03819
Main code
import torch
import numpy as np
class PositionTimestepEmbedding(torch.nn.Module):
def forward(self, x, t):
device = x.device
sequence_length = x.size(1)
d_model = x.size(2)
position_embedding = np.array([
[
pos / np.power(10000, 2.0 * (j // 2) / d_model) for j in range(d_model)
] for pos in range(sequence_length)
])
position_embedding[:, 0::2] = np.sin(position_embedding[:, 0::2])
position_embedding[:, 1::2] = np.cos(position_embedding[:, 1::2])
timestep_embedding = np.array([
[
t / np.power(10000, 2.0 * (j // 2) / d_model) for j in range(d_model)
]
])
timestep_embedding[:, 0::2] = np.sin(timestep_embedding[:, 0::2])
timestep_embedding[:, 1::2] = np.sin(timestep_embedding[:, 1::2])
embedding = position_embedding + timestep_embedding
return x + torch.tensor(embedding, dtype=torch.float, requires_grad=False, device=device)
class MultiHeadAttention(torch.nn.Module):
def __init__(self, d_model, num_heads, dropout=0.):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
assert self.head_dim * num_heads == self.d_model, "d_model must be divisible by num_heads"
self.query = torch.nn.Linear(d_model, d_model)
self.key = torch.nn.Linear(d_model, d_model)
self.value = torch.nn.Linear(d_model, d_model)
self.dropout = torch.nn.Dropout(dropout)
self.output = torch.nn.Linear(d_model, d_model)
self.layer_norm = torch.nn.LayerNorm(d_model)
def scaled_dot_product_attention(self, q, k, v, mask=None):
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.head_dim ** 0.5)
if mask is not None:
scores = scores.masked_fill(mask, -np.inf)
scores = scores.softmax(dim=-1)
scores = self.dropout(scores)
return torch.matmul(scores, v), scores
def forward(self, q, k, v, mask=None):
batch_size = q.size(0)
residual = q
if mask is not None:
mask = mask.unsqueeze(1)
q = self.query(q).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
k = self.key(k).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
v = self.value(v).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
out, scores = self.scaled_dot_product_attention(q, k, v, mask)
out = (
out.transpose(1, 2)
.contiguous()
.view(batch_size, -1, self.num_heads * self.head_dim)
)
out = self.output(out)
out += residual
return self.layer_norm(out)
class TransitionFunction(torch.nn.Module):
def __init__(self, d_model, dim_transition, dropout=0.):
super().__init__()
self.linear1 = torch.nn.Linear(d_model, dim_transition)
self.relu = torch.nn.ReLU()
self.linear2 = torch.nn.Linear(dim_transition, d_model)
self.dropout = torch.nn.Dropout(dropout)
self.layer_norm = torch.nn.LayerNorm(d_model)
def forward(self, x):
y = self.linear1(x)
y = self.relu(y)
y = self.linear2(y)
y = self.dropout(y)
y = y + x
return self.layer_norm(y)
class EncoderBasicLayer(torch.nn.Module):
def __init__(self, d_model, dim_transition, num_heads, dropout=0.):
super().__init__()
self.self_attention = MultiHeadAttention(d_model, num_heads, dropout)
self.transition = TransitionFunction(d_model, dim_transition, dropout)
def forward(self, block_inputs, enc_self_attn_mask=None):
self_attention_outputs = self.self_attention(block_inputs, block_inputs, block_inputs, enc_self_attn_mask)
block_outputs = self.transition(self_attention_outputs)
return block_outputs
class DecoderBasicLayer(torch.nn.Module):
def __init__(self, d_model, dim_transition, num_heads, dropout=0.):
super().__init__()
self.self_attention = MultiHeadAttention(d_model, num_heads, dropout)
self.attention_enc_dec = MultiHeadAttention(d_model, num_heads, dropout)
self.transition = TransitionFunction(d_model, dim_transition, dropout)
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask=None, dec_enc_attn_mask=None):
dec_query = self.self_attention(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
block_outputs = self.attention_enc_dec(dec_query, enc_outputs, enc_outputs, dec_enc_attn_mask)
block_outputs = self.transition(block_outputs)
return block_outputs
class RecurrentEncoderBlock(torch.nn.Module):
def __init__(self, num_layers, d_model, dim_transition, num_heads, dropout=0.):
super().__init__()
self.layers = torch.nn.ModuleList([
EncoderBasicLayer(
d_model,
dim_transition,
num_heads,
dropout
) for _ in range(num_layers)
])
def forward(self, x, enc_self_attn_mask=None):
for l in self.layers:
x = l(x, enc_self_attn_mask)
return x
class RecurrentDecoderBlock(torch.nn.Module):
def __init__(self, num_layers, d_model, dim_transition, num_heads, dropout=0.):
super().__init__()
self.layers = torch.nn.ModuleList([
DecoderBasicLayer(
d_model,
dim_transition,
num_heads,
dropout
) for _ in range(num_layers)
])
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
for l in self.layers:
dec_inputs = l(dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
return dec_inputs
class AdaptiveNetwork(torch.nn.Module):
def __init__(self, d_model, dim_transition, epsilon, max_hop):
super().__init__()
self.threshold = 1.0 - epsilon
self.max_hop = max_hop
self.halting_predict = torch.nn.Sequential(
torch.nn.Linear(d_model, dim_transition),
torch.nn.ReLU(),
torch.nn.Linear(dim_transition, 1),
torch.nn.Sigmoid()
)
def forward(self, x, mask, pos_time_embed, recurrent_block, encoder_output=None):
device = x.device
halting_probability = torch.zeros((x.size(0), x.size(1)), device=device)
remainders = torch.zeros((x.size(0), x.size(1)), device=device)
n_updates = torch.zeros((x.size(0), x.size(1)), device=device)
previous = torch.zeros_like(x, device=device)
step = 0
while (((halting_probability < self.threshold) & (n_updates < self.max_hop)).byte().any()):
x = x + pos_time_embed(x, step)
p = self.halting_predict(x).squeeze(-1)
still_running = (halting_probability < 1.0).float()
new_halted = (halting_probability + p * still_running > self.threshold).float() * still_running
still_running = (halting_probability + p * still_running <= self.threshold).float() * still_running
halting_probability = halting_probability + p * still_running
remainders = remainders + new_halted * (1 - halting_probability)
halting_probability = halting_probability + new_halted * remainders
n_updates = n_updates + still_running + new_halted
update_weights = p * still_running + new_halted * remainders
if encoder_output is not None:
x = recurrent_block(x, encoder_output, mask[0], mask[1])
else:
x = recurrent_block(x, mask)
previous = ((x * update_weights.unsqueeze(-1)) + (previous * (1 - update_weights.unsqueeze(-1))))
step += 1
return previous
class Encoder(torch.nn.Module):
def __init__(self, epsilon, max_hop, num_layers, d_model, dim_transition, num_heads, dropout=0.):
super().__init__()
assert 0 < epsilon < 1, "0 < epsilon < 1 !!!"
self.pos_time_embedding = PositionTimestepEmbedding()
self.recurrent_block = RecurrentEncoderBlock(
num_layers,
d_model,
dim_transition,
num_heads,
dropout
)
self.adaptive_network = AdaptiveNetwork(d_model, dim_transition, epsilon, max_hop)
def forward(self, x, enc_self_attn_mask=None):
return self.adaptive_network(x, enc_self_attn_mask, self.pos_time_embedding, self.recurrent_block)
class Decoder(torch.nn.Module):
def __init__(self, epsilon, max_hop, num_layers, d_model, dim_transition, num_heads, dropout=0.):
super().__init__()
assert 0 < epsilon < 1, "0 < epsilon < 1 !!!"
self.pos_time_embedding = PositionTimestepEmbedding()
self.recurrent_block = RecurrentDecoderBlock(
num_layers,
d_model,
dim_transition,
num_heads,
dropout
)
self.adaptive_network = AdaptiveNetwork(d_model, dim_transition, epsilon, max_hop)
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
return self.adaptive_network(dec_inputs, (dec_self_attn_mask, dec_enc_attn_mask),
self.pos_time_embedding, self.recurrent_block, enc_outputs)
class AdaptiveComputationTimeUniversalTransformer(torch.nn.Module):
def __init__(self, d_model, dim_transition, num_heads, enc_attn_layers, dec_attn_layers, epsilon, max_hop, dropout=0.):
super().__init__()
self.encoder = Encoder(epsilon, max_hop, enc_attn_layers, d_model, dim_transition, num_heads, dropout)
self.decoder = Decoder(epsilon, max_hop, dec_attn_layers, d_model, dim_transition, num_heads, dropout)
def forward(self, src, tgt, enc_self_attn_mask=None, dec_self_attn_mask=None, dec_enc_attn_mask=None):
enc_outputs = self.encoder(src, enc_self_attn_mask)
return self.decoder(tgt, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
Mask
# from https://zhuanlan.zhihu.com/p/403433120
def get_attn_subsequence_mask(seq): # seq: [batch_size, tgt_len]
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # 生成上三角矩阵,[batch_size, tgt_len, tgt_len]
subsequence_mask = torch.from_numpy(subsequence_mask).bool() # [batch_size, tgt_len, tgt_len]
return subsequence_mask
def get_attn_pad_mask(seq_q, seq_k): # seq_q: [batch_size, seq_len] ,seq_k: [batch_size, seq_len]
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # 判断 输入那些含有P(=0),用1标记 ,[batch_size, 1, len_k]
return pad_attn_mask.expand(batch_size, len_q, len_k)
文章来源:https://blog.csdn.net/weixin_41369892/article/details/135368784
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- NetApp 存储和数据管理技术助力 Be The Match 改进研究分析,提高数据库性能
- JDBC初体验(一)
- LeetCode刷题--- 买卖股票的最佳时机 IV
- 深入理解Spring Security授权机制原理
- 二阶低通滤波函数
- 基于 InternLM 和 LangChain 搭建你的知识库
- Web概述
- 如何在iPhone设备中查看崩溃日志
- vue3(七)-基础入门之事件总线与动态组件
- mysql学习打卡day8