架构设计评估详解:用合适的资源做合适的事
一、评估服务的性能
1、软件架构评估方法:ATAM评审
ATAM(Architecture Tradeoff Analysis Method)分四个部分:表述部分、调查分析、场景讨论、报告生成。
表述部分:
PMO(组织者):代表会议议题的起题者,负责把控整场的节奏。
产品:明确项目目标,明确业务上下文及功能点。
架构:对产品功能点做简单的架构表述,以及组件/流程图的梳理,对上下游链路的梳理。
调查分析:
产品、架构:就业务场景列出优先级(H,M,L),优先识别出业务优先级场景,从架构层面给出大致的评估,实现当前场景所需要的技术投入(技术难度,L,M,S),最后,对安全性、性能预估等做简单的评估。
场景讨论:
相关人士:针对高优先级的场景,我们详细讨论架构方案中的技术点。识别风险点和待确定的事项。帮助架构师识别没有识别到的风险点。
报告生成:PMO发出会议纪要。标识出与会人员达成的共识、跟进事项、当前项目的风险点(交付、技术、业务角度)及应对方案。
2、软件架构评估方法:CBAM成本效益分析方法
CBAM是建立在ATAM之上。
ATAM面向的是产品本身,从业务目标出发,延伸到架构决策。
CBAM强调的是成本和收益,强调性价比。
优先级评估:
根据ATAM评估,选取1/3 Top优先级项目。
根据当前业务需求的技术方案,达到最好的情况和最坏的情况,根据现实和期望情况进行评估。
在1/3 Top优先级项目中,再次筛选业务场景。
烧脑计算:
开发架构策略,确定策略的效用。
计算每个场景总收益,计算成本/收益 = ROI(投入产出比)。
选取最终优先级。
3、服务监控指标和调优思路
(1)生产环境监控内容
CPU使用率(热点监控CPU资源占用)、
内存(热点监控大对象/数量、JVM内存泄漏)、
硬盘存储空间、
线程(线程数量和线程状态)。
(2)内存泄漏
老年代内存泄漏:通过GC的快照比对。
PermGen内存泄漏:不太容易导致内存泄漏,如果泄漏了一般是使用很多ClassLoader或者很多反射。
stackoverflow:递归。
Native thread:操作系统不能创建线程。
查找内存泄漏的一般步骤:查找占用内存较高的类 -> 查询当前类的引用栈 ->找到哪一个类产生了最多的引用 -> 看源码。
防范内存泄漏:提交代码时,加上代码故障扫描。
二、系统测试与调优指标
1、测试方案
(1)线下压测
使用jmeter可以进行简单测试,对接口级别、小模块、小组件进行测试。
线下压测,服务器的性能是不一样的,数据库的数据量也不一样等等,所以性能差异比较大。
线下压测,一般都是自己造一些测试样本,场景多样性覆盖不全。
线下压测,单机性能只能做简单的参考。
(2)线上压测
数据来源:
模拟流量,生成大量测试数据。(有可能造成热点)
线上导流,线上用户真实数据作为测试样本。(比如:天猫的双引擎测试、TCPCopy)
测试类型:
单机压测,对集群中的一台服务器进行压测。(只能验证当前单机的性能,比如数据库或者应用)
集群/全链路压测。
其他注意事项:
写测试数据打标,将测试数据和真实数据分开。
读写接口混合处理,暴露并发问题。
数据散列(冷+热数据分离)。
(3)负载测试
是一个流量逐步增加的过程,会标注性能指标在某个范围之内(接口响应时间小于100ms、带宽小于100M、内存CPU……),
在临界资源下最大负载。
(4)压力测试
是一个流量逐步增加的过程,生成性能变化曲线。捕捉到系统最佳状态和系统崩盘负载点。
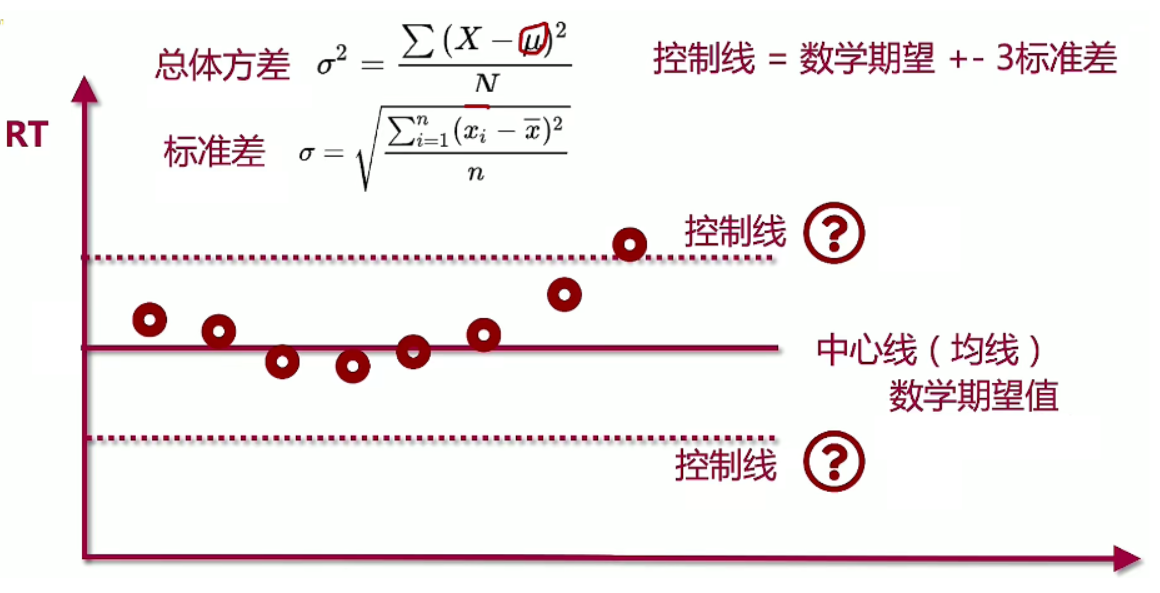
2、构建稳定性测试控制图
条件:
在一定的负载条件下,执行较长时间,获取稳定性指标(控制线)。
目的:
找到不稳定因素,找到系统瓶颈。
测试范围:
确定测试链路(主链路、长时间运行的场景)、确定测试场景。
构建模型:
确定基线和控制线。
关注KPI(RT,系统资源)
最后:
分析测试结果
3、如何确定最佳线程数
以前的单机服务下,通常的确定方案:
CPU密集型:CPU核心数 + 1
最小线程数 = CPU核心数
IO密集型:CPU核心数/(1-阻塞系数) 或者 2* CPU核心数
阻塞系数 = 阻塞时间/(阻塞时间+CPU时间)
当下微服务的场景,通常CPU密集型和IO密集型通常混合使用,很难一下子就确定最佳线程数。
进行性能测试得出结果:
增加线程数,接口QPS不变,甚至RT变长:当前线程数已经超过了最佳线程数。
减少线程数,接口QPS下降:当前线程数还可以增加。
4、如何解决业务接口高RT(响应时间):异步并发
基础:Future、Callback、CompletableFuture 、Guava包下的Future工具类。
5、性能测试:并发用户和RPS模式
客户端视角,有个虚拟用户名法术(VU)
服务端视角,每秒请求数(RPS、TPS)
VU:选取系统峰值流量1-2小时,系统的在线用户数10%,这些用户数作为并发用户数,写入测试脚本。
TPS:高峰时5-10分钟流量,计算当前时间范围的交易量/秒,计算平均TPS。平均TPS2.5作为峰值TPS。
TPS性能测试实践:
刚开始使用10%流量预热,然后主键达到目标峰值TPS。
为什么关注TPS而不是VU?因为用户量与TPS并没有什么关系,系统所能承受的流量取决于TPS。
中小型应用建议使用5k个并发用户,大型应用使用1-5w个并发用户,进行测试。
6、拓展:双11全链路压测概览
(1)目的
业务模块性能预估,系统容量预估,挖掘发现中间件性能瓶颈,寻找上下游依赖方短板,基础服务平台(中台、Tnfra)瓶颈。
借助仿真集群、数据工厂(生成数据)、压测平台(流速+量级,对服务端打流量)、对压测数据打入到线上库的影子库。
(2)真实线上环境压测
流量加工:对压测流量打标(商品标、订单标),对流量识别、透传,做影子Zone,为了实现与真实数据的隔离。
流量采集:数据从线上采样(用户真实购物行为),经过一系列数据清洗和过滤、脱敏。
(3)业务方改造
压测流量打标,业务方要区分压测数据和线上流量。
搜索业务要屏蔽压测数据。
监控预警:水位、弹性伸缩、报警,都需要对压测流量做隔离。
营运报表:GMV、PV等剔除压测流量。
业务方对下单、风控进行放行。(重复下单操作等)
对入口限流(转账额度、用户ID维度的限流)进行开放。
动态校验(人像校验、机器人校验)放行。
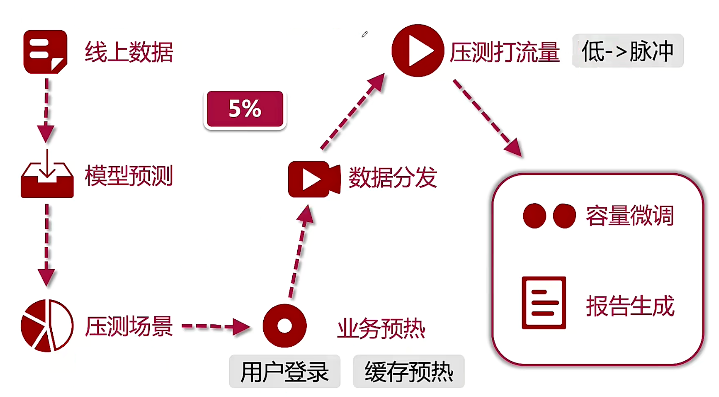
(4)压测数据来源
从线上数据采样,评估压测的数据量级。
数据要进行脱敏采样。
根据线上数据做模型预测,对历史数据和新数据,生成压测模型(数据工厂的模板)。
对采集到的流量做一个增幅,对流量进行复制。
(5)链路流量识别
对压测流量的输入,打入一个测试标记,标记这是一个测试流量。
在网关层,需要对测试流量,关闭DDos判定或者安全防护策略。
在中间件,需要对测试标记进行透传。
数据层,对测试流量,存入影子区域。
影子区域也是正常的数据库和缓存,表结构与线上的完全一致。可擦写。也需要做系统的预热与缓存预热。
(6)压测场景
峰值模拟、降级演练(限流/降级演练、失效转移演练)、拐点压测(压出性能拐点,获取性能极限,需要对限流降级打高)。
(7)多次压测
根据压测遇到的问题,定位、优化、验证。多次压测之后,对每次调整和优化方案进行验证是否可行。
7、商品详情页静态化方案
(1)传统静态化页面
商品变更 - 消息队列 - 模板工厂 - 生成详情页html - 发到Nginx静态资源集群,用户直接访问静态页面。
优点:逻辑简单,节省后端资源。
缺点:变更响应慢,需要模板重绘。批量资源同步会有系统IO瓶颈。
优化:模板拆分为规格模板、详情模板、评论模板,做局部静态化,非全量同步。
同时详情页拆分为规格nginx、详情nginx、评论nginx,用一致性hash的方式,访问到指定的nginx。
优点:灵活性高。
缺点:文件碎片化,资源复杂度太高。
(2)最新方案
展示层做降级前置、分段渲染。
后端做数据异构、多级缓存、数据聚合。
分段渲染:
商品名称、SKU、规格属性、库存、品类、营销优惠活动、富文本+主图URL。
获取商品图、渲染详情TFS。
店铺信息、用户评论、商品推荐。
降级前置:
APP端、Nginx前置降级。
拉取Config(开关、降级)。
数据异构:数据闭环。
在非强一致数据场景、快速返回场景(异步)。
可以降低故障依赖。
数据聚合:
依赖方+业务数据。
弹性化部署结构:
Docker容器、两地三机房、手工弹性(PE审核分钟级上线)。
弹性机房、弹性计算、主链路都要做弹性、两地三备份失效转移。
缓存前置策略:
CDN缓存、网关本地缓存(nginx)、Tair/Redis缓存、业务服务本地缓存(30s过期)、业务服务redis(2min过期)、数据库。
缓存并不是直接在业务服务中使用,而是提前。
三、阿里系:系统容量评估
1、系统容量规划
双十一,链路长,峰值脉冲。
从经济因素考虑。
弹性扩缩容的容量,分配多少机器,什么时候加机器,什么时候减机器。
保证稳定性。

流量预估:
历史数据回测,预估大致流量。如果峰值脉冲与预估流量误差较大,就有可能造成系统崩溃,需要执行限流降级预案。
系统容量评估:
漏斗模型流量分配,获取流量预估结果。
得到一个精确的集群机器需要预置的数量(业务容量/单机吞吐量),一般靠单机压测-2C8G。
全链路压测:
上下游所有业务方的核心系统都参与其中,尽可能模拟双11。
(数据 工厂 + 压测平台)
限流降级预案:
降级限流做误差兜底。
比如说,用户不断重试,相当于增加了请求量。
限流有两种:请求量超过服务的能力,一种方案是多余的请求直接丢弃,另一种是多余的请求排队。或者按照接口,执行不同的限流方案。
2、Tair集群部署与水位调配
Tair类似于Redis。
集群中服务器的水位,可以动态调配。
3、单机压测场景
(1)传统模拟请求
JMeter、Loadrunner、apachAB。
缺点:与真实服务器性能偏差大(配置、数据)。
(2)线上压测
双十一的压测需要在线上环境,使用真实用户流量进行压测。
**流量复制:**对真实流量的复制和重播。(比如天猫双引擎回归测试框架)
场景真实,但是需要做测试数据与真实数据的数据隔离。
**流量转发:**对某一台单机服务器,对真实流量进行转发,不断地控制流量来对单机服务器进行压测。
优点:不用线上数据隔离,方案简单。
缺点:如果该机器不堪重负,会影响少量用户。
**网关权重:**根据网关的权重,对单机服务器进行流量压测。与流量转发类似。
(3)线上压测注意事项
设定性能阈值(QPS、RT),达到阈值之后就不能无限压下去了,因为线上还有正常用户在使用。
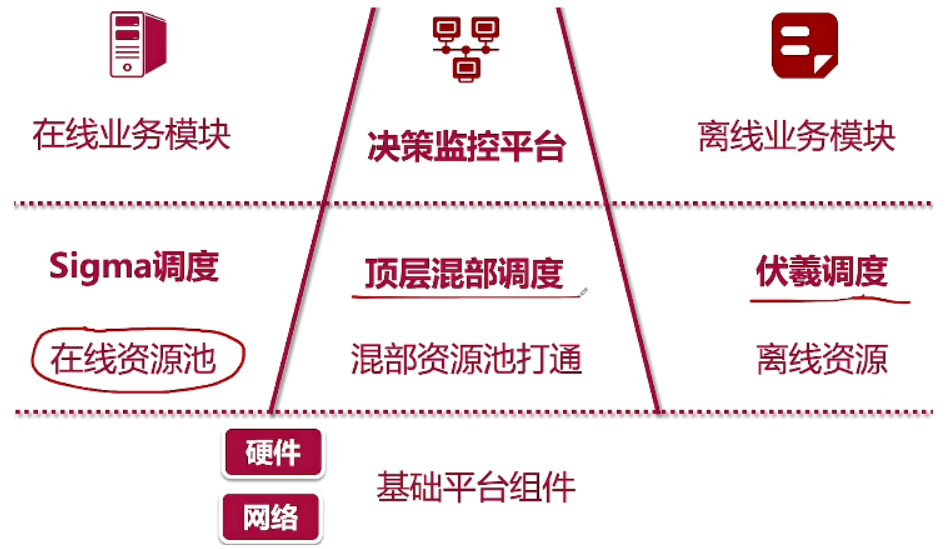
4、混合部署技术
资源分时复用。(浏览页面 、 下单接口按时间分开)
响应时效 - 实时/离线。
实时业务(在线业务),后台业务(离线业务)进行混合部署。
做到资源整合、资源共享(CPU、内存、硬盘)、资源竞争、需要确定资源优先级(高优先级业务优先抢占系统资源)。
实时业务:主链路实时响应;广告、交易支付;前台业务、中间件。
特点:日间流量大,降级容忍性低,脉冲峰值高。
后台业务:离线计算;报表、统计、对账。
特点:半夜执行,大部分可降级。
5、生产级限流维度
(1)网关流控
限流:全局维度、QPS、URI、用户ID、IP维度、连接数限流、调用方限流、热点限流(Sentinel)
准入:黑名单、白名单、DDos高防
整形:预热/冷启动、匀速通过
(2)后端降级/客户端限流等
例如使用Guava包、使用redis做限流。
(3)前端柔性
错峰、削峰。
按钮点击之后,并不是立马就发送请求,而是做一个动画(比如说抢红包)。
前端设置缓冲。
前端设置验证码、点击几率。
6、线上应急预案
(1)预防问题
精准评估,经过全链路与日常压测,对集群的能力做容量评估,做容量微调。
数据和服务做缓存、异构、异步化、分库分表、DR(容灾)。
系统阈值限流、降级熔断(自动+手动)、弹性扩缩。
(2)发现问题
监控预警,集群水位监控、QPS/RT监控。
对业务进行埋点,硬件资源监控。
(3)快速响应
应急预案的三级响应,设置FO(故障转移)通常联带DR,手动降级。
做好容灾演练、RCA复盘。
(4)识别故障等级
核心主链路或者是外围支持系统。对系统进行分级。
根据影响范围、预估1H的资损来判断故障等级。
P0级故障要5min内响应。
P1级故障15min内响应。
P2在30min内响应。
P3在60min内响应。
(5)故障预案
应用层:人工降级预案(降级异步写,需要对数据一致性要求不高,读降级)。
7、三高系统的稳定性保障
稳定性指标:接口响应时间(时延)、网络传输。
空间换时间(多级缓存)、异步编排等降低时延。
时间换空间。
减少资源竞争:降低锁竞争(cas+线程出让),减少锁定资源的范围。
节省线程资源:池化技术,线程隔离。
服务无状态化:实现弹性,快上快下。
异步化:异步编排、状态机推进。
缓存更新(缓存与数据库一致性):使用canal。
队列化:本地/MQ。
考虑幂等性、重试。
8、线上异常的回退机制
基于版本控制的异常回退。
版本化部署:发布历史,快速回退稳定版本。
版本发布:金丝雀测试、灰度发布(蓝绿发布,分批上线)、AB Testing、切流量
数据库DDl变更(DDL&数据订正也是代码):版本控制+发布历史,全量脚本+增量脚本+回退脚本。
9、面试题
(1)全链路调优经验
业务容量预估
单机压测
线上数据+模型回测 - 老业务 :新业务预估
容量精调 - 全链路压测(瓶颈)
水位调配,降级熔断,限流 - 重新压
(2)提高线上资源利用率(架构层面)
水位监控,弹性计算
混合部署
(3)防止流量超过系统承载能力
限流 - 网关层限流、分布式组件限流、客户端多个维度
降级、熔断
流量整形 - 预热、匀速、排队
前端柔性 - 错峰、削峰
弹性计算
(4)系统可用性、稳定性
时延 - 空间换时间
数据压缩 - 时间换空间
宏观层面 - DR、镜像同步、FO
微观层面 - 降低资源竞争、池化、无状态(弹性)、异步化。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- neo4j 图数据库 py2neo 操作 示例代码
- GEE:面对对象(斑块/超像素)尺度的随机森林回归教程
- Docker-nacos集群部署
- MFC模拟消息发送,自定义以及系统消息
- 华为发布《智能世界2030》思维导图笔记
- Meta Reinforce Learning 元学习:学会如何学习
- 视图-练习题
- linux | 软连接与硬链接 | 实测
- 基本概念一:供给与需求 弹性 供需均衡 纳什均衡 萨伊定律
- 阿里云 ACK 云原生 AI 套件中的分布式弹性训练实践