6 - 常用工具类
目录
5.6?Spring 和 Apache 都有提供的集合工具类
1. Scanner 扫描控制台输入
方便在控制台扫描用户输入的工具类
1.1 扫描控制台输入
// 创建 Scanner 对象,从标准输入流中读取数据
Scanner scanner = new Scanner(System.in);
System.out.print("请输入一个整数:");
int num = scanner.nextInt(); // 获取用户输入的整数
System.out.println("您输入的整数是:" + num);
scanner.nextLine(); // 读取换行符,避免影响下一次读取
System.out.print("请输入一个字符串:");
String str = scanner.nextLine(); // 获取用户输入的字符串
System.out.println("您输入的字符串是:" + str);
scanner.close(); // 关闭 Scanner 对象其中 System.in 返回的是一个字节输入流 InputStream,和 System.out 刚好对应
1)nextLine
该方法会扫描输入流中的字符,直到遇到行末尾的换行符 \n ,然后将该行的内容作为字符串返回,同时会将 Scanner 对象的位置移动到下一行的开头,以便下一次读取数据时从下一行的开头开始读取
Scanner scanner = new Scanner(System.in); // 创建 Scanner 对象,从标准输入流中读取数据
System.out.println("请输入多行文本,以空行结束:");
StringBuilder sb = new StringBuilder(); // 创建 StringBuilder 对象,用于保存读取的文本
String line = scanner.nextLine(); // 读取输入流中的第一行
while (!line.isEmpty()) { // 如果读取的行不为空,则继续读取下一行
sb.append(line).append("\n"); // 将当前行的内容添加到 StringBuilder 对象中,并换行
line = scanner.nextLine(); // 读取下一行
}
System.out.println("您输入的文本是:\n" + sb.toString()); // 打印读取的文本
scanner.close(); // 关闭 Scanner 对象
2)nextInt
从输入流中读取下一个整数并返回,如果输入流中没有整数,或者不是整数,将抛出 InputMismatchException 异常
3)其他方法
- boolean hasNext():检查输入流是否还有下一个标记
- boolean hasNextLine():检查输入流是否还有下一行
- String next():读取输入流中的下一个标记(使用默认的分隔符,通常是空格或换行符)
- double nextDouble():读取输入流中的下一个双精度浮点数
1.2 扫描文件
try {
// 创建 File 对象,表示要扫描的文件
File file = new File("docs.md");
Scanner scanner = new Scanner(file); // 创建 Scanner 对象,从文件中读取数据
while (scanner.hasNextLine()) { // 判断文件中是否有下一行
String line = scanner.nextLine(); // 读取文件中的下一行
System.out.println(line); // 打印读取的行
}
scanner.close(); // 关闭 Scanner 对象
} catch (FileNotFoundException e) {
System.out.println("文件不存在!");
}将文件作为参数传递给构造方法
除了使用循环+nextLine,我们还可以使用 useDelimiter 方法设置文件结束符 \Z 来读取整个文档
// 创建 Scanner 对象,从文件中读取数据
Scanner scanner = new Scanner(new File("docs.md"));
scanner.useDelimiter("\\Z"); // 设置分隔符为文件结尾
if (scanner.hasNext()) { // 判断文件中是否有下一行
String content = scanner.next(); // 读取文件中的下一行
System.out.println(content); // 打印读取的行
}
scanner.close(); // 关闭 Scanner 对象正则表达式中的 \Z 表示输入的结尾,也就是文件结束符;在 Scanner 类中,也可使用 \Z 作为分隔符,以便于读取整个文档
1.3 查找匹配项
Scanner 还提供了另外四个以 find 开头的查找匹配项的方法:
- findInLine(String): String
- findInLine(Pattern): String
- findWithinHorizon(String, int): String
- findWithinHorizon(Pattern, int): String
String input = "good good study, day day up.";
Scanner scanner = new Scanner(input);
String result;
// 使用 findInLine() 方法查找字符串中的单词
result = scanner.findInLine("study");
System.out.println("findInLine(): " + result); // 输出 "study"
// 使用 findWithinHorizon() 方法查找字符串中的单词
scanner = new Scanner(input);
result = scanner.findWithinHorizon("study", 20);
System.out.println("findWithinHorizon(): " + result); // 输出 "study"
scanner.close(); // 关闭 Scanner 对象这些方法都返回找到的匹配项。如果没有找到匹配项,则返回 null
此外,都会忽略默认的分隔符,因此需要使用正则表达式来指定查找的模式
2. Arrays 数组工具
2.1 创建数组
使用 Arrays 类创建数组可以通过以下三个方法:
- copyOf,复制指定的数组,截取或用 null 填充
- copyOfRange,复制指定范围内的数组到一个新的数组
- fill,对数组进行填充
1)copyOf
String[] intro = new String[] { "你", "好", "世", "界" };
String[] revised = Arrays.copyOf(intro, 3); //这个数字 表示的是容量
String[] expanded = Arrays.copyOf(intro, 5);
System.out.println(Arrays.toString(revised));
//[你, 好, 世]
System.out.println(Arrays.toString(expanded));
//[你, 好, 世, 界, null]其实在ArrayList(内部的数据结构用的就是数组)源码中的 grow() 方法就是调用了 copyOf 方法:ArrayList 初始大小不满足元素的增长时就会扩容
private Object[] grow(int minCapacity) {
return elementData = Arrays.copyOf(elementData,
newCapacity(minCapacity));
}2)copyOfRange
需要三个参数,第一个是指定的数组,第二个是起始位置(包含),第三个是截止位置(不包含)
如果超出数组的长度,仍然使用了 null 进行填充
String[] intro = new String[] { "你", "好", "世", "界" };
String[] abridgement = Arrays.copyOfRange(intro, 0, 3);
System.out.println(Arrays.toString(abridgement));3)fill
String[] stutter = new String[4];
Arrays.fill(stutter, "你好世界");
System.out.println(Arrays.toString(stutter));
// [你好世界, 你好世界, 你好世界, 你好世界]
2.2 比较数组
Arrays 类的 equals()?方法用来判断两个数组是否相等
equals 源码:
public static boolean equals(Object[] a, Object[] a2) {
if (a==a2) //因为是对象,先判断是不是同一个对象
return true;
if (a==null || a2==null)
return false;
int length = a.length;
if (a2.length != length)
return false;
for (int i=0; i<length; i++) {
if (!Objects.equals(a[i], a2[i]))
return false;
}
return true;
}除此,还有 Arrays.hashCode() 方法:
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}如果两个数组的哈希值相等,那几乎可以判断两个数组是相等的
String[] intro = new String[] { "hello", "world" };
System.out.println(Arrays.hashCode(intro));
System.out.println(Arrays.hashCode(new String[] { "hello", "world" }));
2.3 数组排序
Arrays 类的 sort()?方法用来对数组进行排序
基本数据类型是按照双轴快速排序的,引用数据类型是按照 TimSort 排序的,使用了 Peter McIlroy 的“乐观排序和信息理论复杂性”中的技术
String[] intro1 = new String[] { "d", "a", "c", "b" };
String[] sorted = Arrays.copyOf(intro1, 4);
Arrays.sort(sorted);
System.out.println(Arrays.toString(sorted));
// [a, b, c, d]
2.4 数组检索
排序后可以使用?Arrays 类的 binarySearch() 方法进行二分查找,否则只能线性查找
String[] intro1 = new String[] { "d", "a", "c", "b" };
String[] sorted = Arrays.copyOf(intro1, 4);
Arrays.sort(sorted);
int exact = Arrays.binarySearch(sorted, "d");
System.out.println(exact);
int caseInsensitive = Arrays.binarySearch(sorted, "D", String::compareToIgnoreCase);
//这个是忽略大小写
System.out.println(caseInsensitive);
2.5?数组转流
Arrays 类的 stream() 方法可以将数组转换成流:
String[] intro = new String[] { "a", "b", "c", "d" };
System.out.println(Arrays.stream(intro).count());
还可以指定起始下标和结束下标:
System.out.println(Arrays.stream(intro, 1, 2).count());2.6 打印数组
Arrays 类的 toString() 方法进行打印:
public static String toString(Object[] a) {
if (a == null)
return "null";
int iMax = a.length - 1;
if (iMax == -1)
return "[]";
StringBuilder b = new StringBuilder();
b.append('[');
for (int i = 0; ; i++) {
b.append(String.valueOf(a[i]));
if (i == iMax)
return b.append(']').toString();
b.append(", ");
}
}2.7 数组转 List
String[] intro = new String[] { "a", "b", "c", "d" };
List<String> rets = Arrays.asList(intro);
System.out.println(rets.contains("b"));
注:Arrays.asList() 返回的是 java.util.Arrays.ArrayList,并不是 java.util.ArrayList;它的长度是固定的,无法进行删除或添加
?要想操作元素的话,需要多一步转化,转成真正的 java.util.ArrayList :
List<String> rets1 = new ArrayList<>(Arrays.asList(intro));
rets1.add("e");
rets1.remove("c");
2.8 setAll
Java 8 提供的方法,可以对数组元素进行填充
int[] array = new int[10];
Arrays.setAll(array, i -> i * 10);
System.out.println(Arrays.toString(array));
i 就相当于是数组的下标,值从 0 开始,到 9 结束;输出:
[0, 10, 20, 30, 40, 50, 60, 70, 80, 90]2.9 parallelPrefix
?Java 8 之后提供的,提供了一个函数式编程的入口,通过遍历数组中的元素,将当前下标位置上的元素与它之前下标的元素进行操作,然后将操作后的结果覆盖当前下标位置上的元素
int[] arr = new int[] { 1, 2, 3, 4};
Arrays.parallelPrefix(arr, (left, right) -> left + right);
System.out.println(Arrays.toString(arr));有一个 Lambda 表达式,等同于
int[] arr = new int[]{1, 2, 3, 4};
Arrays.parallelPrefix(arr, (left, right) -> {
System.out.println(left + "," + right);
return left + right;
});
System.out.println(Arrays.toString(arr));3. StringUtils
org.apache.commons.lang3 包下的 StringUtils 工具类,提供了非常丰富的选择
3.1 字符串判空
其实空字符串,不只是 null 一种,还有""," ","null"等等,多种情况。
- isEmpty
- isNotEmpty
- isBlank
- isNotBlank
优先使用 isBlank? isNotBlank ,因为该方法将 " " 也考虑进去
3.2 分割字符串
String str1 = null;
System.out.println(StringUtils.split(str1,",")); //null
System.out.println(str1.split(",")); // 报指针异常
使用 StringUtils 的 split 方法会返回 null,而使用 String 的 split 方法会报指针异常
3.3 判断是否为纯数字
String str1 = "123";
String str2 = "123q";
String str3 = "0.33";
System.out.println(StringUtils.isNumeric(str1)); //true
System.out.println(StringUtils.isNumeric(str2)); //false
System.out.println(StringUtils.isNumeric(str3)); //false
3.4 将集合拼接为字符串
List<String> list = Lists.newArrayList("a", "b", "c");
List<Integer> list2 = Lists.newArrayList(1, 2, 3);
System.out.println(StringUtils.join(list, ",")); //a,b,c
System.out.println(StringUtils.join(list2, " ")); //1 2 33.5 其他方法
- trim(String str):去除字符串首尾的空白字符
- trimToEmpty(String str):去除字符串首尾的空白字符,如果字符串为 null,则返回空字符串
- trimToNull(String str):去除字符串首尾的空白字符,如果结果为空字符串,则返回 null
- equals(String str1, String str2):比较两个字符串是否相等
- equalsIgnoreCase(String str1, String str2):?比较两个字符串是否相等,忽略大小写
- startsWith(String str, String prefix):?检查字符串是否以指定的前缀开头
- endsWith(String str, String prefix):?检查字符串是否以指定的后缀结尾
- contains(String str, CharSequence seq):?检查字符串是否包含指定的字符序列
- indexOf(String str,?CharSequence seq):?返回指定字符序列在字符串中首次出现的索引,如果没有找到,则返回 -1
- lastIndexOf(String str,?CharSequence seq):?回指定字符序列在字符串中最后一次出现的索引,如果没有找到,则返回 -1
- substring(String str, int start, int end):?截取字符串中指定范围的子串
- replace(String str, String searchString, String replacement):?替换字符串中所有出现的搜索字符串为指定的替换字符串
- replaceAll(String str, String regex, String replacement):?使用正则表达式替换字符串中所有匹配的部分
- join(Itrerable<?> iterable, String separator):?使用指定的分隔符将可迭代对象中的元素连接为一个字符串
- split(String str, String separator):?使用指定的分隔符将字符串分割为一个字符串数组
- capitalize(String str):?将字符串的第一个字符转换为大写
- uncapitalize(String str):?将字符串的第一个字符转换为小写
4. Objects 工具类
用于处理对象,主要目的是为了降低代码中的 空指针异常,同时提供一些方法使用
4.1 对象判空
Integer integer = new Integer(1);
if (Objects.isNull(integer)) {
System.out.println("对象为空");
}
if (Objects.nonNull(integer)) {
System.out.println("对象不为空");
}4.2 对象为空时抛异常
Integer integer1 = new Integer(128);
Objects.requireNonNull(integer1);
Objects.requireNonNull(integer1, "参数不能为空");
Objects.requireNonNull(integer1, () -> "参数不能为空");4.3 判断两个对象是否相等
Integer integer1 = new Integer(1);
Integer integer2 = new Integer(1);
System.out.println(Objects.equals(integer1, integer2));但使用这个方法有坑:
Integer integer1 = new Integer(1);
Long integer2 = new Long(1);
System.out.println(Objects.equals(integer1, integer2));//false
当两个对象的类没有正确实现 equals() 方法时,可能会产生不符合预期的结果
默认情况下会使用 Object 类的 equals() 方法,它只比较对象引用是否相同
为了解决这个问题,需要在比较的类里进行重写 equals() 方法
4.4 获取hashCode
String str = new String("hello");
System.out.println(Objects.hashCode(str));
4.5 对象之间的比较
compare(),通常用于自定义排序。就需要一个比较器Comparator 作为参数;如果比较器为 null,就使用自然排序
PersonCompare person1 = new PersonCompare("张三", 30);
PersonCompare person2 = new PersonCompare("李四", 25);
Comparator<PersonCompare> ageComparator = Comparator.comparingInt(p -> p.age);
int ageComparisonResult = Objects.compare(person1, person2, ageComparator);
System.out.println("年龄排序: " + ageComparisonResult);
// 输出:1(表示 person1 的 age 在 person2 之后)
class PersonCompare {
String name;
int age;
PersonCompare(String name, int age) {
this.name = name;
this.age = age;
}
}
4.6 比较两个数组
deepEquals() 用于比较两个数组类型的对象,当对象是非数组的话,行为和 equals() 一样
int[] array1 = {1, 2, 3};
int[] array2 = {1, 2, 3};
int[] array3 = {1, 2, 4};
System.out.println(Objects.deepEquals(array1, array2));
// 输出:true(因为 array1 和 array2 的内容相同)
System.out.println(Objects.deepEquals(array1, array3));
// 输出:false(因为 array1 和 array3 的内容不同)
// 对于非数组对象,deepEquals() 的行为与 equals() 相同
String string1 = "hello";
String string2 = "hello";
String string3 = "world";
System.out.println(Objects.deepEquals(string1, string2));
// 输出:true(因为 string1 和 string2 相同)
System.out.println(Objects.deepEquals(string1, string3));
// 输出:false(因为 string1 和 string3 不同)5. Collections 工具类
位于 java.util 包下,提供了一系列的静态方法,方便对集合进行各种操作
5.1 排序操作
- reverse(List list):反转顺序
- shuffle(List list):随机打乱
- sort(List list):自然升序
- sort(List list, Comparator c):按照自定义的比较器排序
- swap(List list, int i, int j):将 i 和 j 位置的元素交换位置
5.2 查找操作
- binarySearch(List list, Object key):二分查找法,前提是 List 已经排序
- max(Collection coll):返回最大元素
- max(Collection coll, Comparator comp):根据自定义比较器,返回最大元素
- min(Collection coll):返回最小元素
- min(Collection coll, Comparator comp):根据自定义比较器,返回最小元素
- fill(List list, Object obj):使用指定对象填充
- frequency(Collection c, Object obj):返回指定对象出现的次数
5.3 同步控制
Collections 工具类中提供了多个 synchronizedXxx 方法,这些方法会返回一个同步的对象,从而解决多线程中访问集合时的安全问题
SynchronizedList synchronizedList = Collections.synchronizedList(list);
正确的做法是使用并发包下的 CopyOnWriteArrayList, ConcurrentHashMap
5.4 不可变集合
- emptyXxx():制造一个空的不可变集合
- singletonXxx():制造一个只有一个元素的不可变集合
- unmodifiableXxx():为指定集合制作一个不可变集合
5.5 其他
- addAll(Collection<? super T> c, T... elements):往集合中添加元素
- disjoint(Collection<?> c1, Collection<?> c2):判断两个集合是否没有交集
5.6?Spring 和 Apache 都有提供的集合工具类
Apache 的方法比 Spring 的更多一些,以 Apache 的为例
Maven:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.4</version>
</dependency>对两个集合进行操作
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(1);
list.add(3);
List<Integer> list2 = new ArrayList<>();
list2.add(2);
list2.add(4);
//获取并集
Collection<Integer> unionList = CollectionUtils.union(list, list2);
System.out.println(unionList);
//获取交集
Collection<Integer> intersectionList = CollectionUtils.intersection(list, list2);
System.out.println(intersectionList);
//获取交集的补集
Collection<Integer> disjunctionList = CollectionUtils.disjunction(list, list2);
System.out.println(disjunctionList);
//获取差集
Collection<Integer> subtractList = CollectionUtils.subtract(list, list2);
System.out.println(subtractList);6. Hutool
官网,是一个国产的开源类库
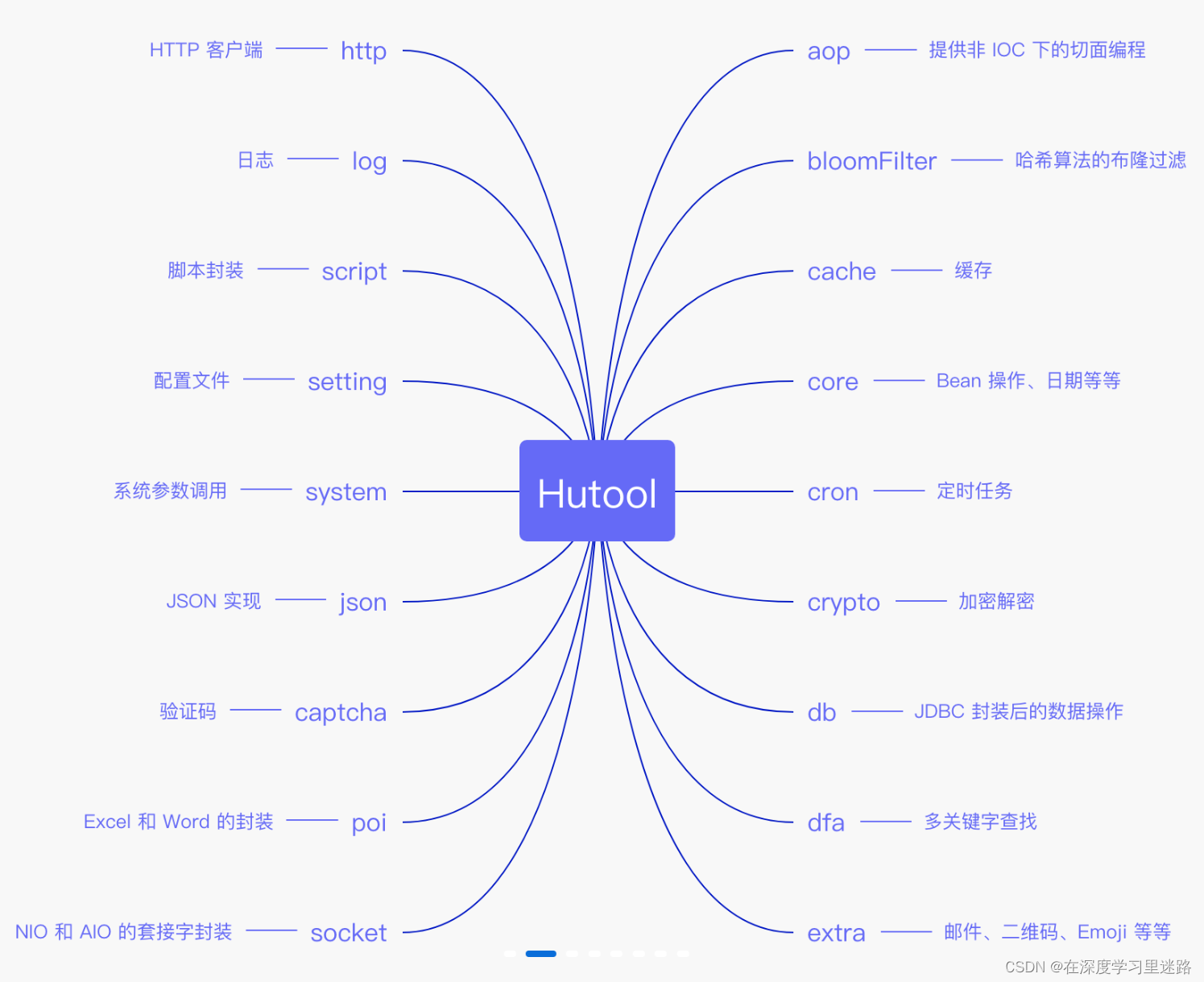
6.1 引入 Hutool
Maven 项目只需要在 pom.xml 文件中添加以下依赖
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.24</version>
</dependency>6.2 类型转换
类型转换在 Java 开发中很常见,尤其是从 HttpRequest 中获取参数的时候,前端传递的是整型,但后端只能先获取到字符串,然后再调用 parseXxx() 方法进行转换,需要判空
Hutool 的 Convert 类可以简化这个操作,可以将任意可能的类型转换为指定类型,同时第二个参数 defaultValue 可用于在转换失败时返回一个默认值
String param = "10";
int paramInt = Convert.toInt(param);
int paramIntDefault = Convert.toInt(param, 0);字符串转换成日期:
String dateStr = "2024年01月12日";
Date date = Convert.toDate(dateStr);把字符串转成 Unicode:
String unicodeStr = "xlin";
String unicode = Convert.strToUnicode(unicodeStr);6.3 日期时间
获取当前日期:
Date date = DateUtil.date();返回的其实是 DateTime,它继承自 Date 对象,重写了 toString() 方法
字符串转日期:
String dateStr = "2024-01-12";
Date date = DateUtil.parse(dateStr);
会自动识别一些常用的格式,比如说:
- yyyy-MM-dd HH:mm:ss
- yyyy-MM-dd
- HH:mm:ss
- yyyy-MM-dd HH:mm
- yyyy-MM-dd HH:mm:ss.SSS
还可以识别带中文的:
- 年月日时分秒
格式化时间差:
String dateStr1 = "2023-09-29 22:33:23";
Date date1 = DateUtil.parse(dateStr1);
String dateStr2 = "2023-10-01 23:34:27";
Date date2 = DateUtil.parse(dateStr2);
long betweenDay = DateUtil.between(date1, date2, DateUnit.MS);
// 输出:2天1小时1分4秒
String formatBetween = DateUtil.formatBetween(betweenDay,
BetweenFormater.Level.SECOND);星座和属相:
// 射手座
String zodiac = DateUtil.getZodiac(Month.DECEMBER.getValue(), 10);
// 蛇
String chineseZodiac = DateUtil.getChineseZodiac(1989);6.4 IO流相关
Hutool 封装了流操作工具类 IoUtil、文件读写操作工具类 FileUtil、文件类型判断工具类 FileTypeUtil 等等
BufferedInputStream in = FileUtil.getInputStream("hutool/origin.txt");
BufferedOutputStream out = FileUtil.getOutputStream("hutool/to.txt");
long copySize = IoUtil.copy(in, out, IoUtil.DEFAULT_BUFFER_SIZE);Hutool 的 FileUtil 类包含以下几类操作:
- 文件操作:包括文件目录的新建、删除、复制、移动、改名等
- 文件判断:判断文件或目录是否非空,是否为目录,是否为文件等等
- 绝对路径:针对 ClassPath 中的文件转换为绝对路径文件
- 文件名:主文件名,扩展名的获取
- 读操作:包括 getReader、readXXX 操作
- 写操作:包括 getWriter、writeXXX 操作
更多查看官方文档
当然也有 谷歌公司开发的 Guava 工具类:?项目地址
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- IP地址定位技术筑牢网络安全防线
- 【MCAL】ADC模块详解
- PIC单片机项目(5)——基于PIC16F877A的多功能防盗门
- OpenCV-Python(34):FAST算法
- RocketMQ源码 事务消息 TransactionalMessage 源码分析
- 短剧开始“海外开花”
- 8年经验分享:想要成为一名合格的软件测试工程师,你得会些啥?
- 系统日志表结构
- 餐饮行业如何做私域流量,这里有妙招(建议收藏)
- C语言函数篇——sqrt()函数