2.2 CUDA C PROGRAM STRUCTURE
我们现在准备学习编写一个CUDA C程序,以利用数据并行性来加快执行速度。CUDA C程序的结构反映了计算机中主机(CPU)和一个或多个设备(GPU)的共存。每个CUDA源文件可以混合主机和设备代码。默认情况下,任何传统的C程序都是仅包含主机代码的CUDA程序。可以将设备功能和数据声明添加到任何源文件中。设备的功能或数据声明清楚地标有特殊的CUDA C关键字。这些通常是表现出大量数据并行性的函数。
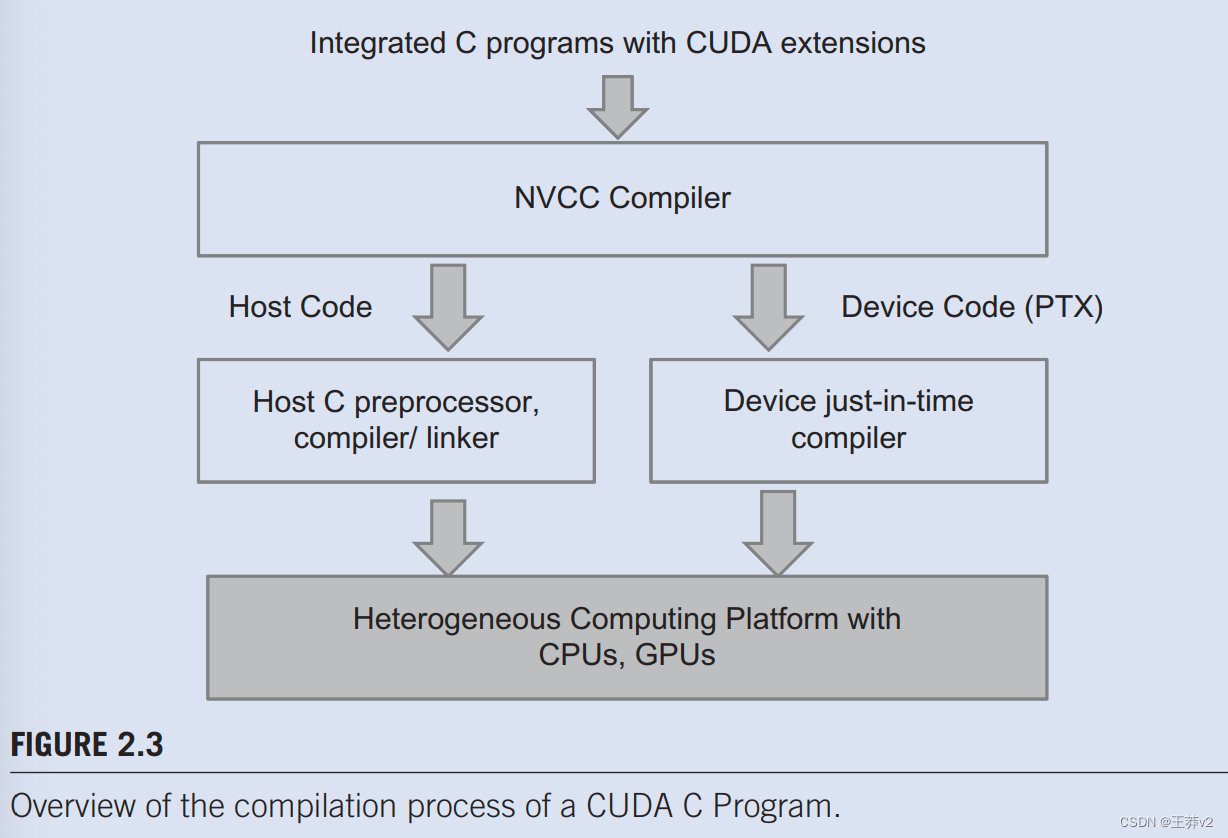
一旦设备功能和数据声明被添加到源文件中,传统的C编译器就不再接受它。代码需要由识别和理解这些附加声明的编译器编译。我们将使用名为NVCC(NVIDIA C编译器)的CUDA C编译器。如图2.3顶部所示,NVCC编译器处理CUDA C程序,使用CUDA关键字将主机代码和设备代码分开。主机代码是直接的ANSI C代码,使用主机的标准C/C++编译器进一步编译,并作为传统的CPU进程运行。设备代码标有数据并行函数(称为内核)及其相关辅助函数和数据结构的CUDA关键字。设备代码由NVCC的运行时组件进一步编译,并在GPU设备上执行。在没有可用的硬件设备或可以在CPU上适当执行内核的情况下,也可以选择使用MCUDA[SSH 2008]等工具在CPU上执行内核。
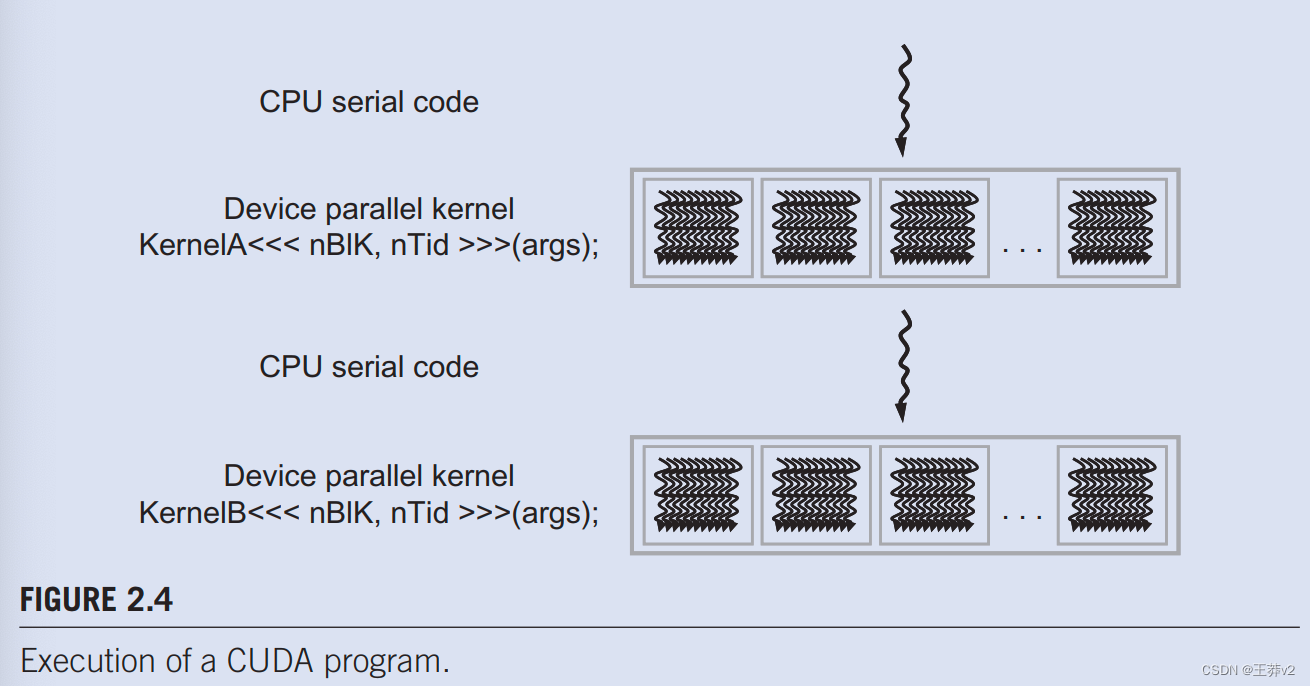
CUDA程序的执行如图2.4.所示。执行从主机代码(CPU串行代码)开始。当内核函数(并行设备代码)被调用或启动时,它由设备上的大量线程执行。内核启动生成的所有线程统称为grid。这些线程是CUDA平台中并行执行的主要载体。图2.4显示了两个线程网格的执行。我们将很快讨论这些网格是如何组织的。当内核的所有线程完成执行时,相应的网格终止,执行继续在主机上,直到启动另一个内核。注意图2.4显示了一个简化的模型,其中CPU执行和GPU执行不重叠。许多异构计算应用程序实际上管理重叠的CPU和GPU执行,以利用CPU和GPU。
启动内核通常会生成大量线程来利用数据并行性。在颜色到灰度转换示例中,每个线程可用于计算输出数组O的一个像素。在这种情况下,内核将生成的线程数等于图像中的像素数。对于大图像,将生成大量线程。在实践中,为了提高效率,每个线程可以处理多个像素。CUDA程序员可以假设,由于高效的硬件支持,这些线程需要很少的时钟周期来生成和调度。这与传统的CPU线程形成鲜明对比,传统的CPU线程通常需要数千个时钟周期来生成和调度。
线程
线程是处理器如何在现代计算机中执行顺序程序的简化视图。线程由程序的代码、正在执行的代码中的特定点及其变量和数据结构的值组成。就用户而言,线程的执行是连续的。可以使用源级调试器通过一次执行一个语句来监控线程的进度,查看接下来将执行的语句,并在执行过程中检查变量和数据结构的值。
线程在编程中已经使用了多年。如果程序员想在应用程序中开始并行执行,他/她使用线程库或特殊语言创建和管理多个线程。在CUDA中,每个线程的执行也是顺序的。CUDA程序通过启动内核函数启动并行执行,这导致底层运行时机制创建许多线程,并行处理数据的不同部分。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- L1-030 一帮一(Java)
- 【Python基础】一文搞懂:Python 中循环的使用方法(for 和 while 的用法及区别)
- ubuntu20.04.3
- 【每日一题】1901. 寻找峰值 II-2023.12.19
- 做一个简单的倒计时
- 【趣味随笔】谈谈对固件的认识
- RabbitMQ部署指南
- Altium Designer快速入门及项目实战教程之原理图绘制(二)
- 基于SpringBoot的停车位预约管理系统
- 15. 蒙特卡诺简介