数模学习day12-相关系数
????????本讲我们将介绍两种最为常用的相关系数:皮尔逊pearson相关系数和斯皮尔曼spearman等级相关系数。它们可用来衡量两个变量之间的相关性的大小,根据数据满足的不同条件,我们要选择不同的相关系数进行计算和分析(建模论文中最容易用错的方法)。
? ? ? ? 注:本文源于数学建模学习交流相关公众号观看学习视频后所作
目录
雅克‐贝拉检验(Jarque‐Bera test):JB检验(大样本n>30)
总体和样本
总体
所要考察对象的全部个体叫做总体。
我们总是希望得到总体数据的一些特征(例如均值方差等)
样本
从总体中所抽取的一部分个体叫做总体的一个样本。
计算这些抽取的样本的统计量来估计总体的统计量:
例如使用样本均值、样本标准差来估计总体的均值(平均水平)和总体的标准差(偏离程度)。
例子:
我国10年进行一次的人口普查得到的数据就是总体数据。大家自己在QQ群发问卷叫同学帮忙填写得到的数据就是样本数据。
皮尔逊Pearson相关系数
总体皮尔逊Pearson相关系数

????????直观理解协方差:如果X、Y变化方向相同,即当X大于(小于)其均值时,Y也
大于(小于)其均值,在这两种情况下,乘积为正。如果X、Y的变化方向一直
保持相同,则协方差为正;同理,如果X、Y变化方向一直相反,则协方差为负;
如果X、Y变化方向之间相互无规律,即分子中有的项为正,有的项为负,那么
累加后正负抵消。
????????注意:协方差的大小和两个变量的量纲有关,因此不适合做比较。
样本皮尔逊Pearson相关系数

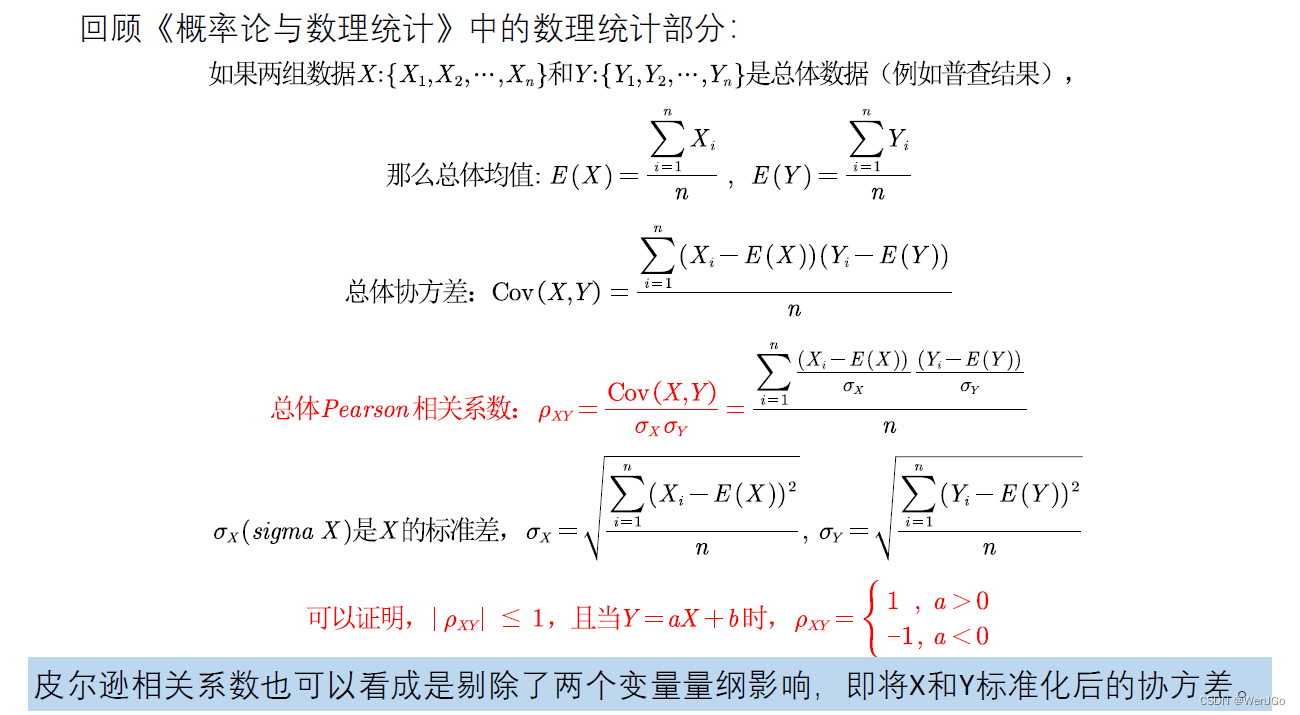
相关性可视化
图片来源:[美]作者Pang-Ning Tan《数据挖掘导论》
关于皮尔逊相关系数的一些理解误区
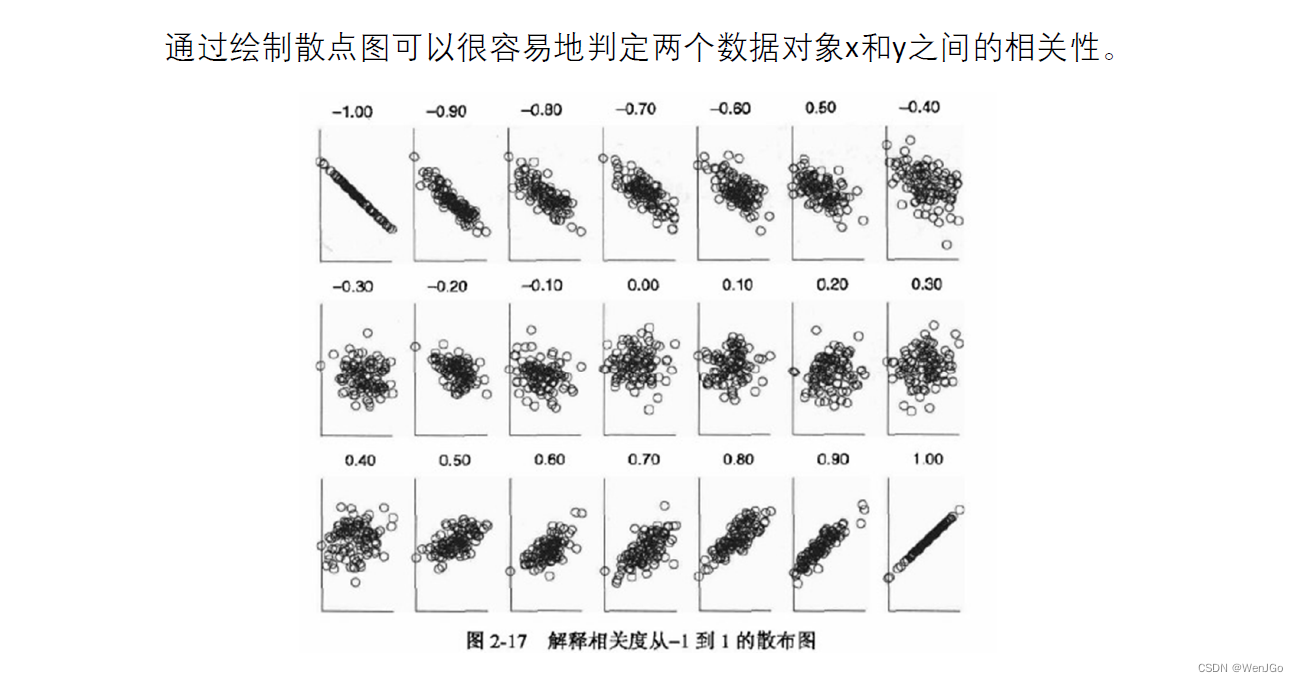
上图来自图中水印位置的博文
上面四个散点图对应的数据的皮尔逊相关系数均为0.816
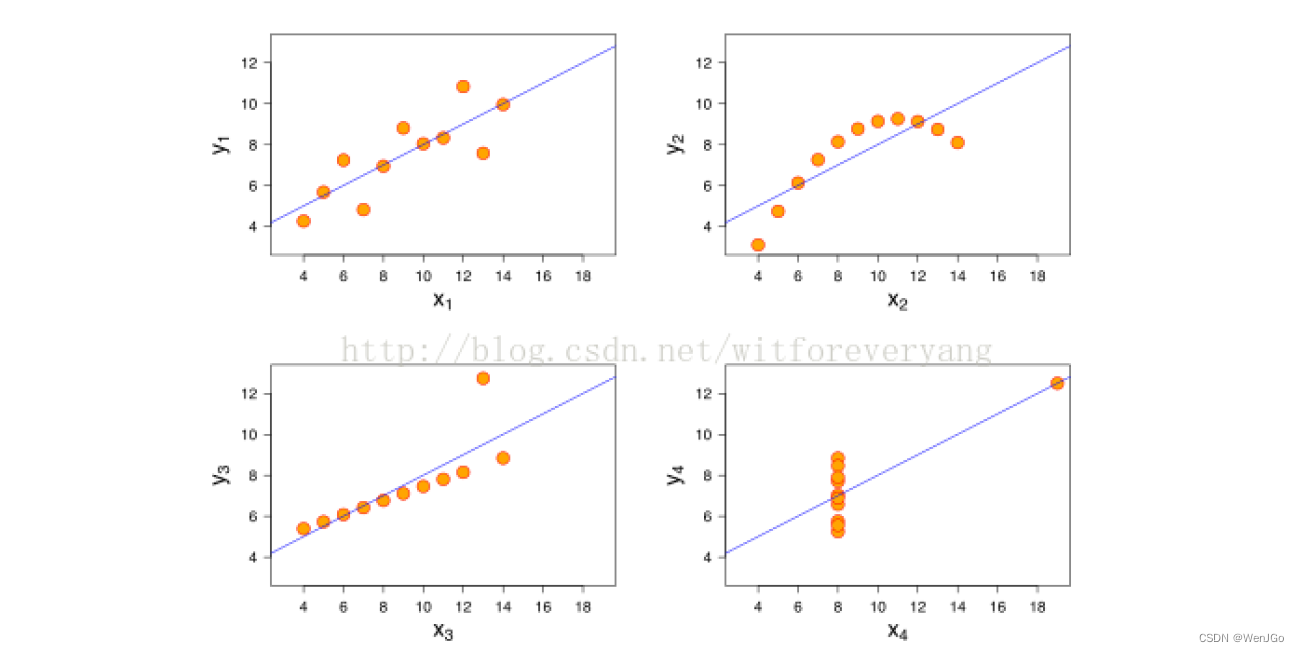
冰激凌的销量和温度之间的关系:
相关系数计算结果为0

注意红色标注的"linear" :
这里的相关系数只是用来衡量两个变量线性相关程度的指标;
也就是说,你必须先确认这两个变量是线性相关的,然后这个相关系数才能告诉你他俩相关程度如何。
易错点
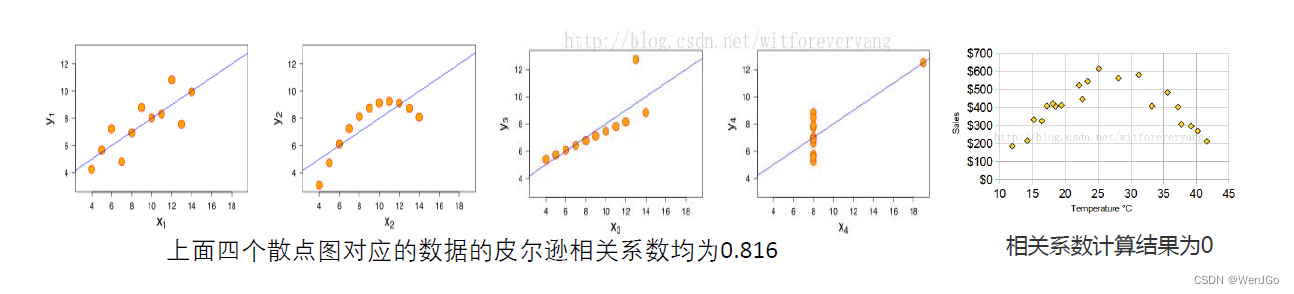
(1)非线性相关也会导致线性相关系数很大,例如图2。
(2)离群点对相关系数的影响很大,例如图3,去掉离群点后,相关系数为0.98。
(3)如果两个变量的相关系数很大也不能说明两者相关,例如图4,可能是受到了异常值的影响。
(4)相关系数计算结果为0,只能说不是线性相关,但说不定会有更复杂的相关关系(非线性相关),例如图5。
总结
(1)如果两个变量本身就是线性的关系,那么皮尔逊相关系数绝对值大的就是相关性强,小的就是相关性弱。
(2)在不确定两个变量是什么关系的情况下,即使算出皮尔逊相关系数,发现很大,也不能说明那两个变量线性相关,甚至不能说他们相关,我们一定要画出散点图来看才行。
对相关系数大小的解释
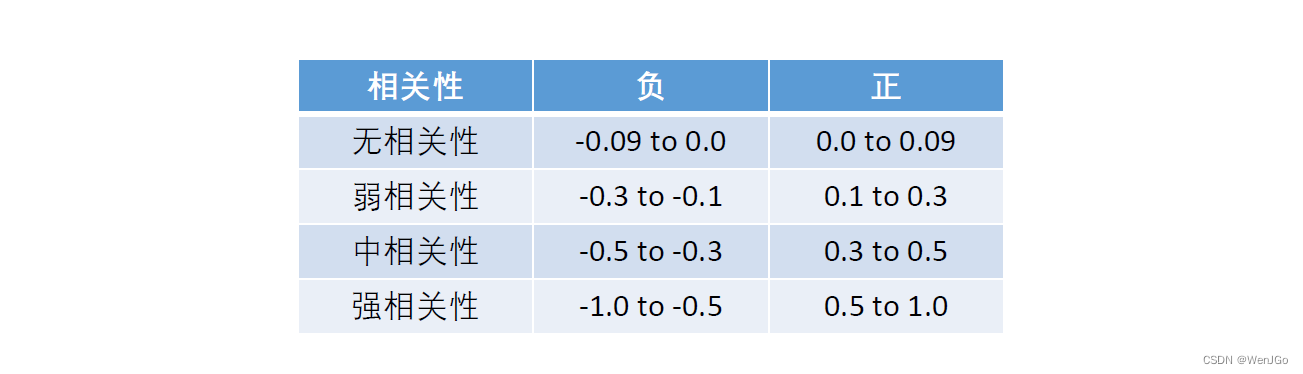
上表所定的标准从某种意义上说是武断的和不严格的。
对相关系数的解释是依赖于具体的应用背景和目的的。
事实上,比起相关系数的大小,我们往往更关注的是显著性。(假设检验)
例题
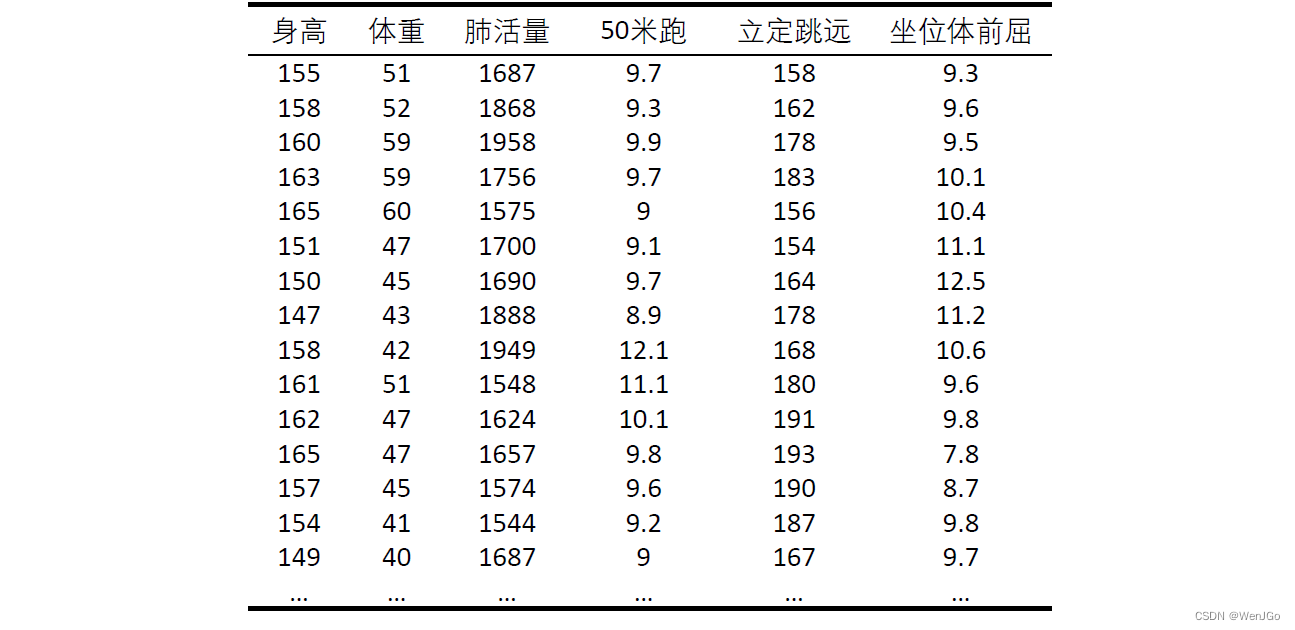
现有某中学八年级所有女学生的体测样本数据,请见下表,试计算各变量之间的皮尔逊相关系数。
描述性统计
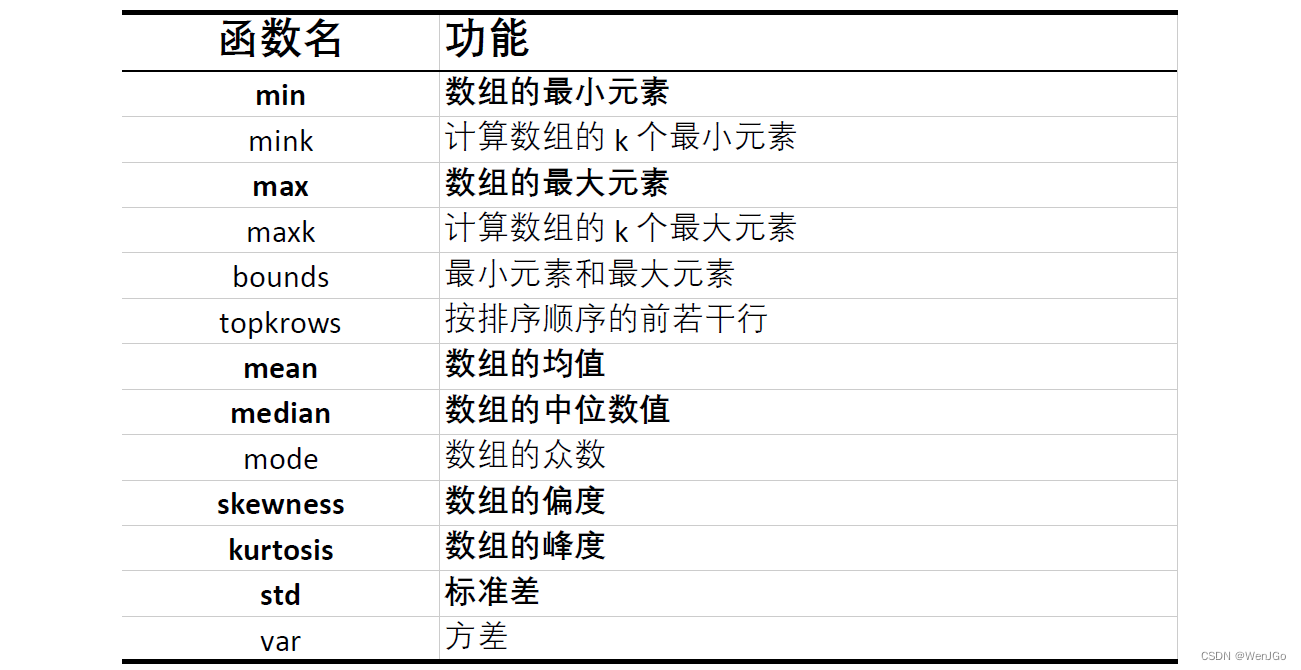
Matlab中基本统计量的函数(一般用粗体表示的):
结果演示
Excel数据分析工具
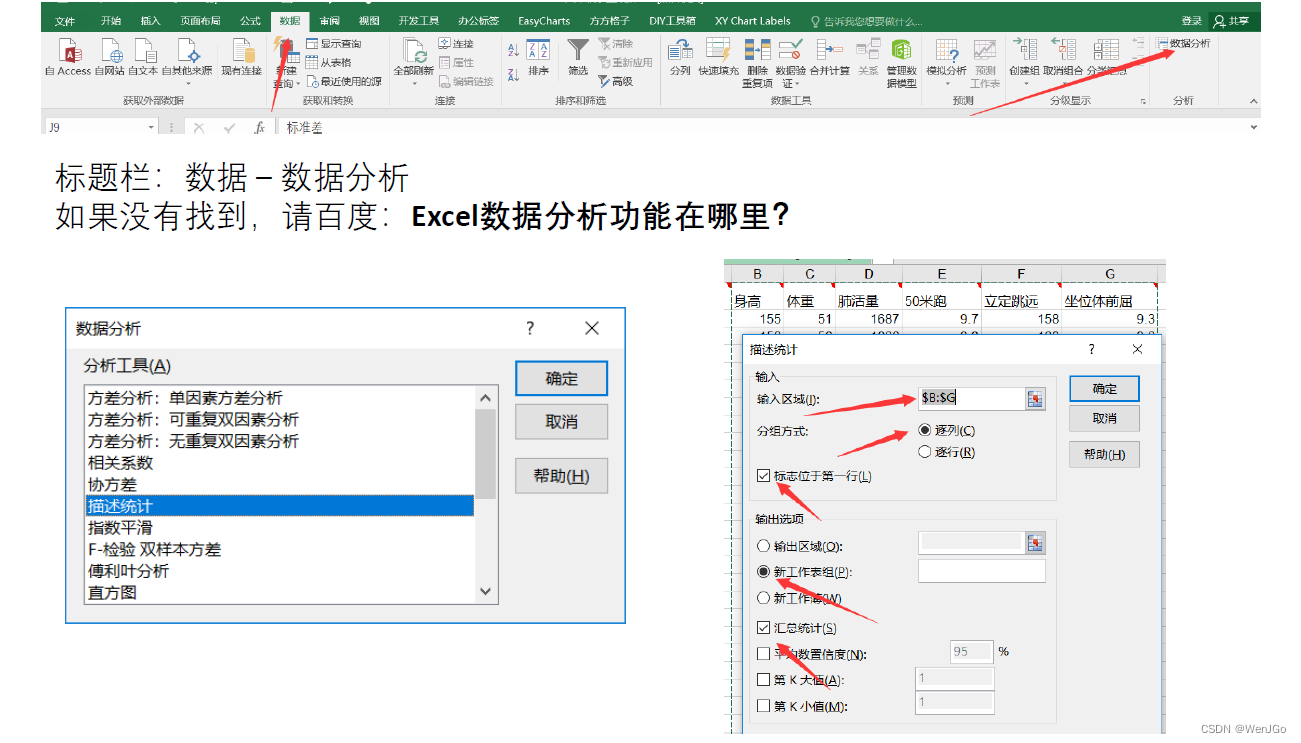
Excel描述性统计结果?
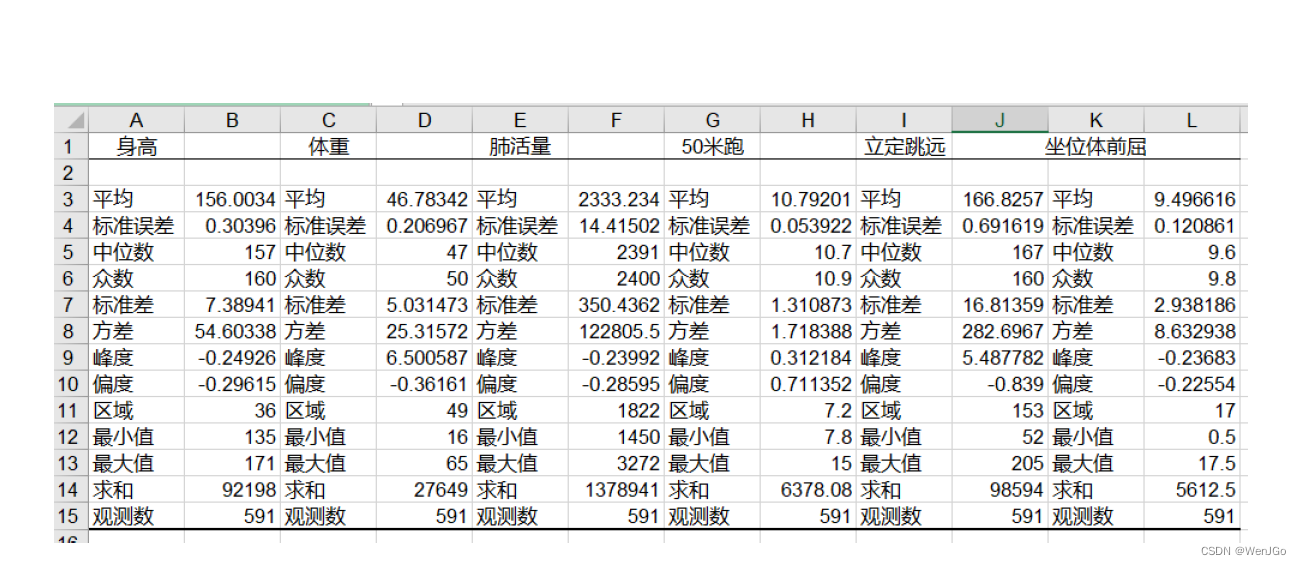
不要直接粘贴这张表格到你的论文中哦,需要精简一点
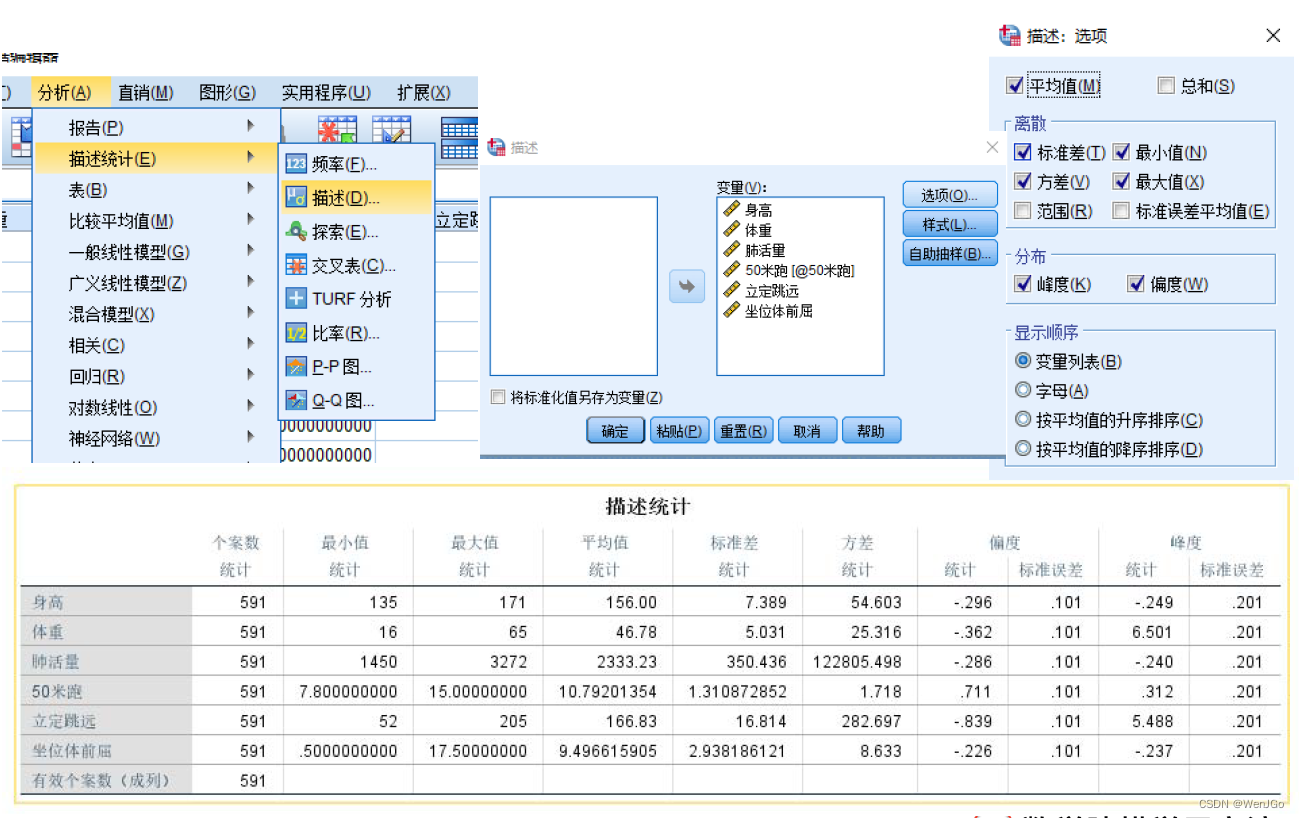
Spss描述性统计结果
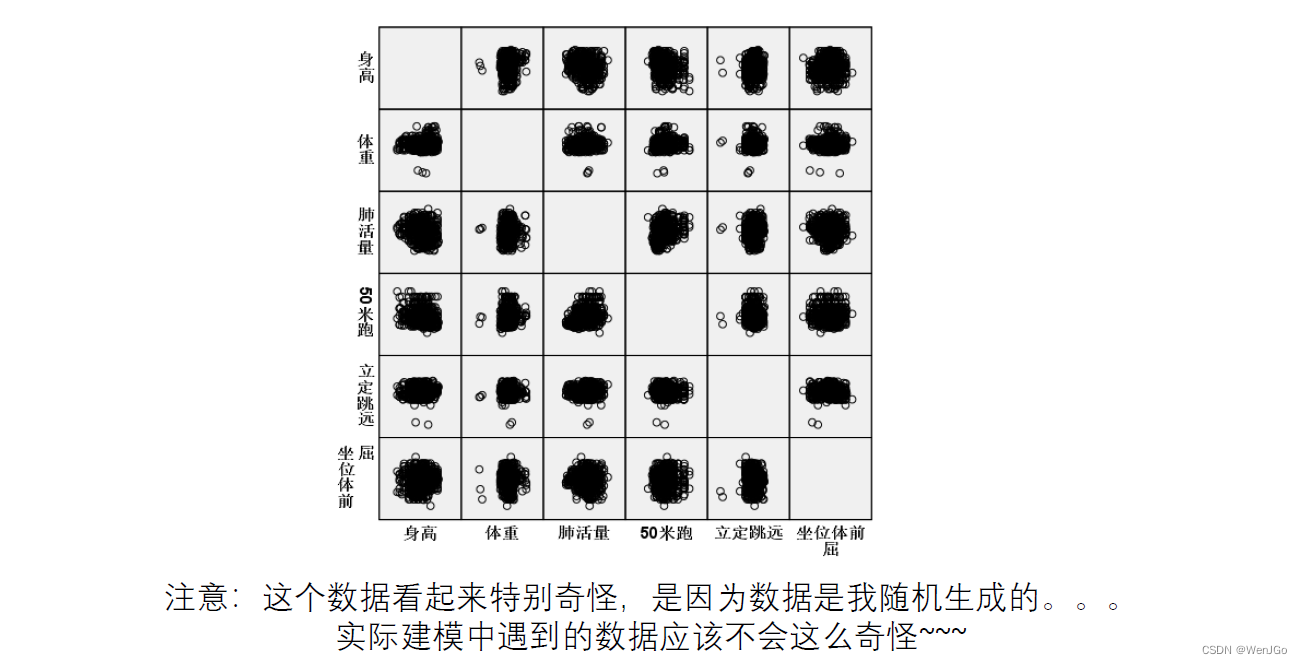
矩阵散点图
在计算皮尔逊相关系数之前,一定要做出散点图来看两组变量之间是否有线性关系
这里使用Spss比较方便: 图形=> 旧对话框=>?散点图/点图=>?矩阵散点图
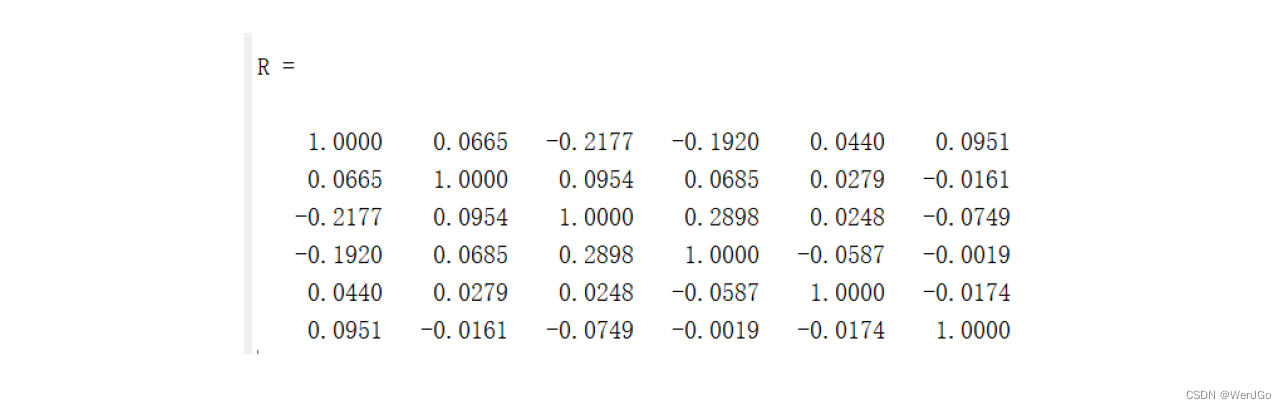
皮尔逊相关系数的计算
corrcoef?函数: correlation coefficient相关系数
// 返回A 的相关系数的矩阵,其中A 的列表示随机变量(指标),行表示观测值(样本)。
R = corrcoef(A)
// 返回两个随机变量A 和B (两个向量)之间的系数。
R = corrcoef(A,B)
// 我们要计算体测的六个指标之间的相关系数,只需要使用下面这个语句:
R = corrcoef(Test)
如何美化相关系数表
对比
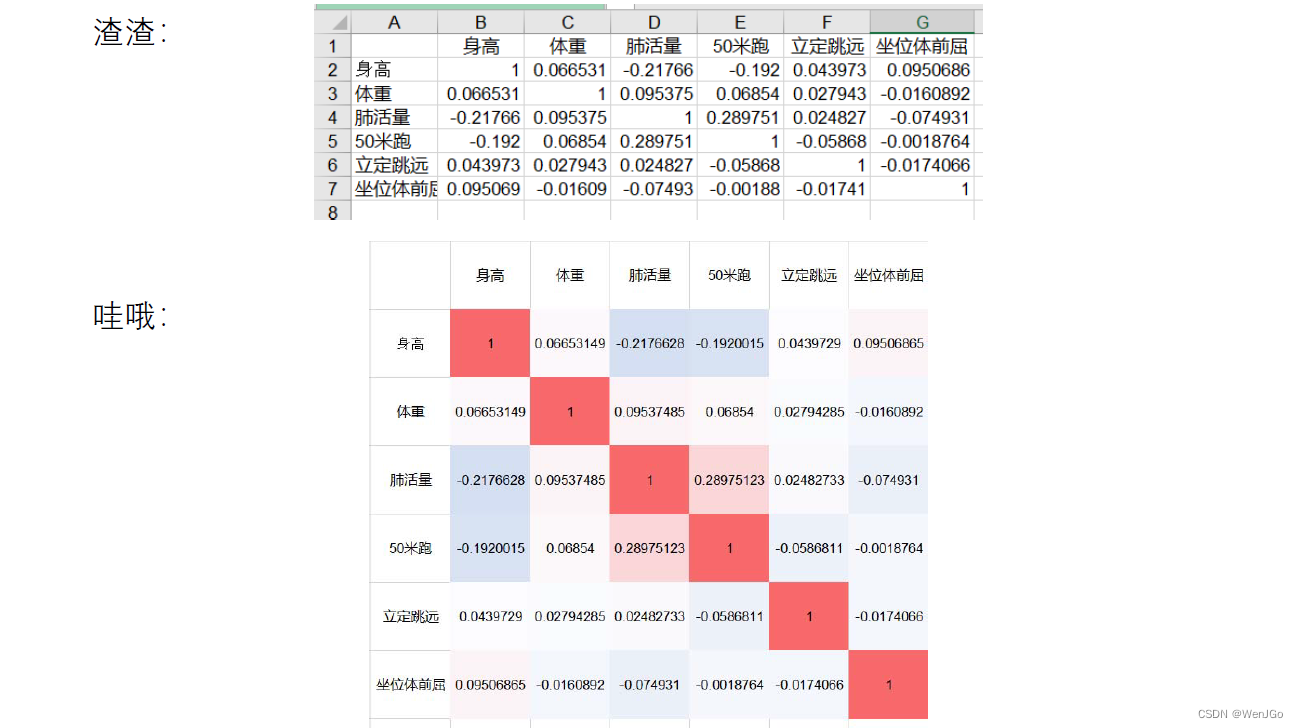
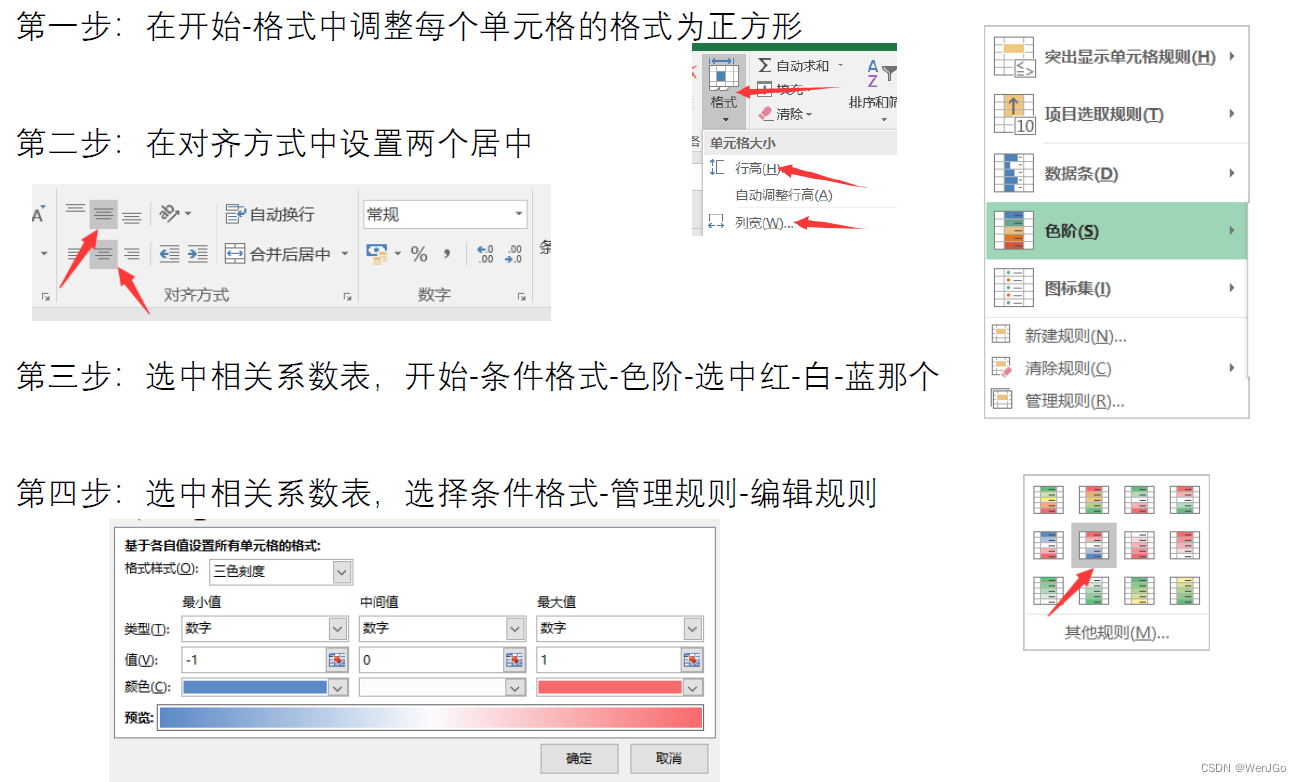
注:其实R语言和Python中有很多类似的包,这里我们用Excel模仿
操作步骤
对皮尔逊相关系数进行假设检验
方法一:

注:在数理统计中,这里的原假设和备择假设中的𝑟应该改为𝜌, 其中𝜌为未知的总体相关系数,实际上我们关心的是总体的统计特征。但为了方便大家理解,在这里我们做了简化,非统计专业的同学理解到这个程度就足够了。
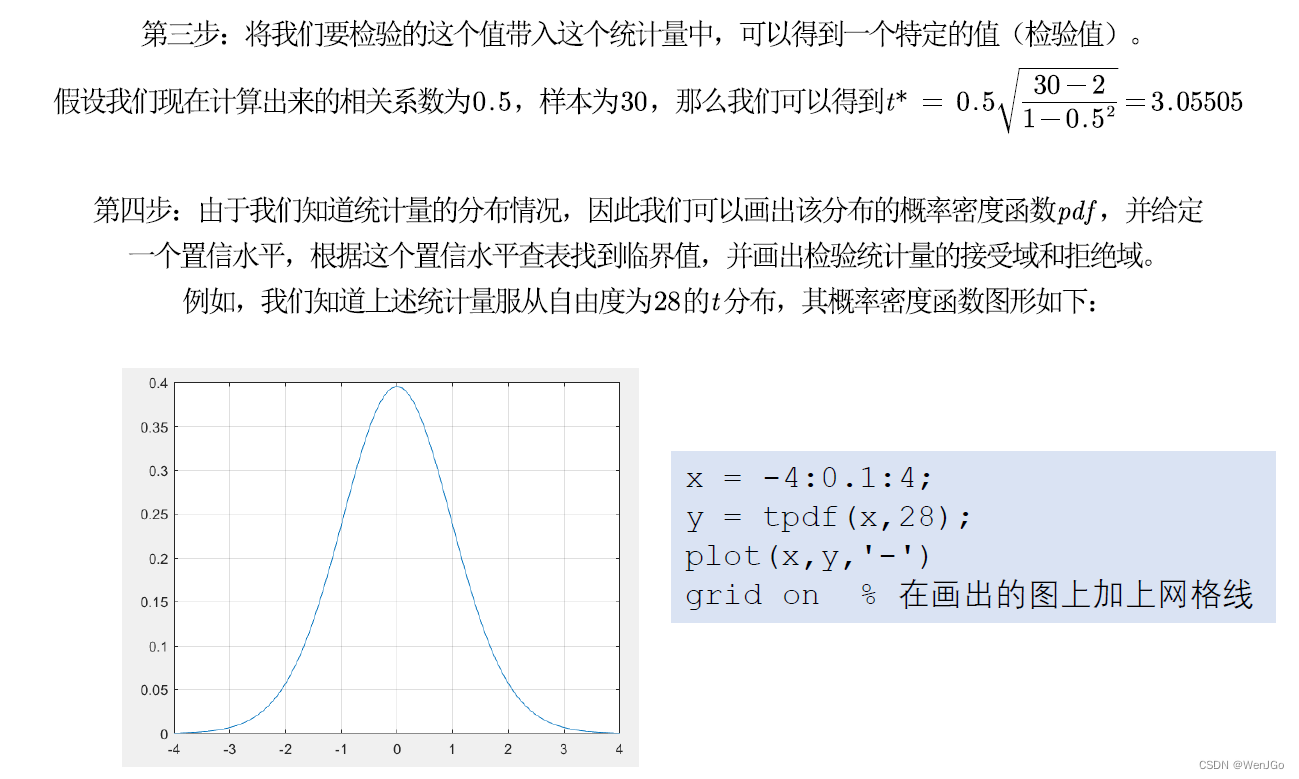
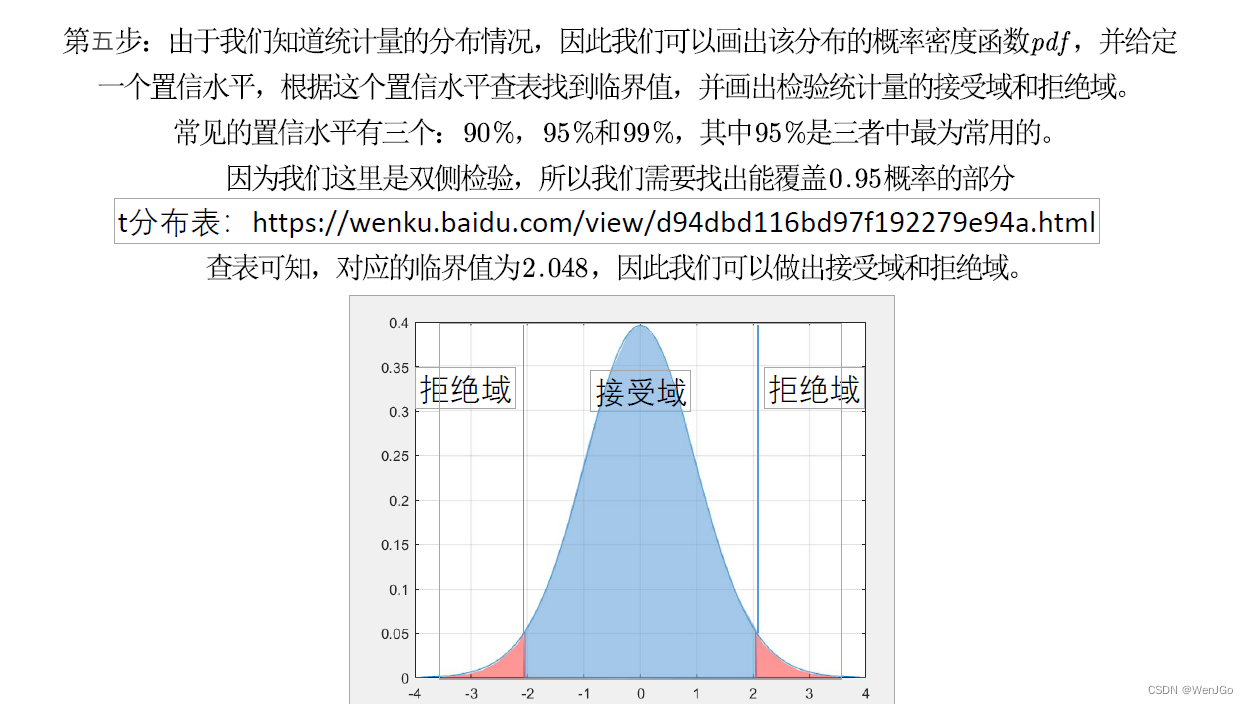
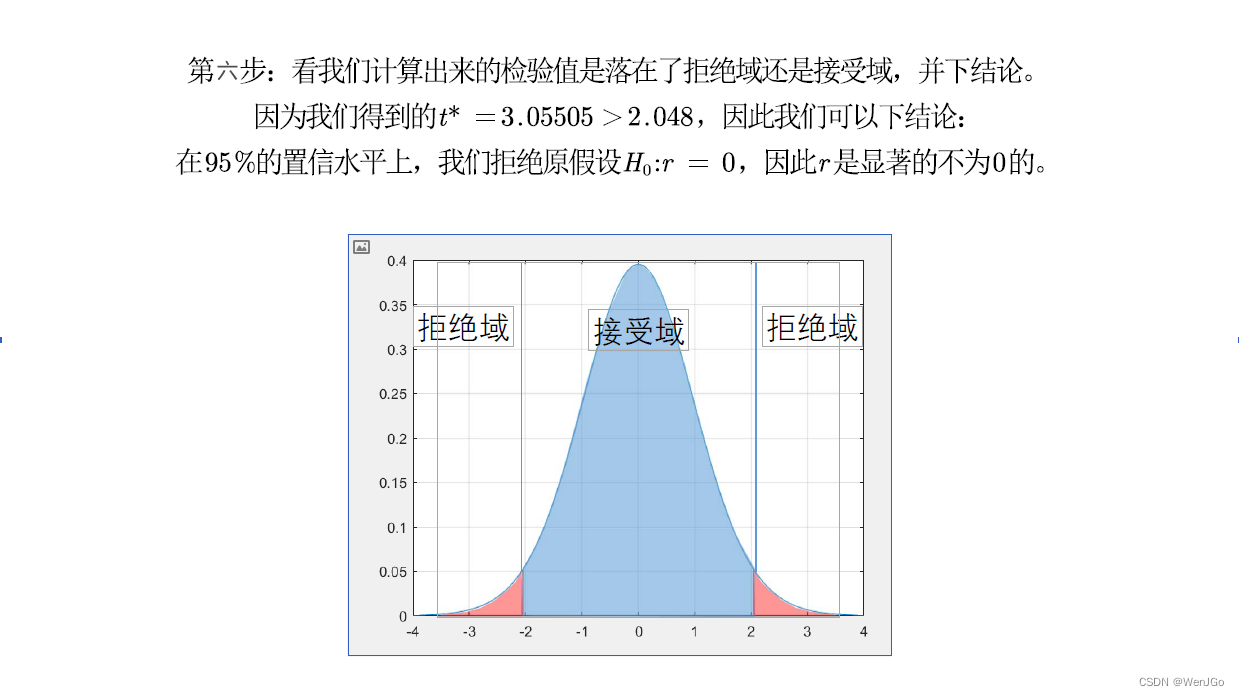
方法二:p值判断法(更好用)
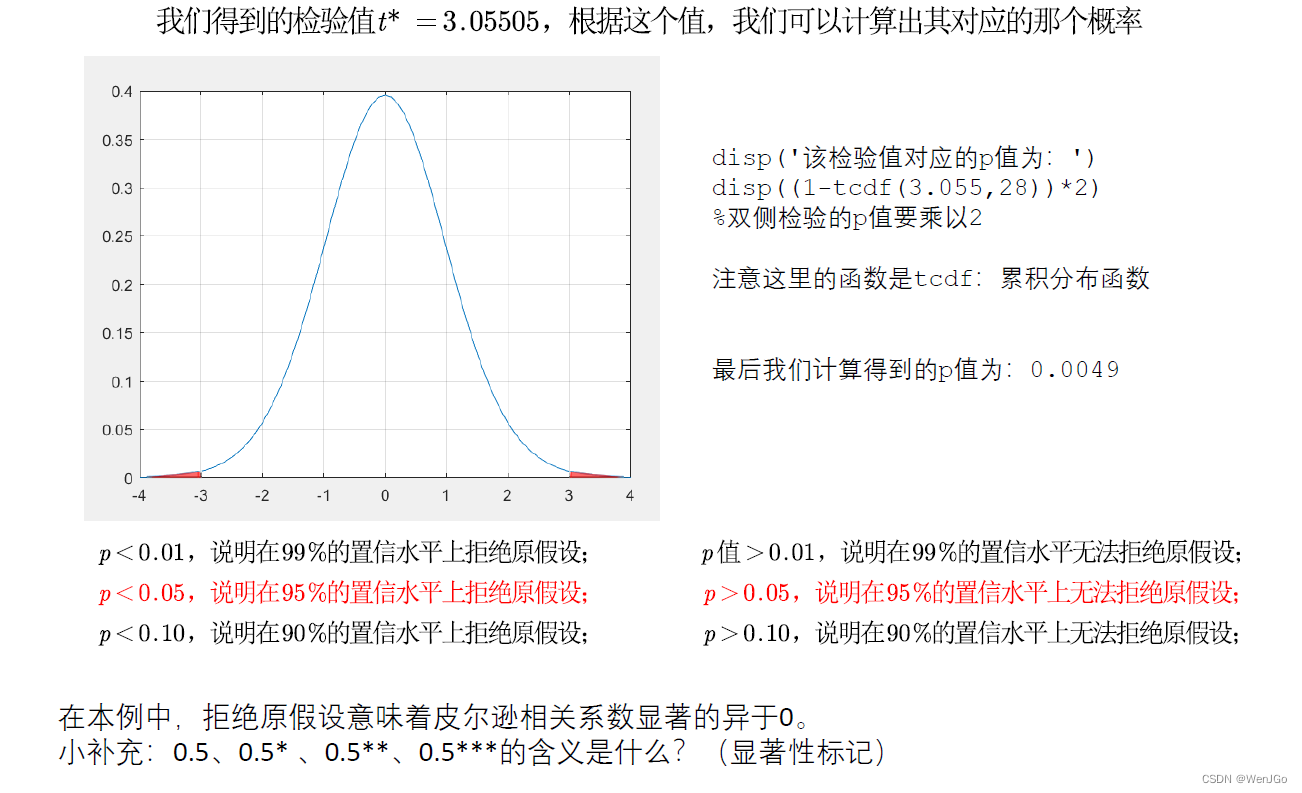
计算各列之间的相关系数以及p值
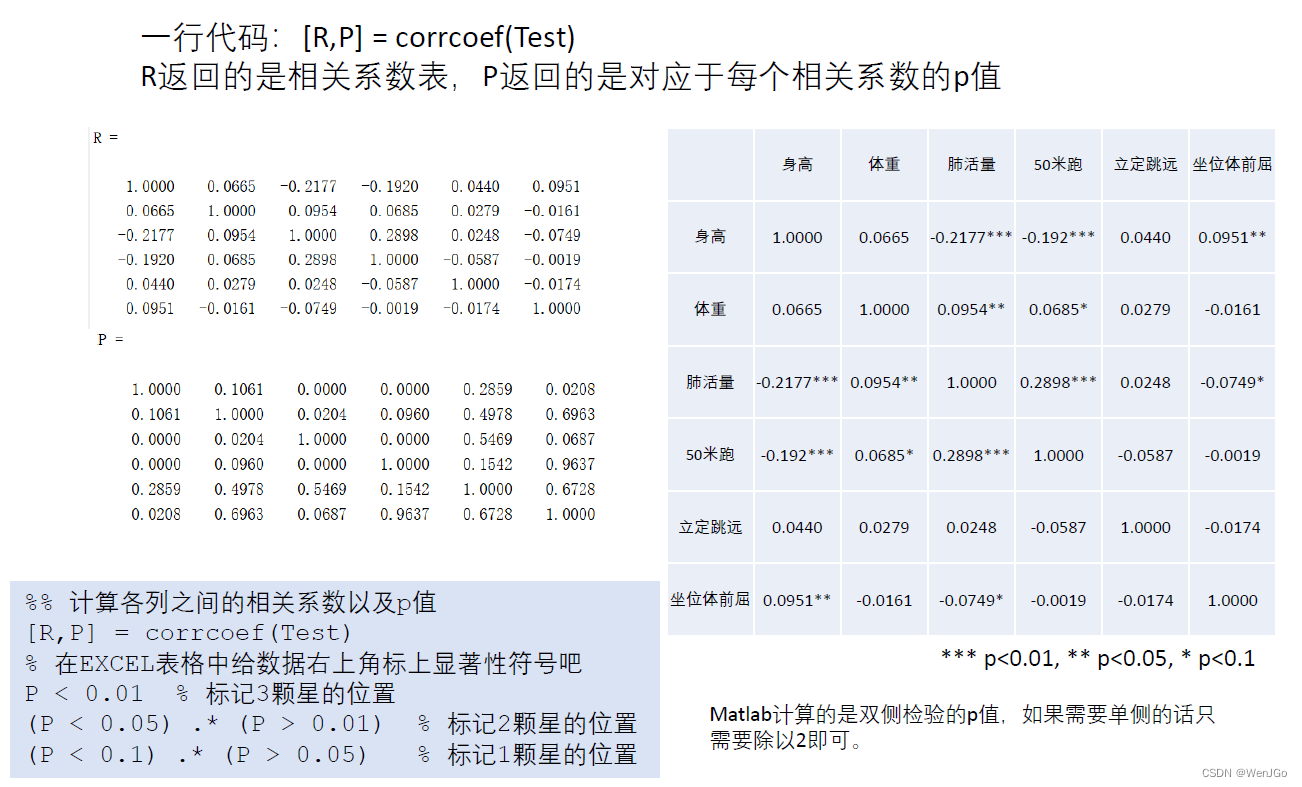
皮尔逊相关系数假设检验的条件
(1) 实验数据通常假设是成对的来自于正态分布的总体。因为我们在求皮尔逊相关性系数以后,通常还会用 t 检验之类的方法来进行皮尔逊相关性系数检验,而 t 检验是基于数据呈正态分布的假设的。
(2) 实验数据之间的差距不能太大,皮尔逊相关性系数受异常值的影响比较大。
(3)每组样本之间是独立抽样的,构造 t 统计量时需要用到。
那么问题就来了,如何检验数据是否是正态分布?
正态分布检验
雅克‐贝拉检验(Jarque‐Bera test):JB检验(大样本n>30)

偏度和峰度
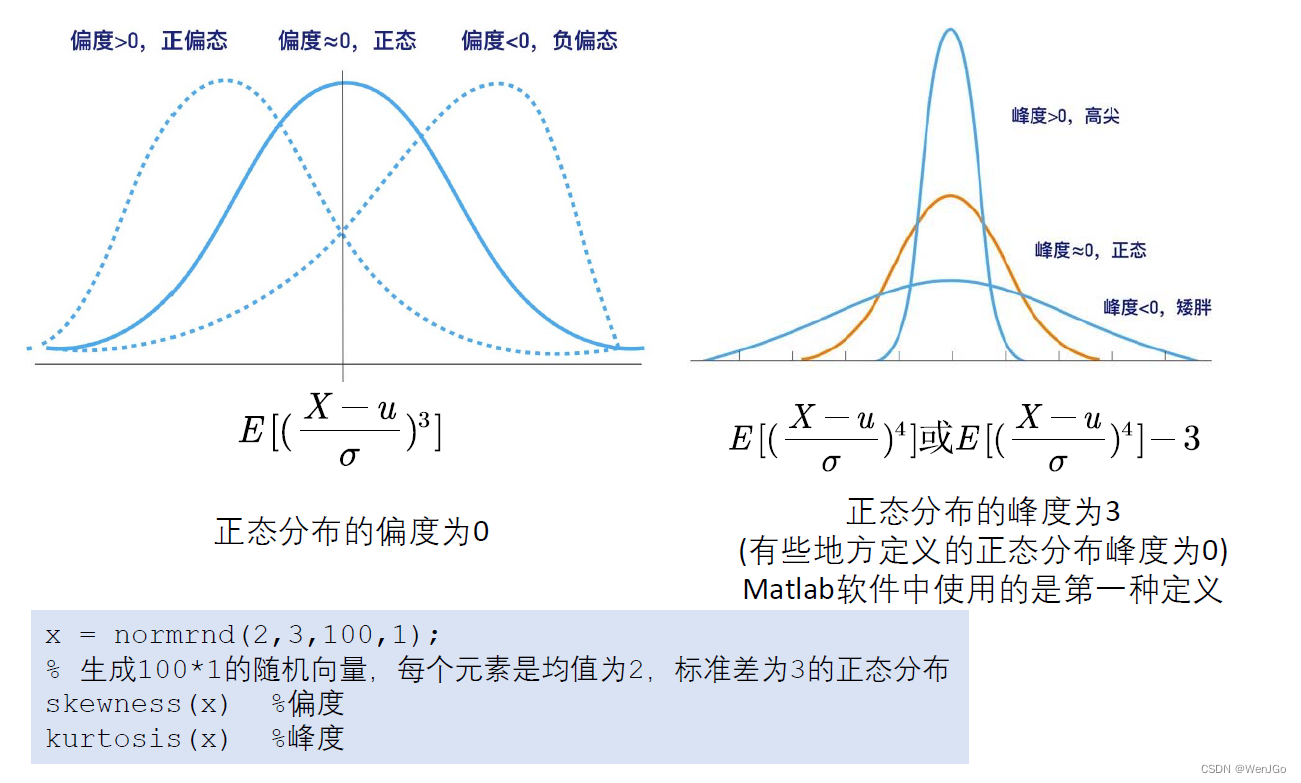
Matlab中JB检验结果
MATLAB中进行JB检验的语法:[h,p] = jbtest(x,alpha)
当输出 h = 1 时,表示拒绝原假设;h = 0 则代表将接受原假设。
alpha 就是显著性水平,一般取0.05,此时置信水平为1‐0.05=0.95
x 就是我们要检验的随机变量,注意这里的 x 只能是向量。
%% 正态分布检验
% 检验第一列数据是否为正态分布
[h,p] = jbtest(Test(:,1),0.05)
% 用循环检验所有列的数据
n_c = size(Test,2); % number of column 数据的列数
H = zeros(1,6);
P = zeros(1,6);
for i = 1:n_c
[h,p] = jbtest(Test(:,i),0.05);
H(i)=h;
P(i)=p;
end
disp(H)
disp(P)Shapiro-wilk检验:小样本(3≤n≤50)
Shapiro‐wilk夏皮洛‐威尔克检验
Q-Q图
????????在统计学中,Q‐Q图(Q代表分位数Quantile)是一种通过比较两个概率分布的分位数对这两个概率分布进行比较的概率图方法。
????????首先选定分位数的对应概率区间集合,在此概率区间上,点(x,y)对应于第一个分布的一个分位数x和第二个分布在和x相同概率区间上相同的分位数。
????????这里,我们选择正态分布和要检验的随机变量,并对其做出QQ图,可想而知,如果要检验的随机变量是正态分布,那么QQ图就是一条直线。
????????要利用Q‐Q图鉴别样本数据是否近似于正态分布,只需看Q‐Q图上的点是否近似地在一条直线附近。(要求数据量非常大)
斯皮尔曼spearman相关系数
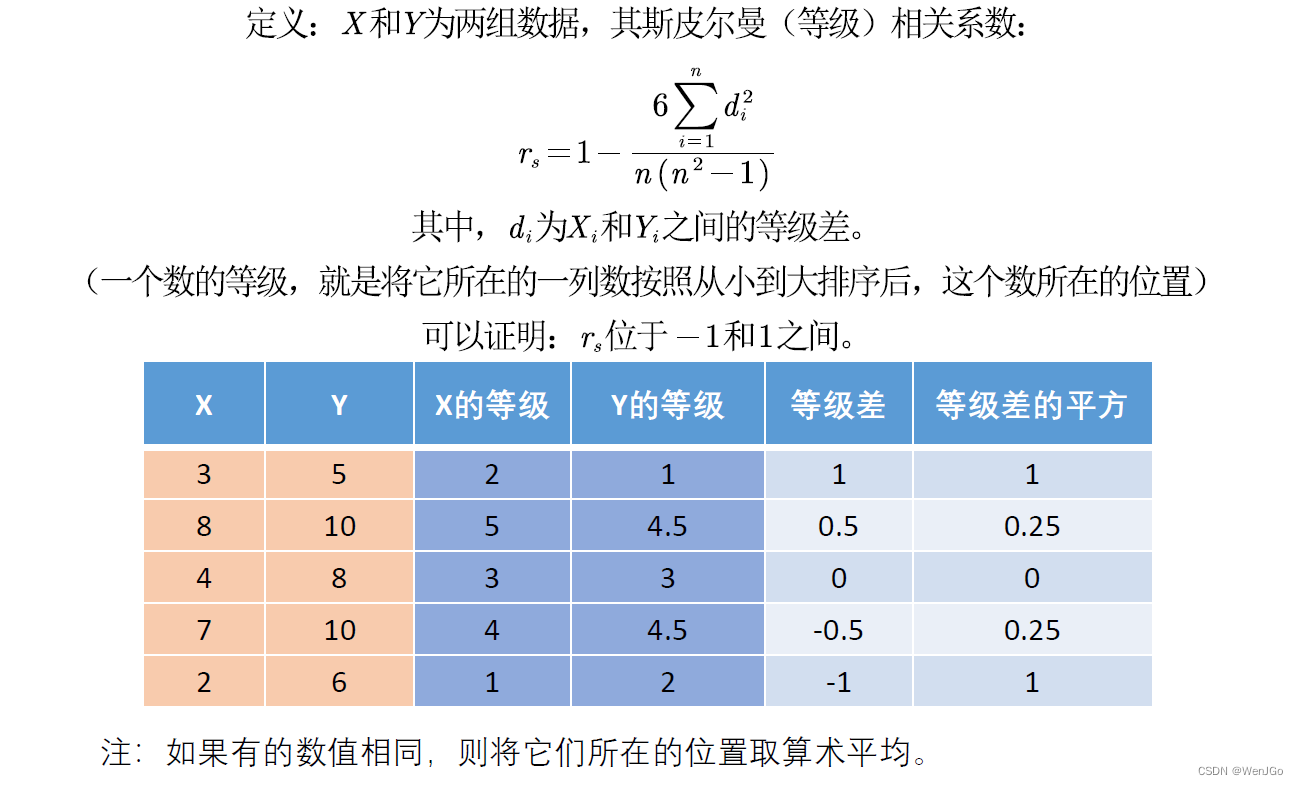
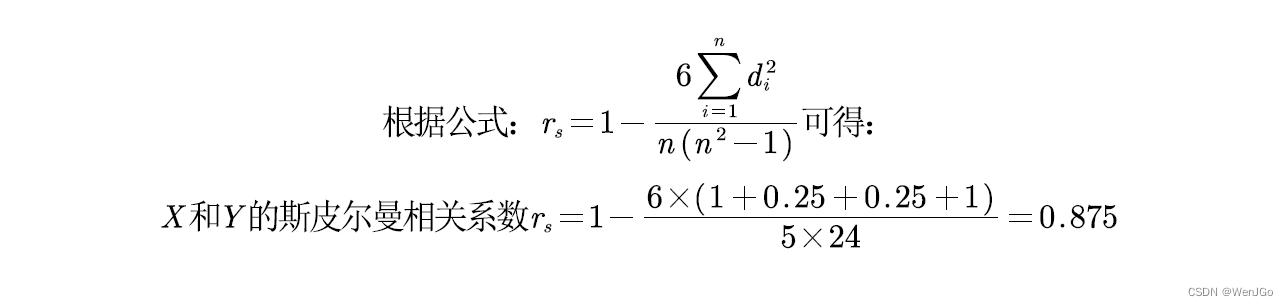
另一种斯皮尔曼spearman相关系数的定义
斯皮尔曼相关系数被定义成等级之间的皮尔逊相关系数。
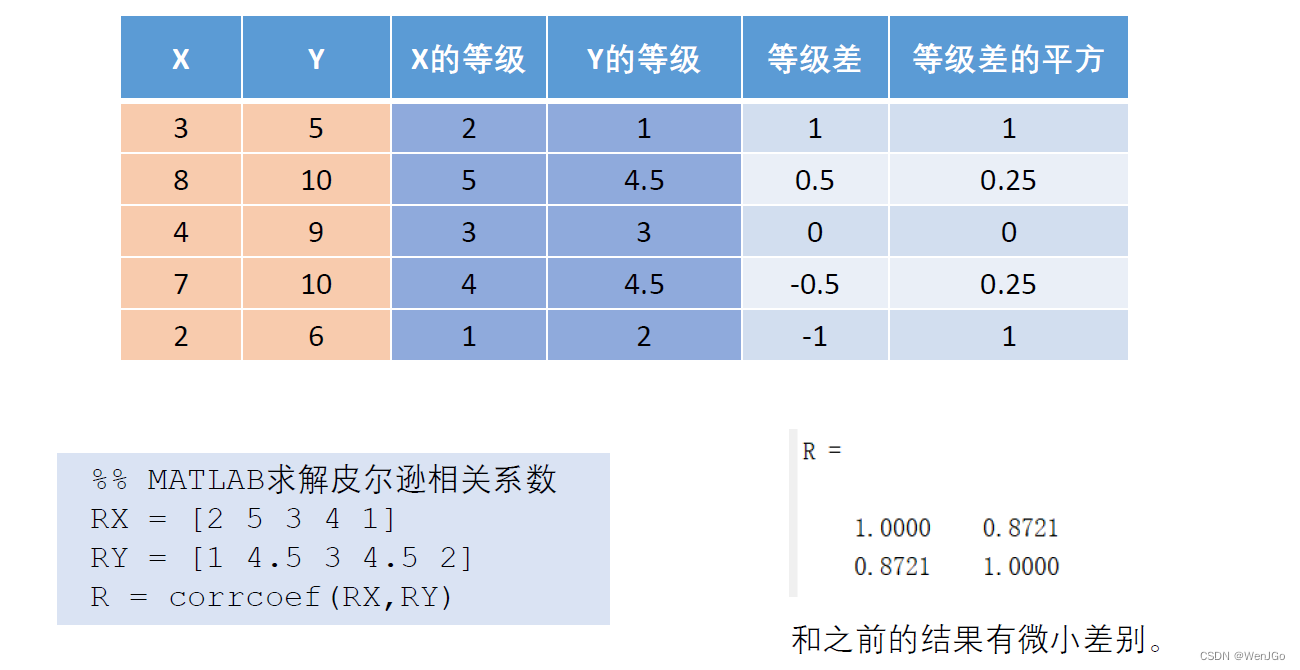
%% MATLAB求解皮尔逊相关系数
RX = [2 5 3 4 1]
RY = [1 4.5 3 4.5 2]
R = corrcoef(RX,RY)MATLAB中计算斯皮尔曼相关系数
两种用法
(1)corr(X , Y , 'type' , 'Spearman')
这里的X和Y必须是列向量
(2)corr(X , 'type' , 'Spearman')
这时计算X矩阵各列之间的斯皮尔曼相关系数
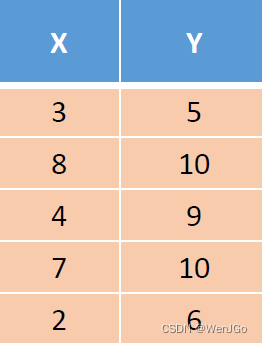
X = [3 8 4 7 2]' % 一定要是列向量,一撇'表示求转置
Y = [5 10 9 10 6]'
coeff = corr(X , Y , 'type' , 'Spearman')
?斯皮尔曼相关系数的假设检验
分为小样本和大样本两种情况:
小样本
小样本情况,即𝒏 <= 30时,直接查临界值表即可
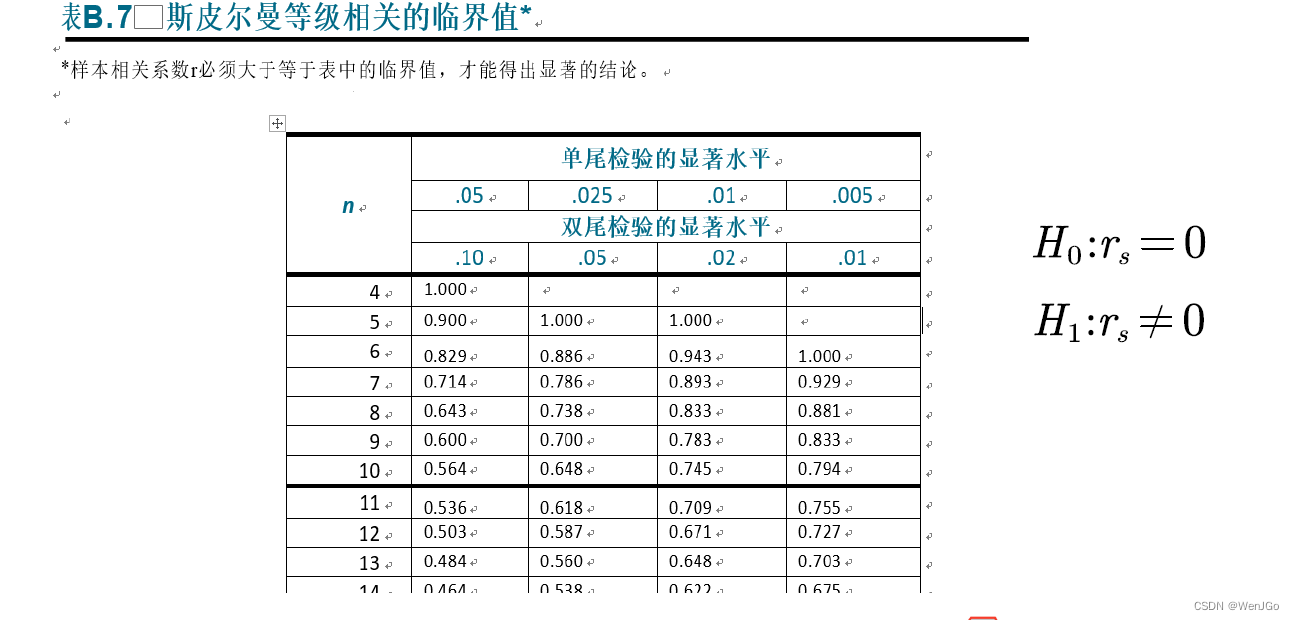
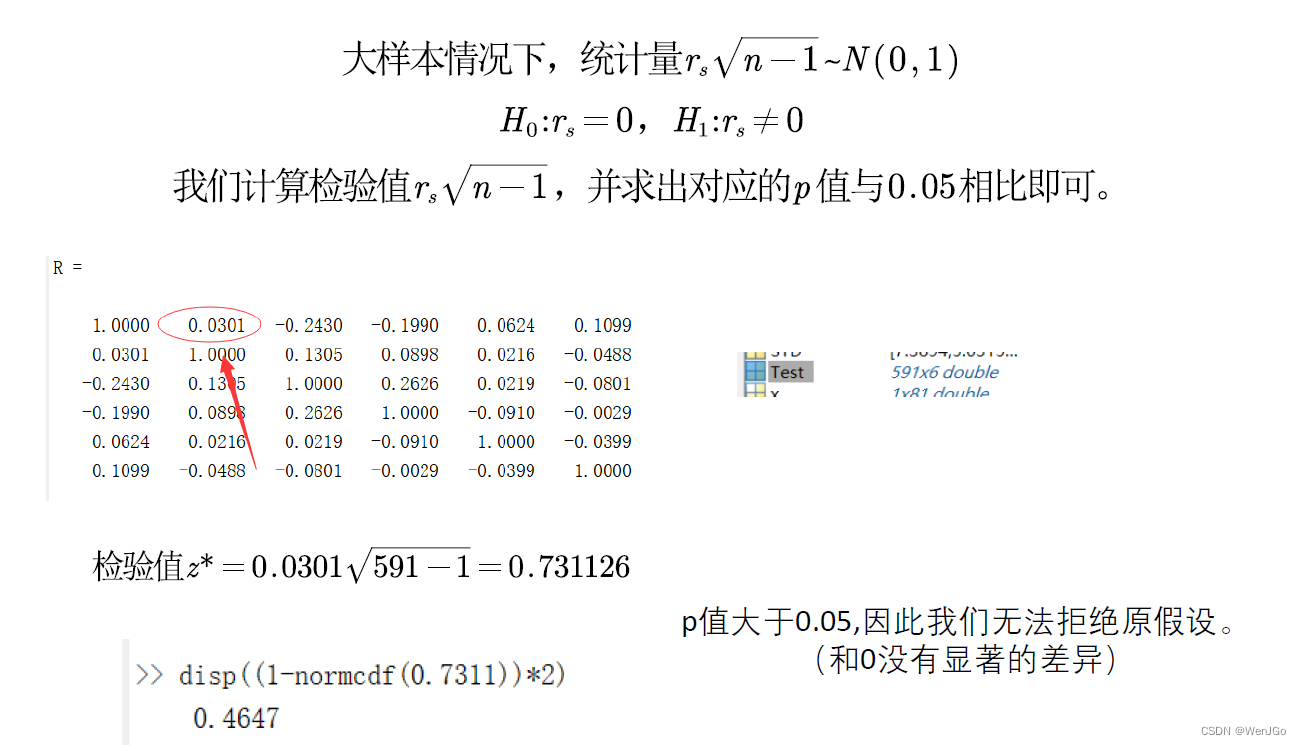
大样本
% 直接给出相关系数和p值
[R,P]=corr(Test, 'type' , 'Spearman')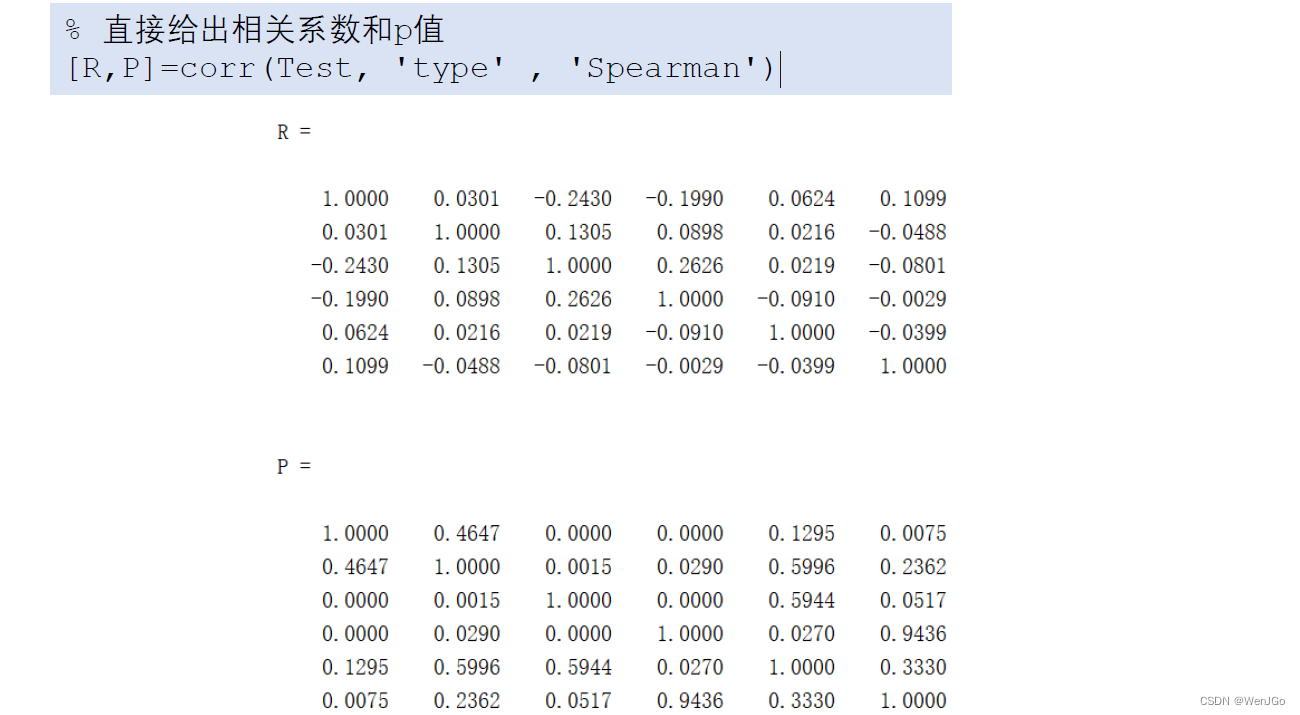
两种相关系数对比
计算结果对比
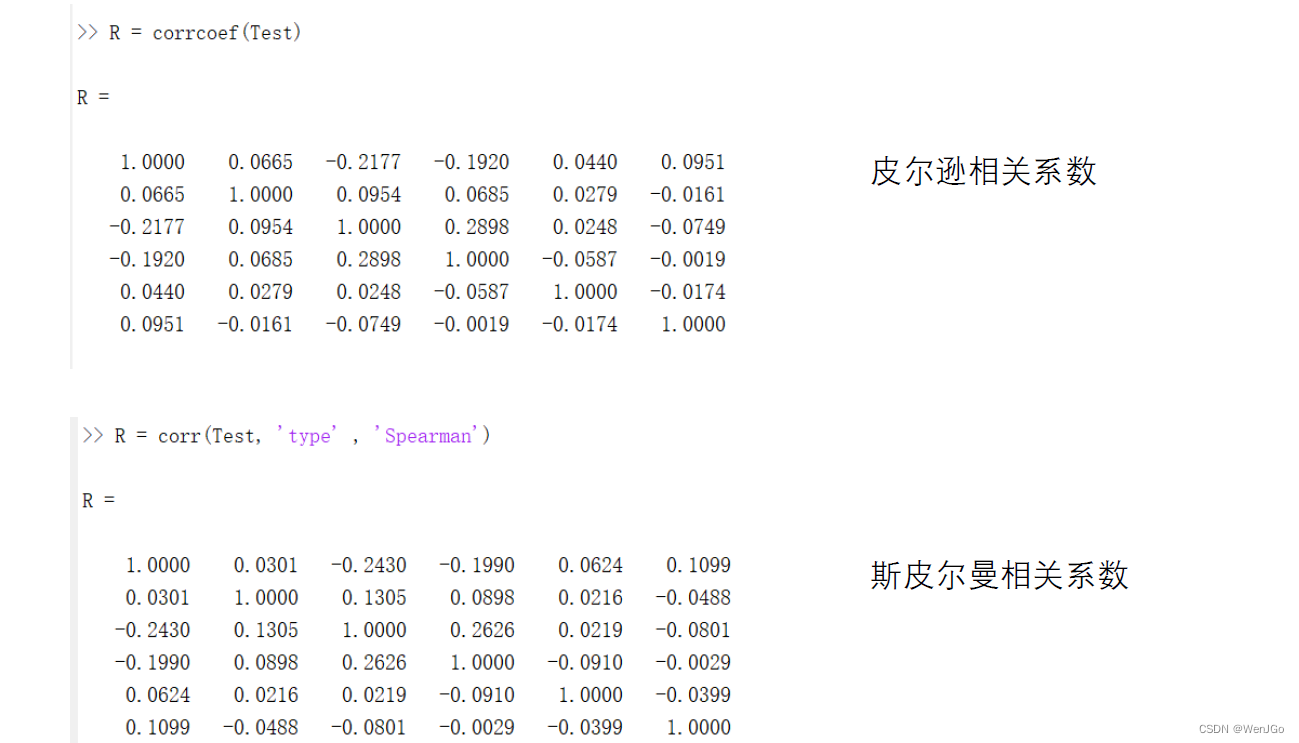
总体对比
斯皮尔曼相关系数和皮尔逊相关系数选择:
(1)连续数据,正态分布,线性关系,用 pearson 相关系数是最恰当,当然用spearman 相关系数也可以, 就是效率没有pearson相关系数高。
(2)上述任一条件不满足,就用 spearman 相关系数,不能用 pearson 相关系数。
(3)两个定序数据之间也用 spearman 相关系数,不能用pearson相关系数。
????????定序数据是指仅仅反映观测对象等级、顺序关系的数据,是由定序尺度计量形成的,表现为类别,可以进行排序,属于品质数据。
例如:优、良、差;
????????我们可以用1表示差、2表示良、3表示优,但请注意,用2除以1得出的2并不代表任何含义。定序数据最重要的意义代表了一组数据中的某种逻辑顺序。
????????注:斯皮尔曼相关系数的适用条件比皮尔逊相关系数要广,只要数据满足单调关系(例如线性函数、指数函数、对数函数等)就能够使用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 探索3D软件的奥秘:Maxon Cinema 4D与Autodesk Maya的比较
- CF888G Xor-MST DFS 生成树 Trie
- 数字化转型的核心路径是什么?
- ComfyUI报错AttributeError: module ‘cv2.gapi.wip.draw‘ has no attribute ‘Text‘
- MySql索引事务讲解和(经典面试题)
- 解决Docker报错问题:Docker Desktop – Unexpected WSL error
- 电商引流模式:广告电商
- 15:00面试,15:06就出来了,问的问题有点变态。。。
- 系列三十六、注解版Spring、SpringMVC配置文件
- 搜索引擎如何(以及为什么)呈现页面