目标检测-One Stage-YOLOv8
文章目录
前言
终于到了YOLO系列最新最火爆的网络–YOLOv8,前面YOLOv5中已经提到ultralytics团队集成了先进的YOLO系列目标检测最佳实践,YOLOv8则是他们的最新力作。
YOLOv8本身的创新点不多,偏向工程实践。
提示:以下是本篇文章正文内容,下面内容可供参考
一、YOLOv8的网络结构和流程
YOLOv8同样根据缩放给出了以下版本:YOLOv8n、YOLOv8s、YOLOv8m、YOLOv8l、YOLOv8x,同时包括两种输入尺度:P5 640 和 P6 1280
YOLOv8 P5的网络结构图如下,相比于YOLOv5,可以看出改进在于:
- Backbone+Neck:修改CSP结构为C2f
- Head:使用了Decouped Head,变为Anchor-Free
二、YOLOv8的创新点
- 骨干网络和 Neck 部分参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数,属于对模型结构精心微调
- 缩放的模型不再使用同一套参数
- Head部分采用先进Decouped Head,变为anchor-free
- Loss 计算方面采用了 TaskAlignedAssigner 正样本分配策略,并引入了 Distribution Focal Loss
- 训练的数据增强部分引入了 YOLOX 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度
三、创新点详解
CSP、C3和C2f
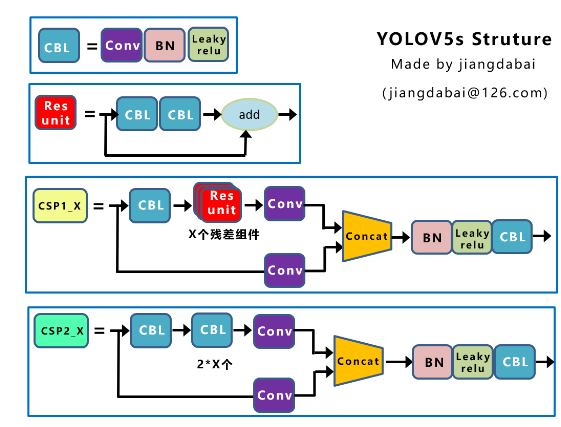
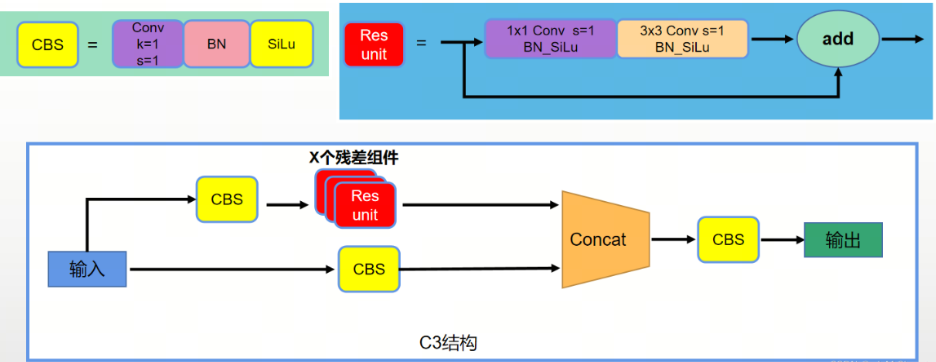
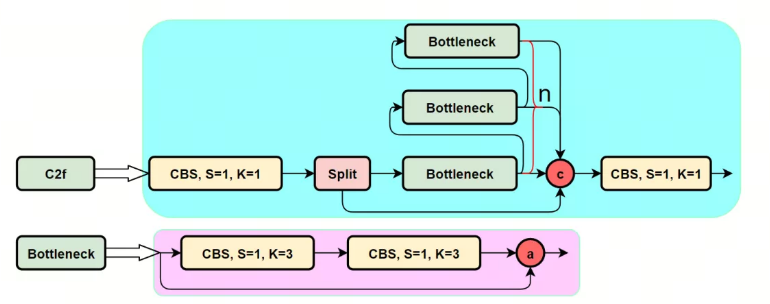
之前在目标检测-One Stage-YOLOv5的讲解中说到了YOLOv5(5.0) 中使用的残差块是CSP结构,在新版YOLOv5(6.0)中, 则将CSP结构改为C3结构。YOLOv8中又将C3结构改为C2f结构。
- CSPNet被提出的主要目的是为了保证在模型检测和识别精度没有下降的情况下,减少计算量,提高推理速度。它的主要思想是通过分割梯度流,使梯度流通过不同的网络路径传播。通过拼接和过渡等操作,从而实现更丰富的梯度组合信息。
- CSP和C3的结构和作用基本相同,区别在于C3去掉了残差单元(Res unit,也可叫Bottleneck)支路中后面的卷积层 以及 concat后的BN和Leaky relu层,并将激活函数改为SiLu。
- 通过C3替换CSP,可以起到精简网络结构,减少计算量,降低模型推理时间的作用。这样操作在YOLOV5X上模型参数量可以从89M下降到87.7M,推理时间从6.9ms下降到6.0ms,mAP从49.2提升到50.1。
- YOLOv8选用梯度流更丰富的C2f结构替换了YOLOv5中的C3结构,为了轻量化也缩减了骨干网络中最大stage的blocks数,同时不同缩放因子N/S/M/L/X的模型不再是共用一套模型参数,M/L/X大模型还缩减了最后一个stage的输出通道数,进一步减少参数量和计算量。
- C2f模块就是参考了C3模块以及ELAN的思想进行的设计,让YOLOv8可以在保证轻量化的同时获得更加丰富的梯度流信息
-
CSP(YOLOv5 -5.0)
-
C3(YOLOv5-6.0)
-
C2f(YOLOv8)
TaskAlignedAssigner 正样本分配策略
TaskAlignedAssigner是一种标签分配方法,其匹配策略简单总结为: 根据分类与回归的分数加权的分数选择正样本。
- 计算对齐程度分数矩阵
t = s α + u β t=s^\alpha+u^\beta t=sα+uβ
s 是标注类别对应的预测分值,u 是预测框和 gt 框的 iou,两者相乘就可以得到对齐程度分数 alignment_metrics。
- 基于 alignment_metrics 对齐分数选取 topK 的作为正样本
Distribution Focal Loss
和YOLOx不同的是,YOLOv8 loss 计算包括 2 个分支: 分类和回归分支,没有了之前的 objectness 分支。其中
- 分类分支依然采用 BCE Loss
- 回归分支采用的是 CIoU Loss 结合 DFL(Distribution Focal Loss)的方式,具体流程如下:
ps:
- 变为Anchor-Free后,由于其基于中心点的策略(Center-based methods)后,模型从输出“锚框大小偏移量(offest)”变为"预测目标框左、上、右、下边框距目标中心点的距离(ltrb = left, top, right, bottom)",如果距离中心点过远,则收敛较慢,且容易陷入局部最优。
- 因此YOLOv8采用了如下方法:
- 先利用softmax处理后得到预测框位置的离散分布值(shape为4K x reg_max,K为预测框数量,reg_max为预设值)
- 然后使用DFL,通过巧妙利用交叉熵损失将预测位置迅速聚焦到目标位置附近,经过加权求和得到四个预测坐标值
- 最后使用CIoU Loss进一步精确坐标位置。
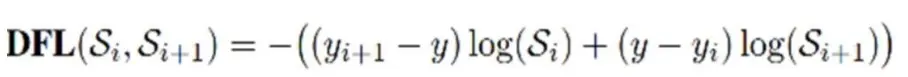
关闭 Mosiac
YOLOv8实验表明,Mosiac数据增强可以迫使模型学习新位置、部分遮挡以及针对不同周围像素的对象,增强模型鲁棒性。但如果在整个训练过程中都进行Mosiac数据增强,则会降低模型性能,在最后十个训练周期中关闭Mosiac是有利的。
总结
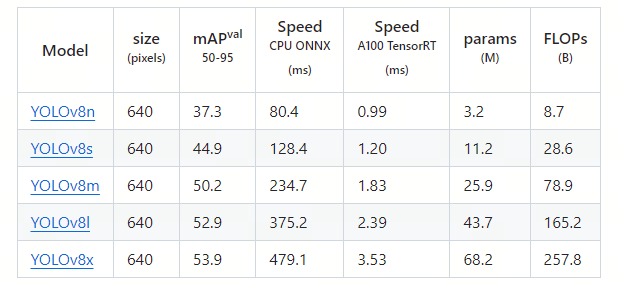
YOLOv8的出现进一步促进了实时目标检测的发展。其在COCO数据的精度和速度如下:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Windows主机Navicat远程连接到Ubuntu18.04虚拟机MySQL
- 数字化技术助力英语习得 iEnglish成智慧化学习新选择
- Pytorch的默认初始化分布 nn.Embedding.weight初始化分布
- [AIGC] 计算机视觉(CV)技术的优势和挑战
- arcgis更改服务注册数据库账号及密码
- 【动态管理日志】Spring Boot 实现 热插拔 AOP,非常实用!
- What is `WebMvcConfigurer` does?
- vivado 添加现有IP文件、生成IP
- 【neo4j】python使用neo4j
- 【BI&AI】Lecture 5 - Auditory system