哈希——位图以及布隆过滤器
在此之前,我的博客中已经介绍了哈希的思想,以及什么是哈希表和哈希桶,但是在实际场景中
有这么一种情景。那就是我们使用哈希的思想的时候有时候只需要获取一种状态量(在或是不在)
0或1、非此即彼的两种状态,这个时候我们再使用哈希表数组的时候就有点浪费,因为我们表示
这种状态只需要一个比特位就可以实现,而关于比特位的管理我们只需要使用简单的位操作就可
以实现。这就是我今天要介绍的基于哈希思想的数据结构——位图
1.位图
a. 位图的简单认识
我上面说到:有时候我们在场景中会有非此即彼的状态量,这个时候就可以使用我们的位图,比如记录某个值是否只出现过一次,或者是记录某些值是否存在,这个时候我们就可以使用位图:例如Linux中关于进程调度的情况中有两个调度队列,每个调度队列中是否有待调度的进程就是用位图来记录的,这样可以极大节省空间:我的关于进程调度的博客。
b. 位图的实现
现在我们知道了位图的一个单位大小就是一个bit,那我们怎么开辟任意大(不超过内存)的比特位供我们使用呢?其实我们可以申请一片连续的空间,将每个字节看成八个比特位即可,在这里我选择使用int来开辟,就算申请的多了也只是多了一个整形大小而已:
template<size_t N>
class bitset
{
public:
bitset()
{
_map.resize(N / 32 + 1, 0);
}
private:
vector<int> _map;
};
这上面使用到了非类型模板参数不知道的可以看这篇博客:模板再认识。
这里由于整形有32个比特位,所以我们如果需要N个空间的话就需要除以32。
接下来就是方法的实现:
template<size_t N>
class bitset
{
public:
bitset()
{
_map.resize(N / 32 + 1, 0);
}
void set(const int& x)
{
int i = x / 32;
int j = x % 32;
_map[i] |= (1 << j);
}
void reset(const int& x)
{
int i = x / 32;
int j = x % 32;
_map[i] &= ~(1 << j);
}
bool test(const int& x)
{
int i = x / 32;
int j = x % 32;
if ((_map[i] & (1 << j)) != 0)
{
return true;
}
else
{
return false;
}
}
private:
vector<int> _map;
};
这其中需要掌握一些位操作运算符的知识:
1. 只将某一位变成1其他位不变
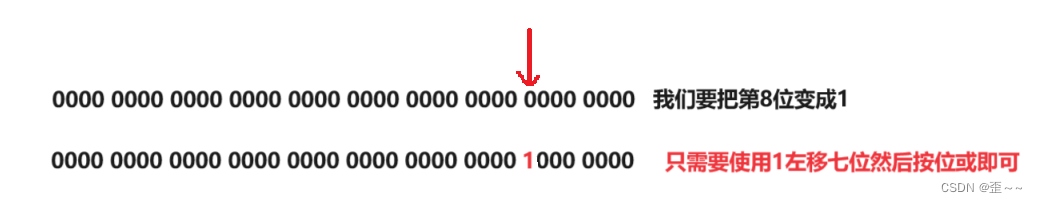
2. 将某一位置为零,其他位不变

这里需要注意一个小技巧:
当我们要操作第n位的时候一般是左移n-1位
当我们写好位图之后,又遇到了问题,它怎么记录字符串呢?有人说可以使用字符串的哈希函数啊,但是你要知道的是,这里本质的问题是就无法存储字符串。会遇到这样一种情况:
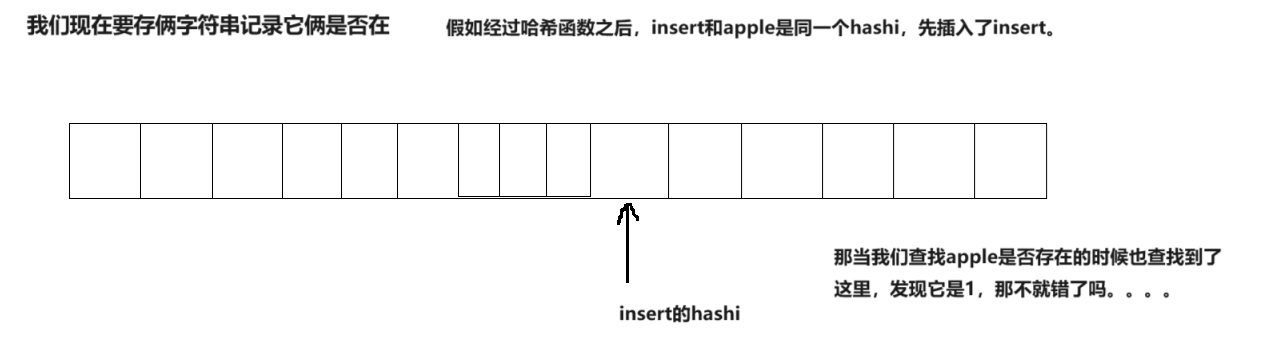
我们无法判断这里存储的到底是哪个字符串。所以这时候就有有人提出了新的概念,在位图的基础上,创造了布隆过滤器。
2.布隆过滤器
a. 布隆过滤器的认识和实现
在介绍布隆过滤器之前,我们先要明确一件事情:在位图中,判断某个元素是否存在,判断他在是不准确的,而判断它不在是准确的
我们还是使用上面的例子:
当我们记录insert之后,我们再查找apple,发现它那位是1,但是apple实际并没有被我们记录,所以判断在这件事是不准确的。
反之我们没有记录insert,而直接判断apple是否被记录,我们发现它那位是0,则就可以明确apple并没有被我们记录,所以判断不存在是准确的。
基于这一特点,布隆过滤器就出现了,当我们要记录一个字符串的时候,它会使用若干个字符串哈希函数处理要被记录的值,然后将这些hashi都置为1。当我们判断这个字符串是否被记录的时候,需要查看若干个相关的hashi是否全为1,如果不是,那么这个字符串是不被记录的,如果全为1,那说明这个字符串是可能被记录的,要注意这里是使用了可能二字,所以它叫做过滤器。
这里有一篇不错的博客:link
而当我们要删除的时候,要注意:当删除某一个位置的1的时候我们不知道这个1是否是多个字符串的hashi所以,我们需要记录位图上每个位的引用,使用引用计数,具体方法可以是再多添一张位图或者是,将位图的单个元素的大小调整为两字节(具体自己可以定义),但是布隆过滤器是一般不提供删除的,那我们就来实现一下这个布隆过滤器:
struct BKDRHash
{
size_t operator()(const string& key)
{
size_t hashi = 0;
for (auto c : key)
{
hashi += c;
hashi *= 31;
}
return hashi;
}
};
struct SDBMHash
{
size_t operator()(const string& key)
{
size_t hashi = 0;
for (auto c : key)
{
hashi = 65599 * hashi + c;
//hash = (size_t)ch + (hash << 6) + (hash << 16) - hash;
}
return hashi;
}
};
struct RSHash
{
size_t operator()(const string& key)
{
size_t hashi = 0;
size_t magic = 63689;
for(auto c : key)
{
hashi = hashi * magic + c;
magic *= 378551;
}
return hashi;
}
};
template<size_t N, class K = string, class HashFunc1 = BKDRHash,
class HashFunc2 = SDBMHash, class HashFunc3 = RSHash>
class bloomfilter
{
public:
void set(const K& key)
{
size_t hash1 = HashFunc1()(key) % N;
size_t hash2 = HashFunc2()(key) % N;
size_t hash3 = HashFunc3()(key) % N;
_bs.set(hash1);
_bs.set(hash2);
_bs.set(hash3);
}
bool test(const K& key)
{
size_t hash1 = HashFunc1()(key) % N;
if (_bs.test(hash1) == false)
return false;
size_t hash2 = HashFunc2()(key) % N;
if (_bs.test(hash2) == false)
return false;
size_t hash3 = HashFunc3()(key) % N;
if (_bs.test(hash3) == false)
return false;
return true;
}
private:
bitset<N> _bs;
};
b. 应用场景
布隆过滤器它只是一个大致用来过滤的容器,它用来判断在是不准确的,而判断一个元素不在是准确的,基于这一特性,我们可以使用它来规范软件中用户的昵称。防止用户的昵称重复。
如果不使用布隆过滤器的话,用户在输入一个自己心仪的昵称的时候,服务器需要判断数据库中是否已经有了这一个昵称,需要在网络上传输,效率不高,而在网页上或者客户端中提前准备好布隆过滤器,那用户的体验就会好很多。假如用户的id没有被记录那么昵称合法的情况下就注册成功了,如果判定昵称已经被记录,这个时候我们不确定服务器端中是否真的记录了这个昵称,那么这个时候我们就可以向服务器发起请求进行进一步的判断了。这种情况下我们的昵称注册的效率会大幅提升,大大提升了用户体验。
3. 利用哈希思想处理海量数据
给过一个超过100G的log file,其中存放着IP地址,设计算法找到出现最多的IP地址
我们知道100G内存的文件是不能存放到内存中的(除非内存足够大),所以我们使用哈希思想例如hashi = ip % 500 将100G的文件分成五百份小文件,这样就可以将文件加载到内存中然后我们使用map记录每个文件中ip出现的次数,需要注意的是相同的ip地址一定会被归到同一个小文件中(由于ip % 500)的原因,所以我们只需要记录每个小文件中的最大值以及ip地址,然后重复直到找到目标即可。在其中我们使用哈希之后分割出的小文件有可能仍然有大于内存的情况,这个时候会有两种情况:
- 该文件中存储的ip地址重复度很高
- 该文件中重复度不高。
基于这两种情况我们可以依旧将它存入map中,如果在存放过程中内存没超则正常继续,如果map内存超了说明该文件中ip地址重复度不高,这个时候会抛异常,这个时候我们就继续使用哈希将这个文件继续切割,然后重复存入map中。如此往复。
这种处理方式也叫做哈希切割
基于此衍生的TopK的ip地址出现次数,也可以使用堆来处理。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 少走弯路,ESP32 下别混用wifi和蓝牙
- 聚观早报 | 华为P70 Art细节曝光;红魔9 Pro龙年限定版官宣
- React.Children.map 和 js 的 map 有什么区别?
- Android 13 自动旋转屏幕 重启后关闭的问题
- 完美解决idea一直indexing,无法操作的问题
- 算法训练day11Leetcode20有效的括号1047删除字符串中所有相邻重复项150逆波兰表达式求值
- 【Linux】cp问题,生产者消费者问题代码实现
- 作为铭文跨链赛道龙头,SoBit 有何突出之处?
- 获取两个数组中相同的对象
- [一文详解]Base64编码,Url Base64编码,UrlEncode编码,你还傻傻分不清吗?