(2024,分数蒸馏抽样,Delta 降噪分数,LoRA)PALP:文本到图像模型的提示对齐个性化
PALP: Prompt Aligned Personalization of Text-to-Image Models
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
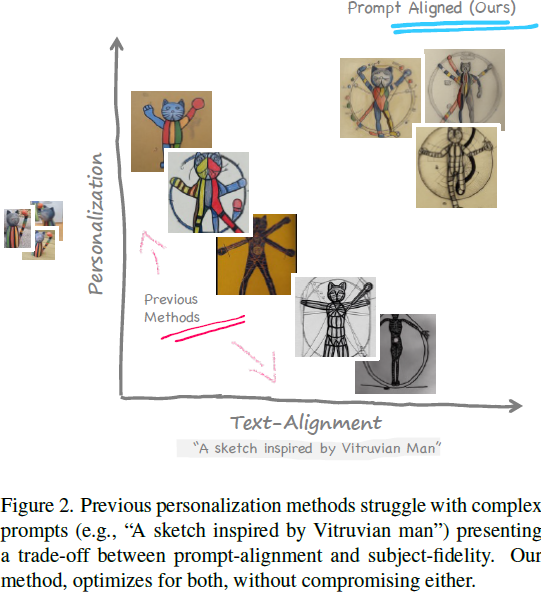
内容创作者通常致力于使用个人主题创建个性化图像,超越传统的文本到图像模型的能力。此外,他们可能希望生成的图像涵盖特定的地点、风格、氛围等。现有的个性化方法可能会影响个性化能力或与复杂文本提示的对齐。这种权衡可能妨碍用户提示的实现和主题的忠实性。我们提出了一种新方法,专注于解决这个问题的单一提示的个性化方法。我们将我们的方法称为提示对齐个性化(prompt-aligned personalization)。尽管这可能看起来有限制,但我们的方法在改善文本对齐方面表现出色,能够创建具有复杂提示的图像,这可能对当前技术构成挑战。特别是,我们的方法使用额外的分数蒸馏抽样(score distillation sampling)项,保持个性化模型与目标提示对齐。我们展示了我们的方法在多样本和单样本环境中的多功能性,并进一步展示它可以组合多个主题或从参考图像(如艺术作品)中汲取灵感。我们定量和定性地与现有基准和最先进的技术进行了比较。
项目页面位于 https://prompt-aligned.github.io/

4. 提示对齐方法
4.1 概述
我们的主要目标是教导 G 生成与新主题 S 相关的图像。然而,与先前的方法不同,我们强调为单一文本提示(用 y 表示)实现最佳结果。例如,考虑这样一种情景,感兴趣的主题是自己的猫,提示是 y = "A sketch of [my cat] in Paris"。在这种情况下,我们的目标是生成一个忠实地代表猫的图像,同时包括所有提示元素,包括素描风格和巴黎的背景。
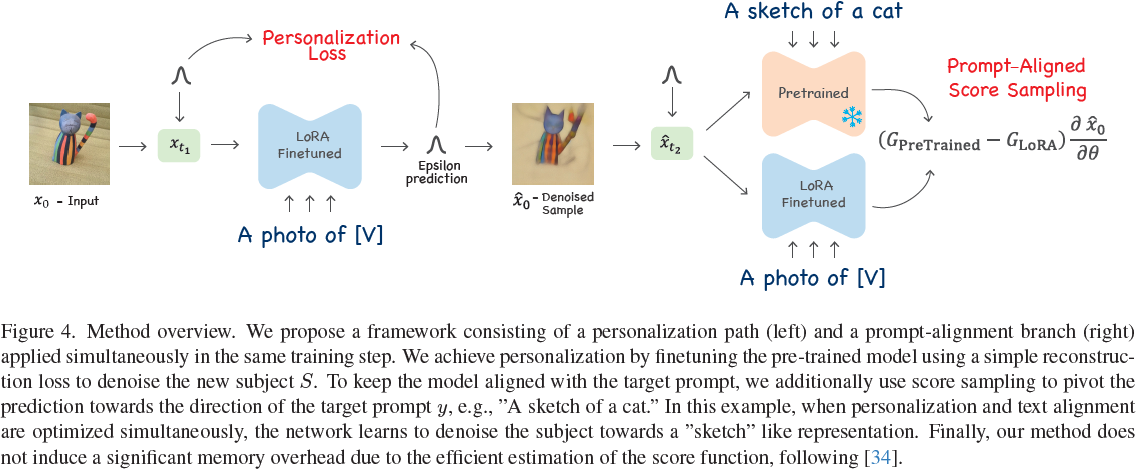
关键思想是优化两个目标:个性化和提示对齐。对于第一部分,即个性化,我们微调 G 以从噪声样本中重建 S。提高提示对齐的一种选择是在调整 G 对 S 进行微调时将目标提示 y 作为条件。然而,这会导致次优结果,因为我们没有描绘 y 的图像(例如,我们既没有猫的素描图像,也没有它在巴黎的照片)。相反,我们将 G 的噪声预测朝向目标提示 y 进行推动。具体而言,我们使用分数抽样方法将 G 对 S 的估计引导到分布密度 p(x|y)(见图4)。通过同时使用这两个目标,我们实现了两件事情:(1)通过反向扩散过程生成目标主题 S(个性化),同时(2)确保噪声预测与文本 y 对齐。接下来详细解释我们的方法。
4.2 个性化
我们遵循先前的方法 [15, 28, 39, 46],在代表 S 的一小组图像上对 G 进行微调,这组图像可以只有一张照片。我们使用 LoRA 方法 [22] 更新 G 的权重,其中我们仅更新网络权重的子集 θ_LoRA ? θ,即自注意力和交叉注意力层。此外,我们优化一个新的词嵌入 [V] 来表示 S。
4.3 提示对齐分数抽样
在小图像集上进行长时间的微调可能导致模型过拟合。在这种情况下,扩散模型的预测总是将反向去噪过程引导到训练图像中的一个,而不考虑任何条件提示。确实,我们观察到过拟合的模型甚至在单个去噪步骤中都能从噪声样本中估计输入。

在图 5 中,我们通过分析模型对 x_0(真实样本图像)的估计来可视化模型的预测。真实样本的估计 ?x_0 是通过模型的噪声预测导出的,公式如下:

从图 5 中可以看出,预训练模型(在个性化之前)将图像引导到类似素描的图像,其中估计值? ?x_0 具有白色背景,但缺少主题细节。在没有 PALP 的情况下应用个性化,会导致过拟合,训练图像的元素(如背景)更为显著,而素描感逐渐消失,表明与提示 “A sketch” 不对齐,并过度拟合输入图像。使用 PALP 时,模型预测将反向去噪过程引导到类似素描的图像,同时保持个性化,还原了猫的形状。
我们的关键思想是鼓励模型的去噪预测朝向目标提示。或者,我们推动模型对真实样本的估计(用 ?x_0 表示)与提示 y 对齐。
在我们的示例中,目标提示是 “A sketch of [V]”,我们将模型的预测推向素描,并防止过拟合特定图像背景。与个性化损失一起,这将鼓励模型专注于捕捉 [V] 的识别特征,而不是重建背景和其他干扰特征。
为了实现后者,我们使用分数蒸馏抽样(SDS)技术[34]。具体而言,给定一个不包含占位符 "[V]" 的干净目标提示 y^c。然后,我们使用分数抽样来优化损失:
![]()
![]()
请注意,我们使用预训练的网络权重来评估公式(3),并省略所有已学习的占位符(例如 [V])。因此,通过最小化该损失,我们将保持与文本提示 y 对齐,因为预训练模型具有有关提示元素的所有知识。
Poole等人 [34] 找到了一种优雅而高效的分数函数近似,使用以下方法:?
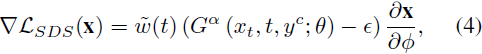
其中 ? 是控制 x 外观的权重,?w(t) 是加权函数。这里的 G^α 表示无分类器引导预测,它是条件和无条件(y = ?)噪声预测的外推(extrapolation)。标量 α ∈ R+ 通过以下方式控制外推:?
![]()
在我们的情况下,x = ?x0,并且根据公式(2)从 G 的噪声预测中导出。因此,?x0 的外观直接由 LoRA 权重和 [V] 控制。
4.4 避免过饱和和模式崩溃
通过 SDS 进行引导会产生较少多样性和过饱和的结果。类似 [26, 52] 的替代实现改善了多样性,但整体上个性化仍受到影响(请参见附录 A)。我们认为这背后的原因是公式(4)中的损失将预测 ?x_0 推向 p(x|y_c) 的分布中心,而干净的目标提示 y^c 只包含主题类别,即 “一只猫的素描”,因此损失将鼓励 ?x_0 走向一般猫的分布中心,而不是我们的猫的分布中心。
相反,我们发现 Delta Denoising Score (DDS) [18] 变体效果更好。具体而言,我们使用个性化模型预测与预训练模型预测
![]()
![]()
之间的残差方向,其中 α 和 β 分别是它们的引导尺度。这里 y_P 是个性化提示,即 “A photo of [V]”,y^c 是一个干净的提示,例如 “A sketch of a cat.””。然后,分数可以通过以下方式估计:

这会扰动去噪预测到目标提示的方向(见图 4 的右侧)。我们的实验证明,不平衡的引导尺度,即 α > β,效果更好。我们还考虑了两个变体实现:(1)在第一种实现中,我们对两个分支(文本对齐和个性化分支)使用相同的噪声,以及(2)我们对分支使用两个独立同分布的噪声样本。使用相同的噪声比后者实现更好的文本对齐。
关于 PALP 的计算复杂性:公式(6)中的梯度与个性化梯度成比例,具有缩放:
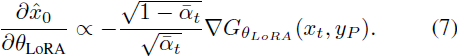
由于右侧的梯度也是公式(1)的导数的一部分,因此我们不需要通过对齐分支对文本到图像模型进行反向传播。这可能对使用更大模型的引导来提升较小模型的个性化性能很有用。最后,我们还注意到对于较大的 t 值,缩放项非常大。通过
![]()
重新缩放梯度确保了所有时间步的均匀梯度更新,并提高了数值稳定性。
5. 结果
我们将我们的方法与多样本方法进行比较,包括 CustomDiffusion [28]、P+ [51] 和 NeTI [1]。我们还使用我们的实现对 TI [15] 和 DB [39] 进行比较,这也应该突显出通过将我们的框架与现有的个性化方法结合使用所取得的收益。?


 ?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ES-搜索
- Activiti7官方在线流程设计器下载和部署
- PathWave Device Modeling (IC-CAP) 建模系统——IC-CAP概述
- 蝉妈妈简单使用
- 多重断言插件
- linux系统官方yum源安装nginx和源码编译安装nginx
- docker 安装可视化工具 Protainer 以及 汉化
- 毕业设计选题:信息安全专业毕业设计(论文)选题推荐 2024
- Centos7笔记09之nginx反向代理grafana
- 【2024最新-python3小白零基础入门】No1.python简介以及环境搭建