【Java】JUC并发编程(重量锁、轻量锁、偏向锁)
JUC并发编程
预备:
创建一个maven工程,导入lombok和logback的依赖。
1、基础概念
1、进程与线程
**进程:**程序由指令和数据组成,但这些指令要运行,数据要读写,就必须将指令加载至 CPU ,数据加载至内存。在指令运行过程中还需要用到磁盘、网络等设备。进程就是用来加载指令、管理内存、管理IO的。当一个程序被运行,从磁盘加载这个程序的代码至内存,这时就开启了一个进程。进程就可以视为程序的一个实例。大部分程序可以同时运行多个实例进程(例如记事本、画图、浏览器等),也有的程序只能启动一个实例进程(例如网易云音乐、 360 安全卫士等)。
**线程:**一个进程之内可以分为一到多个线程。一个线程就是一个指令流,将指令流中的一条条指令以一定的顺序交给CPU执行。Java 中,线程作为最小调度单位,进程作为资源分配的最小单位。在 windows 中进程是不活动的,只是作为线程的容器。
进程只是用来管理内存、加载指令,线程才将指令交给CPU执行。
对比
进程相互之间是独立的,而线程存在于进程之中。
进程之间通信较为复杂,同一台计算机中的进程通信称为IPC,不同计算机之间的进程通信需要通过网络并遵守共同的协议,例如HTTP。
线程通信较为简单,因为同一进程中的线程共享这个进程的内存区域。
2、并发与并行
并发: 单核 cpu 下,线程实际还是串行执行的。操作系统中有一个组件叫做任务调度器,将 cpu 的时间片(windows 下时间片最小约为15毫秒)分给不同的线程使用,只是由于 cpu 在线程间(时间片很短)的切换非常快,人类感觉是同时运行的。一般会将这种线程轮流使用 cpu 的做法称为并发(concurrent)。
并行: 多核cpu下,不同的cpu执行不同的线程,就叫做并行。这是真正的同时进行(parallel)。
更多的时候,是并发和并行同时存在。
Golang之父Rob对并行与并发有一段很形象的描述:并发是同一时间应对多件事情的能力,并行是同一时间做多件事情的能力。
一个例子:
- 家庭主妇做饭、打扫卫生、给孩子喂奶,她一个人轮流交替做这多件事,这时就是并发
- 家庭主妇雇了个保姆她们一起这些事,这时既有并发,也有并行(这时会产生竞争,例如锅只有一口,一个人用锅时,另一个人就得等待)
- 雇了 3 个保姆,一个专做饭、一个专打扫卫生、一个专喂奶,互不干扰,这时是并行
3、同步与异步
从调用方的角度来讲:
- 需要等待方法调用的结果返回才能继续执行接下来的代码,称为同步
- 不需要等待方法调用的结果返回就能继续执行接下来的代码,称为异步
main线程如果等待t1线程执行完毕后才能继续执行,就称为:main线程在同步等待t1线程。
单线程中,指令执行是同步的。
多线程可以实现异步操作。比如ui程序,调用算法进行计算,此时如果算法计算在ui线程中执行,线程会卡死。如果多开一条线程用来处理算法,就可以在算法计算的时候同时操作ui界面了。
4、应用
多核cpu,如果开启多线程,可以显著提高程序运行效率。

虽然单核cpu开启多线程不能提高程序运行的效率,但这并不意味着单核下的多线程没有意义。cpu轮流处理多个线程,可以避免一个线程总占用cpu,让其他线程没法干活。
2、线程
2.1、创建和运行线程
创建线程第一种方法:
//Thread继承了Runnable接口,使用Thead的匿名内部类重写run方法
Thread t = new Thread() {
@Override
public void run() {
}
};
t.setName("t1");
创建线程第二种方法:
//借助Thread的构造方法来创建一个线程
Runnable runnable = new Runnable() {
@Override
public void run() {
}
};
Thread thread = new Thread(runnable);
thread.start();
//也可以使用lambda表达式简写为
//Thread thread = new Thread(() -> {});
创建线程第三种方法,这种方法能够获取线程最终的结果,进行线程通信:
//使用FutureTask类
FutureTask<Integer> futureTask = new FutureTask<>(() -> {
Thread.sleep(1000);
return 100;
});
//将使用FutureTask类用来创建线程
Thread thread = new Thread(futureTask);
thread.start();
//使用get()方法获取线程的返回值
System.out.println(futureTask.get());
2.2、查看进程线程的方法
-
linux中查看进程和线程的方法

-
Java命令查看Java进程和线程

2.3、线程运行原理
Java中,每一个线程被开启时,都会随之创建一个虚拟机栈,用来保存线程中用到的信息。虚拟机栈的单元是栈帧,当线程中的一个方法被调用时,方法包含在栈帧中被入栈。每个虚拟机栈都具有一个程序计数器(PC),用来指示运行到了哪个指令。
在多线程环境下,Java虚拟机需要通过程序计数器记录CPU切换前解释执行到哪一句指令并继续解释执行。
线程上下文切换(Thread Context Switch)
线程从使用CPU到不适用CPU,称之为一次线程上下文切换。发生上下文切换的原因有:线程的cpu时间片用完、有更高优先级的线程需要运行(垃圾回收)、线程自己调用了sleep、yield、wait、lock等方法让出cpu使用权。
当线程上下文切换时,需要保存当前线程的状态(程序计数器、操作数栈、局部变量表等),并恢复另一个线程的状态。
Context Switch频繁切换会影响性能。
2.4、线程优先级
不同线程可以设置不同优先级。
线程优先级会提示 (hint) 调度器优先调度该线程,但它仅仅是一个提示,调度器可以忽略它。如果 cpu 比较忙,那么优先级高的线程会获得更多的时间片,但cpu闲时,优先级几乎没作用。所有的线程都会分到应有的时间片。
2.5、Thread常用方法
- start()和run()
在创建线程的时候,都会重写Runnable接口的run方法然后再创建Thread对象。Thread对象可以直接调用run方法,但是并不会开启一个新线程。而start方法会开启新线程并执行run方法。
- yield()和sleep()

TimeUnit.SECONDS.sleep(1);
//代替 Thread.sleep(1000);
sleep会让线程进入阻塞状态,在线程被唤醒之前,cpu不会将时间片交给阻塞状态的线程;
yield(让步)会让线程进入就绪状态,在此期间,cpu还是有可能将时间片交给就绪状态的线程。不过让出时间片确实会让该线程执行时间比起其他线程更少。
- join()和wait()
join()方法的作用是等待线程运行结束。它的另一个重载方法join(long time)等待线程结束后再等待time时间。
public static void main(String[] args) throws ExecutionException, InterruptedException {
Thread thread = new Thread(() -> {
System.out.println("开启一条线程");
});
//main线程会阻塞,等待thread线程结束
thread.join();
//只有thread线程结束后,main线程才能继续执行赋值语句
int result=1;
}
以下代码最终执行时间是2秒。
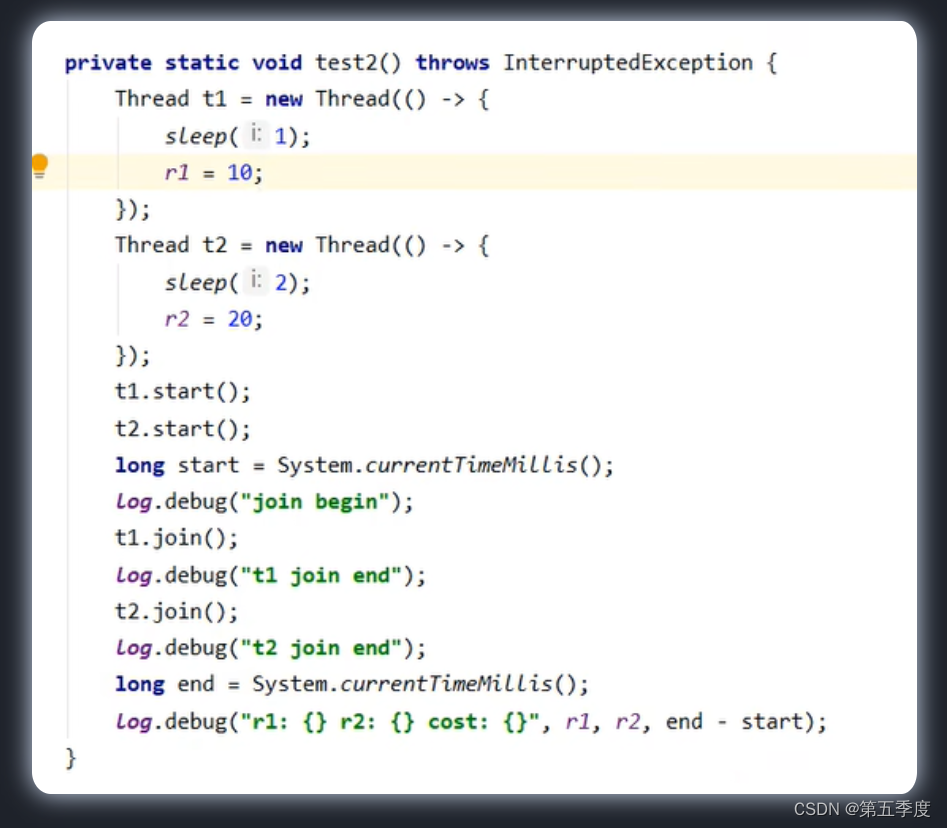
wait()方法是join()方法的底层实现。所以其实它们俩是一回事。
- interrupt()
这个方法的作用是发出打断线程的请求。
在主线程中创建一个t1线程对象,并让t1线程启动。之后可以在主线程中调用t1的interrupt方法通知t1停止运行。
对于非阻塞线程,interrupt方法并不是真的强硬打断线程,而是通过一个boolean类型的变量通知线程有打断的请求。可以通过t1.isInterrupted()查看有没有打断请求。由线程自己决定是否要结束运行。
对于阻塞线程,interrupt在打断阻塞(运行过sleep、wait、join)的线程时,阻塞状态被打断,会设置打断标志为true再设置为false,并且抛出异常。
在Thread类中还有另一个静态方法interrupt(),它的作用是发出打断线程的请求,**并且能够自动将isInterrupt置为false。**所以可以使用这个方法来将打断参数置为false。
2.6、主线程和守护线程
默认情况下, Java 进程需要等待所有线程都运行结束,才会结束(即便主线程结束了,只要还有线程存在,进程就不会结束)。有一种特殊的线程叫做守护线程,只要非守护线程运行结束了即使守护线程的代码没有执行完,也会强制结束。
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> {
while (true) {
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
//thread如果不被设置为守护线程,主线程结束了它也不会结束
//如果设置为守护线程,主线程结束了守护线程必定也结束了
thread.setDaemon(true);
}
垃圾回收器线程就是一种守护线程。
2.7、线程状态
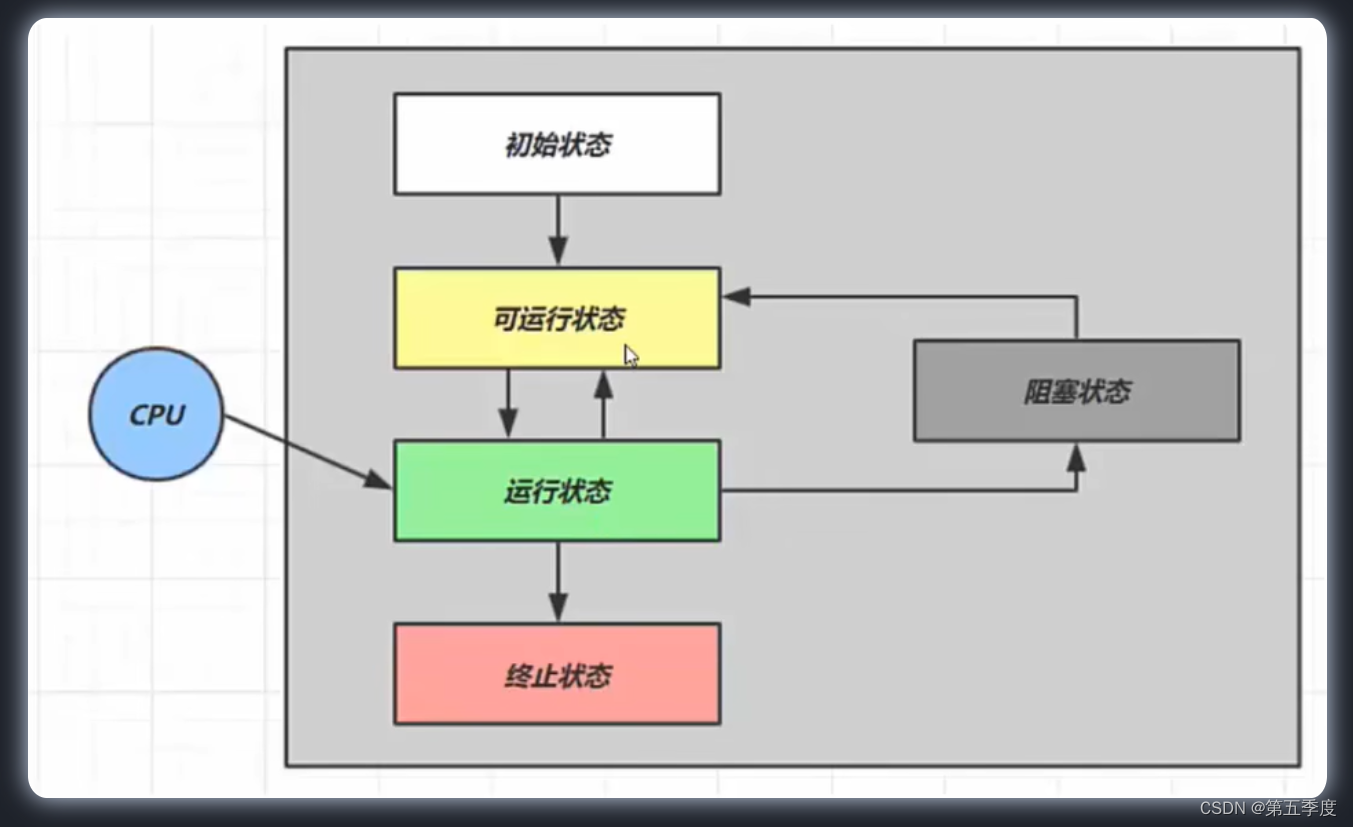
从操作系统层面进行描述,线程可以视为有五种状态。
-
初始状态。仅是在语言层面创建了呈对象,还耒与操作系统线程关联
-
可运行状态(就绪状态)。指该线程已经被创建(与操作系统线程关联),可以由 cpu 调度执行
-
运行状态。指获取了 CPU 时间片运行中的状态。当 cptJ 时间片用完,会从〔运行状态〕转换至【可运行状态】,会导致线程的上下文切换
-
阻塞状态。如果调用了阻塞 API,如 BIO 读写文件,这时该线程实际不会用到 CPU,会导致线程上下文切换,进入【阻塞状态】。等 BIO 操作完毕,会由操作系统唤醒阻塞的线程,转换至【可运行状态】。与【可运行状态】的区别是,对【阻塞状态】的线程来说只要它们一直不唤醒,调度器就一直不会考虑调度它们
-
终止状态。表示线程已经执行完毕,生命周期已经结束,不会再转换为其它状态。
关键是就绪状态、运行状态与阻塞状态之间的相互转换。就绪状态与运行状态通过线程上下文进行转换;如果阻塞状态被唤醒,线程就会变成就绪状态。
从Java API方面进行描述,线程可以分为六种状态(Thread中有一个State枚举类型记录了这六种状态)。
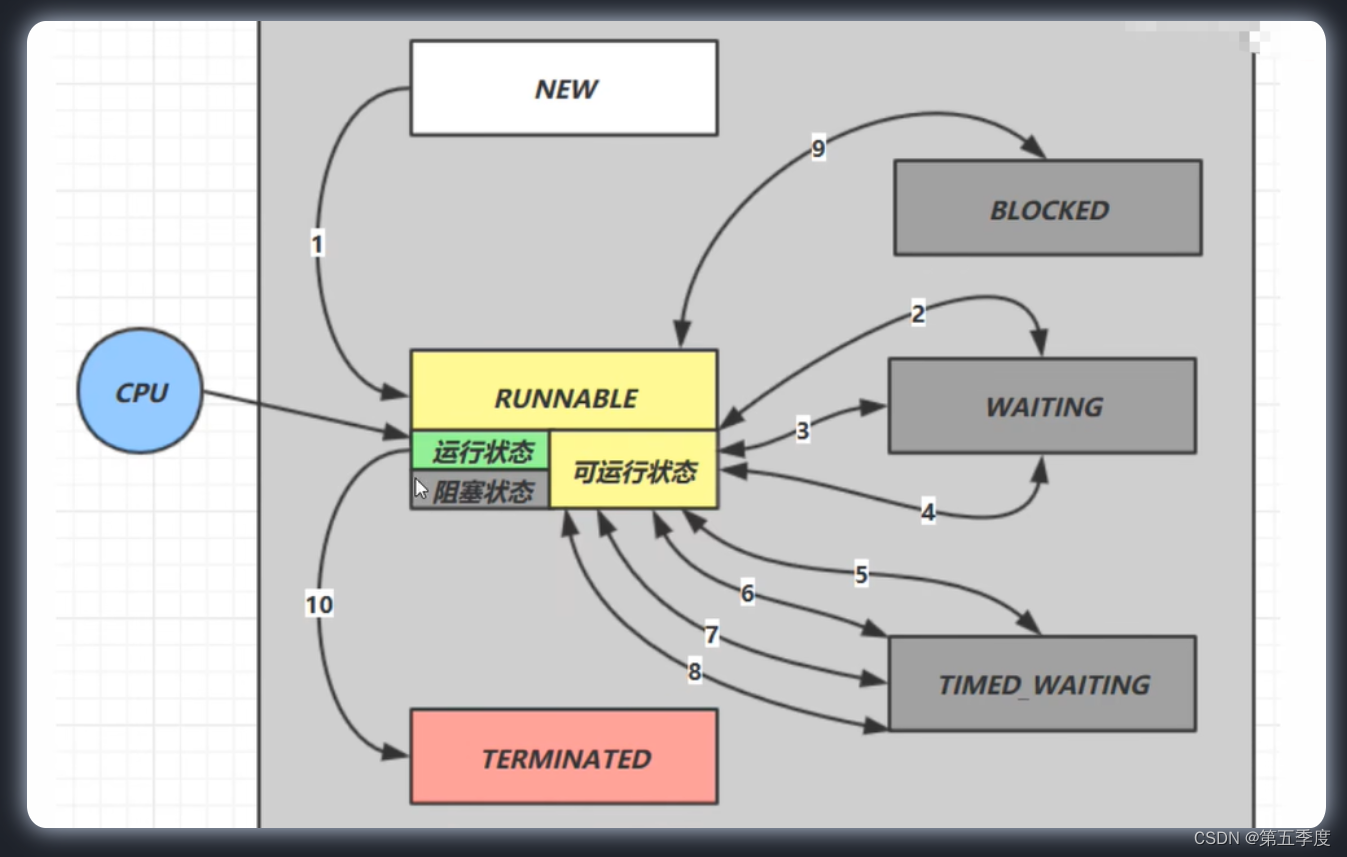
可以通过Thread对象的getState()方法来获知线程目前所处的状态。
- new:Thread线程对象创建但是还没有调用start()方法。
- runnable:线程对象正常执行方法(“正常”指没有被阻塞),拿到或者没有拿到时间片,都是runnable
- timed waiting:因为sleep等原因陷入有限期阻塞,在此期间线程是timed waiting
- waiting:线程需要其他线程才能继续执行,否则被其他线程阻塞,在此期间线程是waiting
- blocked:线程拿不到锁而陷入阻塞,称为blocked
3、共享模型之管程
多个线程访问共享资源时会带来一些问题。
比如说,两个线程对初始值为0的静态变量一个做自增,一个做自减,结果是0吗?
不会,结果可能是正数、负数、0,为什么呢?
这要从字节码指令说起。i++和i–的字节码指令如下:

在单线程环境下这些指令交替执行,不会出现问题:

但是在多线程环境下这些字节码指令可能会交错运行:
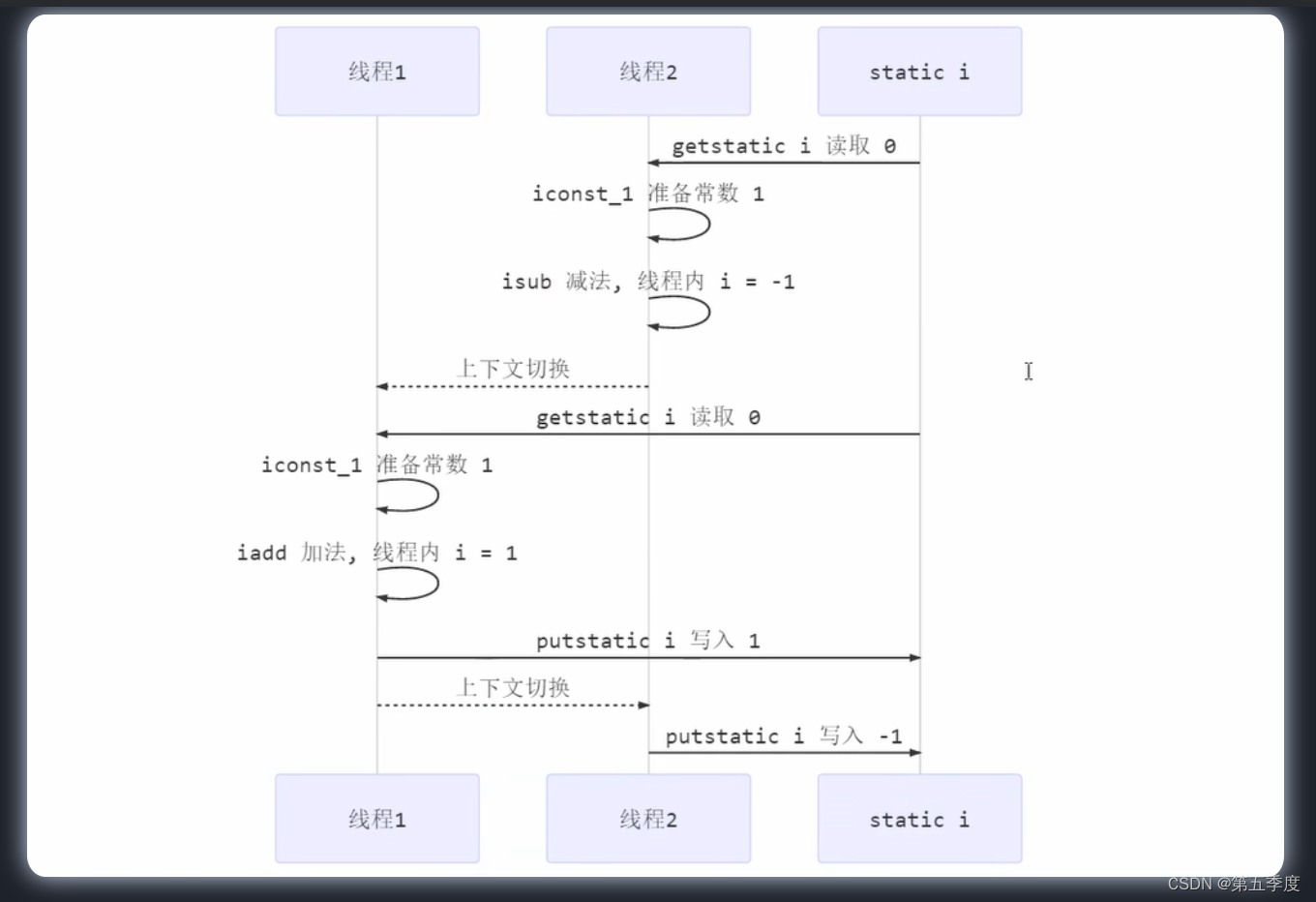
指令由于上下文切换发生错乱,所以经过i++和i–,原本应该为0的结果变成了-1。
在银行存钱取钱也会出现同样的问题。假设有两个客户对同一个存款为3000元的账户同时进行操作,第一个客户请求存入1000块,第二个客户请求取出2000块。两个请求进入服务端,Java创建了两条线程来处理请求。线程1(存入1000块)是这样操作的:先从数据库中查出存款3000块,+1000变成4000块,线程1刚要把4000块更新到数据库,发生了上下文切换。于是线程2(取出2000块)开始处理:先从数据库查出存款3000块,-2000块变成1000块,然后更新到数据库变成1000块。完毕后,线程上下文切换,线程1继续处理:将4000块存入数据库。最终账户中的钱从1000块更新为了4000块。正确的结果应该是2000块,但是最后,两位客户发现账户中多出了2000块。(如果线程2先拿到时间片,也有可能出现账户中剩下1000块钱。也有可能两个线程顺利地完整执行了各自方法,结果正确为2000)
出现这种问题的本质原因是因为线程上下文切换导致读写指令交错运行,但凡有一个线程的结果来不及写入,等到最终才有机会写入,就会出现错误覆盖。
一个程序执行多个线程其实是没有问题的,问题出在多个线程共享资源,读写操作指令错乱。
一段代码内如果存在对共享资源的读写操作,称这段代码块为临界区。多个线程在临界区内执行,由于代码的执行序列不同而导致结果无法预测,称为发现了竞态条件。
==对于临界区,一定要让其完整执行。==否则就会出现上述的线程不安全问题。如何让临界区的代码能够完整执行,避免出现线程上下文切换呢?
有多种方案可以达到目的:
- 阻塞式的解决方法:synchronized、lock
- 非阻塞式的解决方法:原子变量
3.1、synchronized对象锁
synchronized是Java中的一个关键字,意义是“同步”。
它实际上是使用互斥的方法对一段临界区代码设置了一个对象锁,同一时刻只有一个线程能够拿到对象锁,只有拿到对象锁的线程才能运行临界区代码。拿不到对象锁的线程会被阻塞(进入block状态),直到拥有对象锁的线程执行完临界区代码,会将对象锁释放并且唤醒所有的blocked线程(转为runnable状态),让runnable线程抢占对象锁。
synchronized(任意一个对象){
//临界区
}
synchronized并不会让线程拥有更多的时间片,能够完整执行完临界区代码。它只是允许拥有对象锁的对象进入临界区执行代码而已。该发生上下文切换一样会发生。不过如果切换到了被阻塞的线程,会继续进行上下文切换。

**synchronized实际上是使用对象锁保证了临界区内代码的原子性。**临界区相当于一个上锁的房间,synchronized传入的对象就相当于一个锁。
一些注意点:
- 可以拿共享资源对象作为锁,也可以拿其他对象作为锁(一般都是拥有共享资源所在的类的对象作为锁)。不过要保证操作共享资源的不同线程拥有的是同一把锁。如果操作共享资源的不同线程拥有不同的锁,那就意义了。
- 必须让所有的线程都加上synchronized,如果有线程没有synchronized,相当于该线程一直在加锁的“房间”内。
为了解耦可以把共享资源单独做成一个类,临界区代码上锁后做成一个该类的方法。线程直接调用该类的对象中的方法即可。
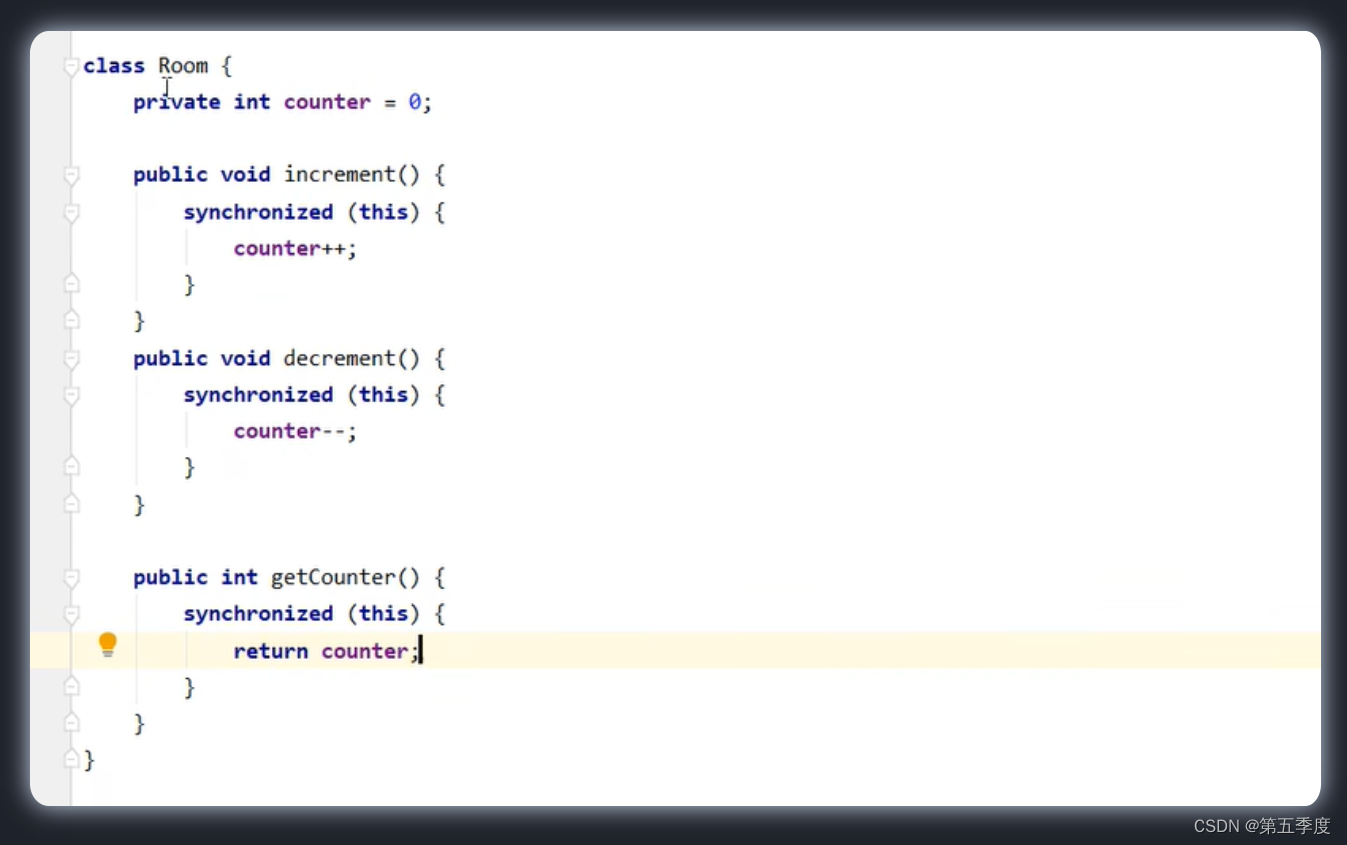
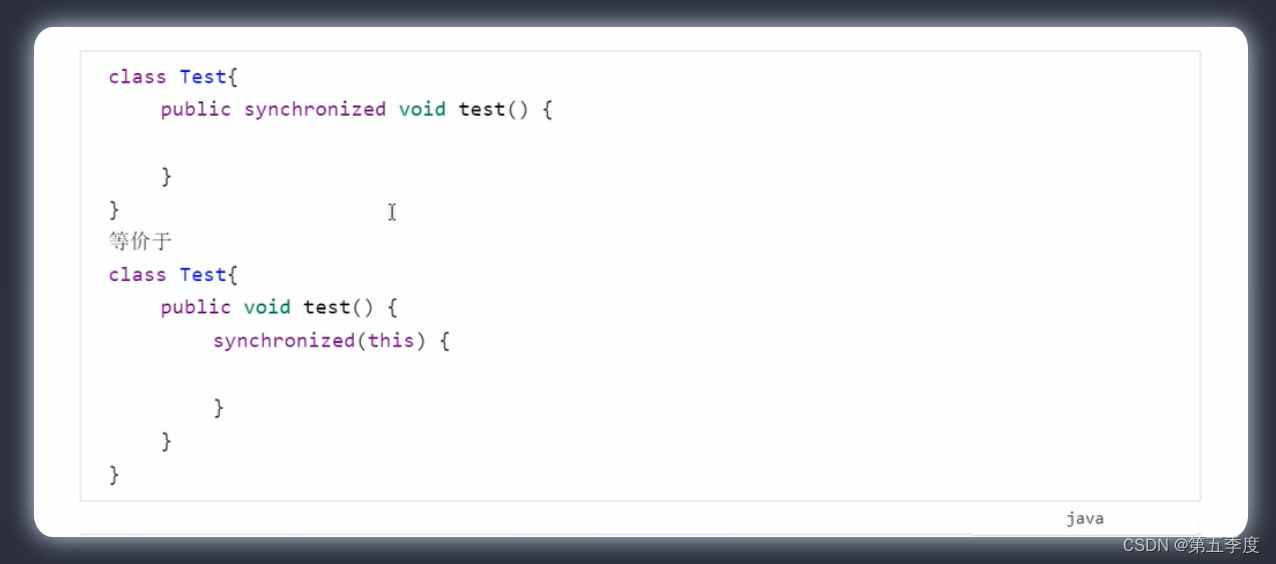
synchronized还有另外两种形式,它能加在实例方法和静态方法上。
加在实例方法上,不需要传入对象锁,因为默认的对象锁就是方法所在类的实例。
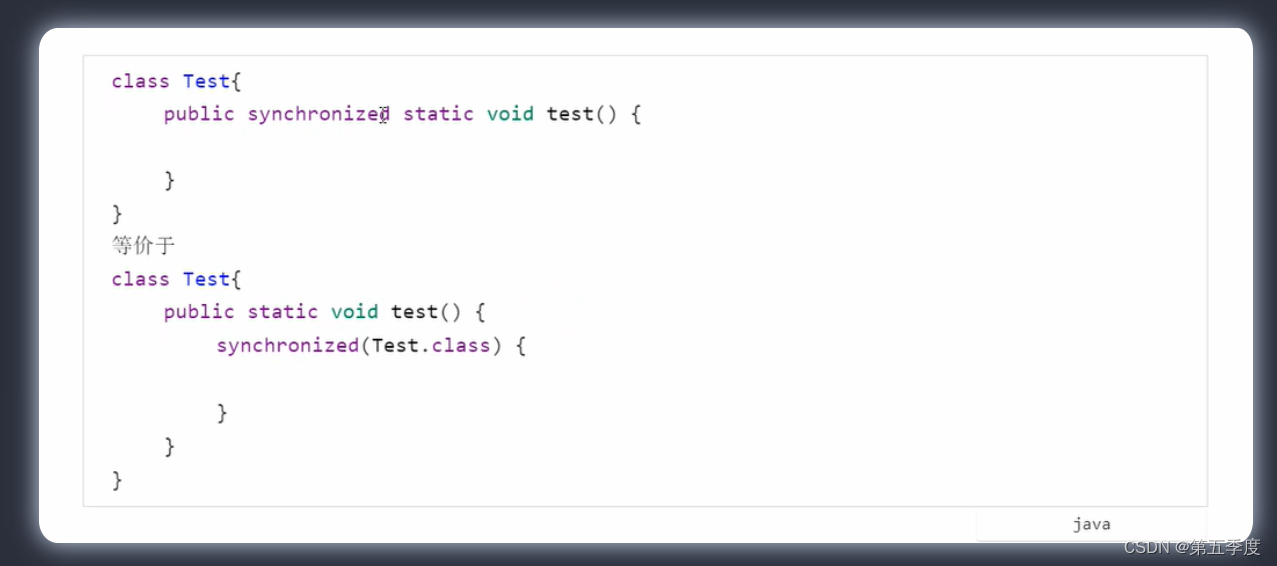
加在静态方法上,也不需要传入对象锁,默认的对象锁是静态方法所在类的Class对象。
这是一个常见的面试题,如果同时给静态方法和实例方法上锁,它们的对象锁是不一样的,将这两个方法分别放入两个线程,它们之间是不会存在互斥的现象的。
3.2、变量线程安全分析
成员变量和静态变量是否线程安全?
- 如果它们没有共享,则线程安全
- 如果它们被共享了
- 如果只存在读操作无写操作,线程安全
- 如果存在读写操作,线程不安全
方法中的局部变量是否线程安全?
-
局部变量不是引用类型,它是线程安全的。
-
局部变量是引用类型
- 如果该局部变量被闭包捕获,且闭包中局部变量的方法、成员变量不存在写操作,线程安全;如果闭包中局部变量方法、成员存在写操作,线程不安全
- 如果该局部变量没有被闭包捕获,线程安全
所以局部变量并不一定总是线程安全的。
闭包的概念:闭包是计算机科学中的一个概念,它是一个函数(或称为子程序)和其相关的引用环境的组合。一个函数和一个特定的环境结合在一起,就形成了一个闭包。这个环境包含了该函数可以访问的所有外部变量的引用。
闭包会让局部变量产生引用暴露,容易引发线程不安全问题。
public static void main(String[] args) throws InterruptedException { int i=1; Thread t1 = new Thread(() -> { int j=i; }); }这段代码中,主线程与t1线程是不同的线程,两个虚拟机栈具有不同的局部变量表,i应该不能被t1线程看到,但是存在于主线程中的局部变量i能够被t1线程读取是正确的,为什么?

lambda表达式捕获外部变量是可读不可写的,为什么?

lambda表达式闭包如果捕获了一个对象,该对象的引用不可写(不能重新赋值),但是对象中的方法和成员变量是可读可写的。这一点非常重要,因为往往有一些对象看似是局部变量,但是它被闭包捕获了,此时它仍然是线程不安全的。
3.3、常见线程安全类
- String
- Integer
- StringBulider
- Random
- Vector
- HashTable
- java.util.concurrent包下的类
这些方法线程安全指的是:它们的每个方法具有原子性。
注意,多个方法的组合不是线程安全的。多个原子方法的组合使用并不具有原子性。
3.4、重量级锁
Java对象头
任一个Java对象,都有一个对象头,分为Mark Word和Klass Word。记录了一些重要信息。Mark Word中有它的哈希值、它的年龄(用于垃圾回收)、它的加锁状态等。Klass Word有它的Class对象的引用。对象头也是要占用内存的。一个int类型有4个字节,但是一个Integer大概占用12个字节,多出的8个字节就是因为存在对象头。
每个Java对象都可以关联一个Monitor对象。什么时候关联呢?当使用synchronized给对象上锁之后,该对象的对象头中就有了指向Monitor对象的指针。Monitor对象是操作系统的对象,不是Java的对象。由于Java与Monitor对象交互会耗费很多资源,所以Monitor也称为重量级锁。
当线程1执行到synchronized(obj)的时候,会先检查obj有没有关联到Monitor,如果没有,给obj的对象头加上一个指向Monitor对象的指针,将对象的加锁标志从“01”(无锁)设置为“10”(Monitor锁),然后再设置线程1对象是Monitor的owner(owner是管程的一个属性)。线程2执行到synchronized(obj)的时候,发现obj已经关联上了Monitor,且管程的owner已经是线程1,故线程2会进入Monitor的EntryList(这是一个阻塞队列),然后线程2进入blocked状态,无法执行临界区的代码。
当线程1执行完临界区的代码,会让管程的owner清除线程1,清除对象头中的加锁标志,并且让阻塞队列中的所有线程出队,去竞争称为管程的owner(结果取决于jdk的实现)。
所以,一个线程如何得知它是否拿到了对象锁呢?这完全是由Monitor决定的。只要它是Monitor的owner,它就能执行临界区的代码。
总结:synchronized会让对象关联上Monitor,线程如果竞争到了Monitor的owner位置,就能执行临界区代码,否则只能进入Monitor的阻塞队列。阻塞队列和owner明确了到底有多少个线程在执行临界区的代码。
3.5、自旋优化
当对象被加了重量级锁,不是Monitor的owner的线程都会进入阻塞队列。
有时候,会出现这么一种情况:一个线程只要在进入阻塞队列前再多等一会儿,如果恰巧这时候重量级锁被释放了,它就可以顺利拿到对象,避免进入阻塞队列阻塞。
这就是所谓的自旋优化,它的原理是:让线程进入阻塞队列之前先执行几个占有对象的循环等待一会儿(自旋),如果自旋过程中重量级锁被释放了,说明自旋成功,它顺利占有对象;如果自旋过程中重量级锁没有被释放,说明自旋失败,它乖乖进入阻塞队列。
防止状态进入阻塞状态是有好处的。进入阻塞状态意味着要进行状态转换,有一定开销。
自旋优化在多核cpu下才有意义。如果是单核cpu,自旋的时候还要等cpu分时间片给它,会占用cpu的时间。只有多核cpu下,才不会占用cpu的时间。
在java6之后自旋是自适应的,比如线程的一次自旋成功过,那么认为此次自旋的成功率比较高,会多自旋几次,否则就少自旋甚至不自旋。
3.6、轻量级锁
如果一个对象虽然有很多线程访问但是没有竞争资源,这时候用Monitor锁过于耗费资源,可以使用轻量级锁进行优化。如果出现了竞争,轻量级锁还是会升级为重量级锁。
一个形象点的理解为:一个线程先不要使用Monitor,而是给对象打上一个非常简单的“使用中”标记。当线程发现有其他线程触碰了“使用中”标记,出于安全考虑,升级为Monitor。这样做的好处是,如果一直没有其他线程使用资源,那就节省了关联Monitor的重大开销;就算有其他线程使用资源,大不了像之前那样关联上Monitor,也不会有损失。这种锁是一种乐观锁,没有线程进行竞争的乐观情况。
轻量级锁仍然使用synchronized关键字。
轻量级锁的工作原理:
轻量级锁不再是在操作系统中进行。而是在栈帧中进行。线程运行到synchronized,首先会在栈帧中开辟一块区域Lock Record锁记录,该区域存放着一个lock record数据(包含锁记录的地址、锁定标志“00”)和锁定对象的地址。接下来,锁记录中的lock record数据会与锁定对象对象头中的Mark Word进行交换(注意:Mark Word中的锁定标志是“01”,表示未被锁定)。下边偏向锁的地方有一张图更加直观地查看锁记录的样子。
最终的状态是:执行到synchronized的线程的栈帧中出现了一块锁记录区域,其中存放着锁定对象的Mark Word和地址,而锁定对象的对象头Mark Word已经交换为lock record数据。
lock record数据与Mark Word数据交换的操作被称为cas交换操作,该操作是原子的。
当对象中的mark word位置中锁定标志是“01”,一个线程就能给该对象上轻量锁。
对象被线程1上完轻量锁之后,线程2也执行到了synchronized,它发现对象拥有“00”标志,被上了轻量锁,它不会试图执行cas操作,而是将该轻量锁升级为Monitor锁。由于对象中lock record记录了锁记录的地址,通过对象可以轻松找到将它锁住的线程,进而被线程升级Monitor锁。
轻量级锁上锁失败的情况:锁膨胀和锁重入:
- 其他线程已经持有对象的轻量级锁,表明有竞争,接下来会进入锁膨胀过程。
- 如果是持有轻量级锁的线程再次触碰了轻量级锁,说明发生了synchronized锁重入。这时候会再次添加一条Lock Record锁记录作为重入计数。
锁膨胀
线程1为对象加上了轻量锁,此时线程2触碰了轻量锁,会进入锁膨胀流程。
线程2通过对象的lock record找到线程1,接下来对象关联Monitor,线程1成为Monitor的owner。线程2进入Monitor的阻塞队列。
没有锁膨胀的解锁流程:
当线程1执行完临界区的代码,想要解锁对象,使用cas操作恢复对象的对象头和线程的锁记录,对象解锁。
锁膨胀解锁流程:
当线程1执行完临界区的代码,想要解锁对象,使用cas操作试图恢复,失败(因为此时对象指向的是Monitor的地址,且加锁标志是“10”(重量锁)而不是“00”(轻量锁))。所以首先进入解锁Monitor重量锁的流程。当重量锁解锁后,对象恢复成轻量锁,再使用cas恢复对象头,轻量级锁解除。(由于对象在加Monitor锁的时候已经复制了一份留待解锁重量锁恢复用,所以解锁的时候对象已经恢复成轻量锁的状态了。)。
锁重入
所谓锁重入,就是锁中加锁。比如:
public class Main { static ArrayList<Integer> arrayList = new ArrayList<>(); public static void main(String[] args) throws InterruptedException { new Thread(()->{ method1(); }); } public static void method1(){ synchronized (arrayList){ method2(); } } public static void method2(){ synchronized (arrayList){ } } }线程再次执行了一个方法,并且该方法将对象再次上锁。这时候线程中会产生一个新的栈帧method2,且其中会出现锁记录。当method2的锁记录试图使用cas操作交换对象的Mark Word的时候,会失败,因为此时对象已经被上了轻量锁。但是它发现给对象上轻量锁的正是自己所在线程中的另一条锁记录,所以它不会升级锁,而是转而在自己的锁记录中记录锁重入的次数。
所以锁重入还是会加锁成功,不过锁记录中记载的是锁重入的计数。清除锁重入的锁时,由于lock record是null,所以直接清除然后锁重入计数减1即可。
3.7、偏向锁
轻量级锁虽好,但是如果出现了锁重入,仍然会试图执行cas操作来检查对象是否被加锁。cas操作会消耗一定的性能。
可以引入偏向锁进行优化:线程给对象加锁的时候直接将将线程的id记录到对象的对象头之中。之后,如果发现这个对象是自己线程占有的,就表示没有竞争。

Java6之后,一个对象在创建的时候,它的后3位是001,之后(也即延迟),会默认将该对象的后3位变为101,表示该对象具有偏向状态,之后使用synchronized的时候,优先加偏向锁。偏向状态标志设置并不是在程序启动时就开启,而是会有一定的延迟。
由于偏向状态101的设置会让hashcode的位置被占用,所以,如果一个对象设置了偏向状态,之后又调用了hashcode,那么偏向状态会被撤销,重新回到001的状态。
当线程1占有对象的偏向锁时,同步未结束,此时线程2想要占有对象的偏向锁,会导致偏向锁升级为轻量级锁,如果此时其他线程进行了CAS,会再升级为重量级锁。
偏向锁并不会主动撤销。即:如果线程1为对象添加了偏向锁,当线程1同步结束后,对象仍然存在线程1的偏向锁。
当线程1占有对象的偏向锁,且同步已经结束,此时线程2想要同步对象,会将对象的偏向锁撤销,并升级为线程2的轻量级锁,线程2同步完毕后,轻量级锁被释放,对象恢复为无锁可偏向状态。
3.8、批量重偏向和批量撤销
如果线程1中对同一个类的大量对象(超过20个,比如30个)加偏向锁,线程1同步完毕后,这些对象仍然偏向线程1。
之后,线程2开始同步,在线程2中,也对这30个对象加锁。
首先线程2会将20个对象的偏向线程1的偏向锁撤销,并加上轻量级锁。等到第21个,由于jvm发现一直在撤销偏向锁,会开始转换策略,把第21个到第30个的对象全部转为偏向于线程2的偏向锁,这样就不用撤销偏向锁并加轻量锁了,节省下一部分开销。
这就是批量重偏向。批量重偏向的目的是在偏向锁频繁撤销的情况下减少开销,通过将对象的偏向锁重偏向至当前频繁请求锁的线程,可以减少未来的锁撤销次数。当对象数量超过某个阈值时(默认20,可以通过JVM启动参数-XX:+PrintFlagsFinal查看此阈值),Java会对超过的对象进行批量重偏向,此时前20个对象是轻量锁,后面的对象都是偏向锁,且偏向于线程2。
线程1和线程2。线程1对50个对象加锁,同步完毕后,到了线程2。
线程2对前20个对象撤销偏向锁并升级为轻量锁。第20个到第40个批量重偏向,到了第41个,jvm会认为批量重偏向开销也太大了,接下来它不再进行任何重偏向操作,而是转而将这些对象对应类的所有对象都设置为不可偏向状态001,并撤销所有偏向锁。并且,使用该类创建出来的所有对象也是不可偏向的。
3.9、锁消除
JVM实际上是通过解释+编译的方式来运行Java字节码的。对于普通代码,JVM会进行解释;对于热点代码,JVM会使用JIT(即时编译)对代码进行优化。
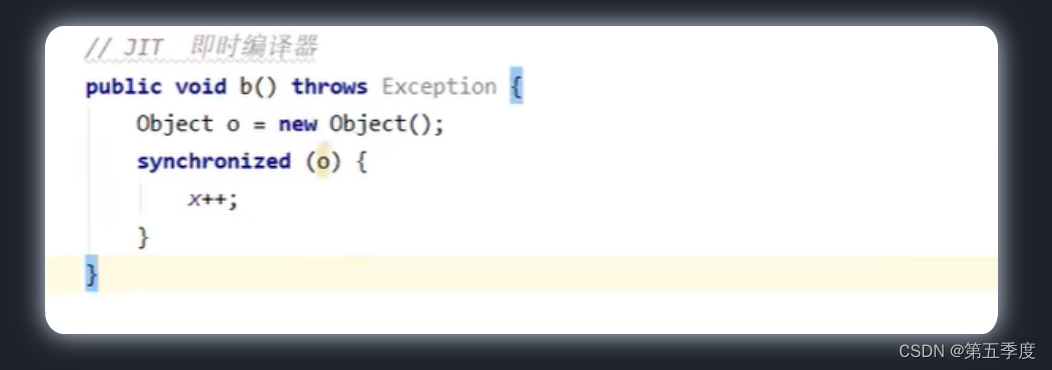
比如这段代码中,JVM发现对象o的作用域根本不会逃离b方法,所以它会直接将锁给优化掉,也即不会对o进行加锁。如此一来,就出现了锁消除的效果。
锁消除是默认打开的,如果想要关闭,可以通过设置JVM参数进行关闭。
3.10、wait/notify
如果想要让获得了Monitor锁的线程停下来,放弃锁进入阻塞状态,之后再让线程在某个时候被唤醒,那么就可以使用wait()方法和notify()方法。wait()方法和notify()方法在创建一个类之后,就默认继承了这两个方法。
调用线程的wait()方法会让线程进入Monitor管程的WaitSet,此时该线程会立刻阻塞,进入waiting状态,不占用cpu时间片。
当Monitor的owner线程执行到notify()方法时,WaitSet之中的线程才会被唤醒,进入EntrySet之中,参与竞争锁。
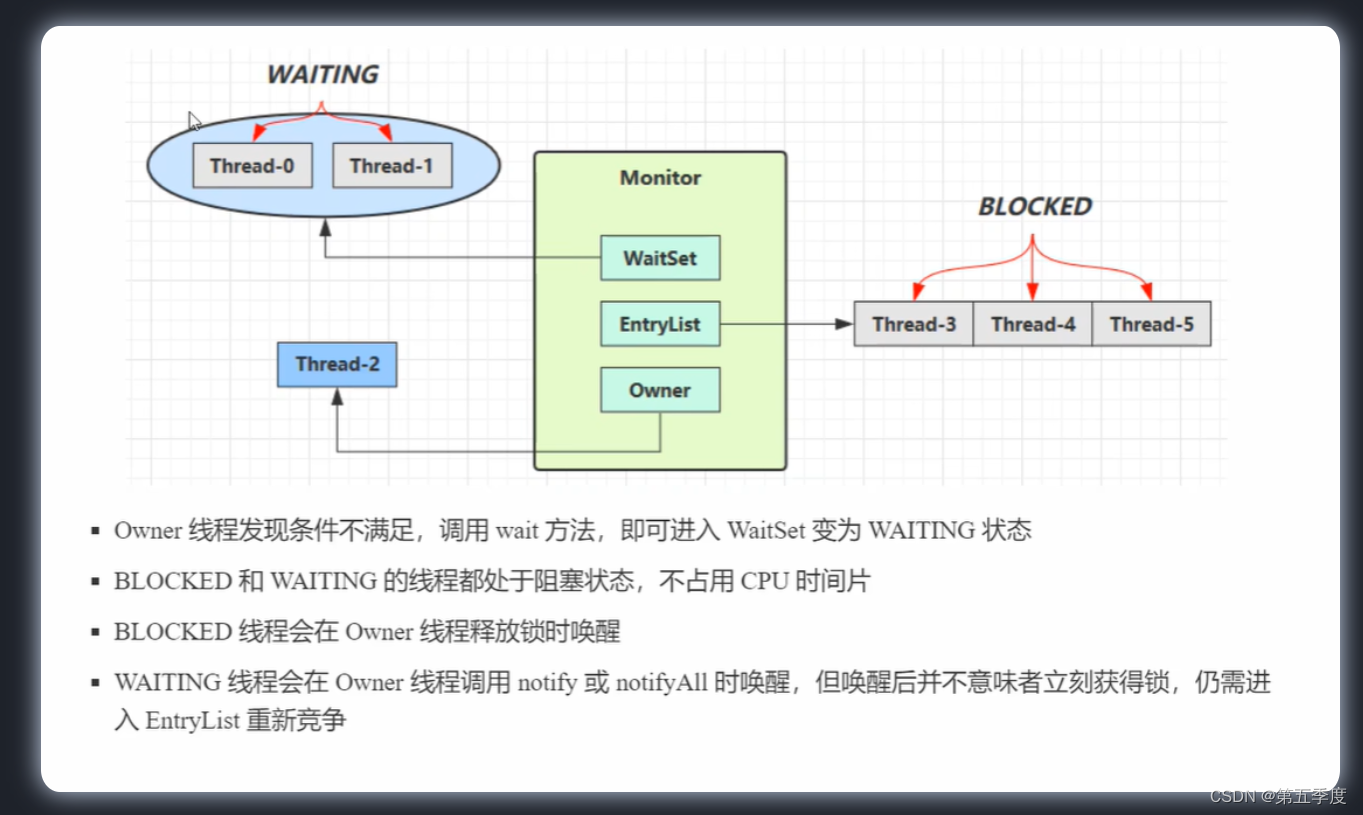
EntrySet和WaitSet中的线程的区别:
- EntrySet之中的线程是未拿到锁的线程,它们处于blocked状态
- WaitSet之中的线程是拿到过锁,但是又放弃了锁的线程,它们处于waiting状态。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 6. Blazor官方案例BlazingPizza
- interpret,一个超酷的 Python 库
- 金蝶云星空业务对象扩展
- 每日一题——LeetCode961
- re:从0开始的HTML学习之路 2. HTML的标准结构说明
- 搭建一套洗衣洗鞋上门预约小程序系统有多个方便
- 金蝶Apusic应用服务器 loadTree JNDI注入漏洞
- Spring Cloud中的提供者与消费者
- 100:ReconFusion: 3D Reconstruction with Diffusion Priors
- Python学习笔记之(一)搭建Python 环境