7_1 tesseract 安装及使用
1、 安装tesseract
OCR,即Optical Character Recognition,光学字符识别,是指通过扫描字符,然后通过其形状将其翻译成电子文本的过程。对于图形验证码来说,它们都是一些不规则的字符,这些字符确实是由字符稍加扭曲变换得到的内容。
tesseract下载地址:
链接:https://pan.baidu.com/s/1WyduWNeu4OK38sx4FZIhvQ
提取码:hcfl
进入下载页面,可以看到有各种.exe文件的下载列表,这里可以选择下载4.0版本。
接下来,为了在python代码中使用tesseract功能,使用pip安装pytesseract:
pip install pytesseract
2、配置环境变量
为了在全局使用方便,比如安装路径为D:\install\tesseract-ocr-v4.0.0\Tesseract-OCR,将该路径添加到系统环境变量的path中
并且增加系统环境变量TESSDATA_PREFIX? ??变量值中的路径为D:\install\tesseract-ocr-v4.0.0\Tesseract-OCR\tessdata
配置完成后在命令行输入tesseract -v,如果出现如下图所示,说明环境变量配置成功
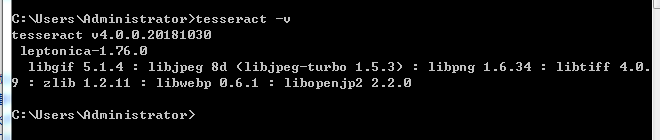
3、验证安装(命令行)
接下来,我们可以使用tesseract进行测试。
我们以如下图所示的图片为样例进行测试。

?用命令行进行测试,将图片下载到D盘pythonTest文件夹,保存为test.jpg,然后在该文件夹中打开命令行,用tesseract命令测试:
tesseract test.jpg result
会在test.jpg目录下生成result.txt文件结果
4、识别中文字体(命令行)
如果安装时没有下载中文字体(FQ下载勾选了就有)就需要自已添加中文字体库
4.1 下载
链接:https://pan.baidu.com/s/1QpdXJrlFVvgBsGT0Ly4Xpw
提取码:amt0
python 利用tesseract识别文字报错(内含中文包下载地址)_failed loading language \'chi_sim\' tesseract coul-CSDN博客
或者:Tesseract最新版语言包chi_sim.traineddata(4.0.0)GitHub官方获取免csdn积分,各个版本语言包全有-CSDN博客
把下载的中文训练库放入D:\install\tesseract-ocr-v4.0.0\Tesseract-OCR\tessdata中
4.2? 测试
应用中文字体图片,测试和步骤3方法相同。
查看能识别的语言:
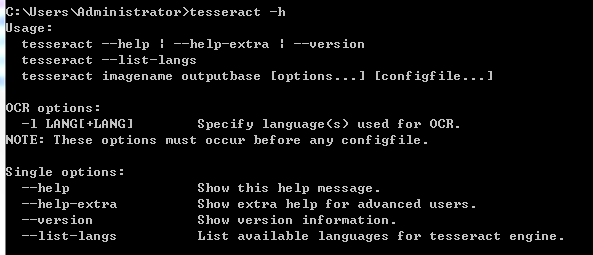
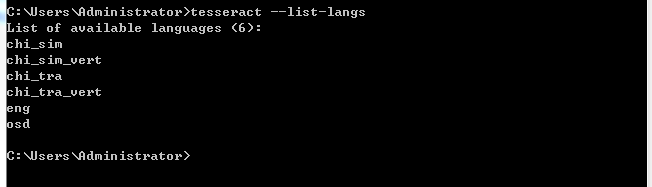
chi_sim? ? 代表中文简体。
?5、利用Python代码来测试
![]()
1 """tesseract""" 2 3 4 from PIL import Image 5 import pytesseract 6 7 # 识别英文 8 image = Image.open(r'D:\pythonTest\4.jpg') 9 text = pytesseract.image_to_string(image) 10 print(text) 11 12 # 识别中文简体 13 image_chi = Image.open(r'D:\pythonTest\2.png') 14 text_chi = pytesseract.image_to_string(image_chi, lang='chi_sim') 15 print(text_chi)
![]()
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- hql、数据仓库、sql调优、hive sql、python
- 5.微服务代码模型
- 各模块的实现
- java常见的锁的类型
- vi/vim 编辑器 --基本命令
- 《Git学习笔记:IDEA整合Git》
- Java多线程编程中的异常处理策略
- 本地部署Jellyfin影音服务器并实现远程访问内网影音库
- 模仿Activiti工作流自动建表机制,实现Springboot项目启动后自动创建多表关联的数据库与表的方案
- BUUCTF--get_started_3dsctf_20161