使用C语言实现文件的拷贝——底层内存分析
使用C语言实现文件的拷贝
本文主要涉及sprintf()函数的讲解以及系统IO与标准IO的区别和一个实例使用C语言实现文件的拷贝,在最后还深度刨析了文件拷贝的底层原理。
文章目录
一、 sprintf()函数
1.1 sprintf ()函数的参数解析
sprintf() 是 C 语言中的一个标准库函数,用于将格式化的数据写入字符串中。它的功能与 printf() 相似,但是 printf() 会将格式化的数据写入标准输出(通常是屏幕),而 sprintf() 则将数据写入一个字符串。
sprintf() 的原型如下:
#include <stdio.h>
int sprintf(char *str, const char *format, ...);
其中:
-
str:是一个字符数组或字符指针,用于存储格式化的输出字符串。在调用sprintf()之前,str应该已经分配了足够的空间来存储生成的字符串,以防止缓冲区溢出。 -
format:是一个字符串,它包含了一个或多个格式说明符,用于指定如何格式化输出的数据。
sprintf() 函数与 printf() 函数在格式说明符和用法上是相同的,但是它不输出到标准输出,而是将结果写入 str 指定的字符串中。
1.2 sprintf()函数将整数和浮点数格式化为字符串
以下是一个 sprintf() 的简单示例:
#include <stdio.h>
int main() {
char buffer[100];
int num = 12345;
float fnum = 67.89;
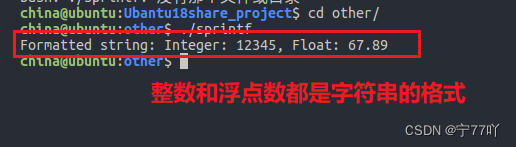
// 使用 sprintf 将整数和浮点数格式化为字符串
sprintf(buffer, "Integer: %d, Float: %.2f", num, fnum);
// 打印生成的字符串
printf("Formatted string: %s\n", buffer);
return 0;
}
在上述示例中,sprintf() 将整数 num 和浮点数 fnum 格式化为一个字符串,并存储在 buffer 中。然后,我们使用 printf() 打印生成的字符串。
需要注意的是,为了安全起见,当使用 sprintf() 时,应确保目标字符串(即第一个参数 str)有足够的空间来存储格式化后的字符串,以防止缓冲区溢出。
二、 系统 I/O(Input/Output)和标准 I/O
系统 I/O(Input/Output)和标准 I/O 都是在计算机编程中用于数据输入和输出的概念,但它们之间存在一些区别。以下是对这两者的简要说明:
-
系统 I/O(Low-Level I/O):
- 系统 I/O 指的是直接使用操作系统提供的系统调用(system calls)进行输入/输出操作。
- 这种 I/O 是直接的、底层的,通常涉及到操作系统的内核级别。
- 例如,在UNIX/Linux系统中,系统调用如
read和write用于从文件描述符(file descriptors)进行读写。 - 系统 I/O 更接近底层硬件操作,通常提供了更细粒度的控制,但使用它可能需要处理更多的细节和复杂性。
-
标准 I/O(Standard I/O or Buffered I/O):
- 标准 I/O 是在系统 I/O 之上构建的高级 I/O 概念。
- 它使用了缓冲区(buffer)来优化数据的读写,减少了直接调用系统调用的频率,从而提高了性能。
- 在C语言中,标准 I/O 是通过库函数实现的,如
stdio.h提供的fopen,fclose,fread,fwrite,fprintf,fscanf等函数。 - 标准 I/O 提供了对流(stream)的概念,如文件流、标准输入流(stdin)、标准输出流(stdout)等。
- 标准 I/O 通常更易于使用和管理,因为它隐藏了底层的细节和复杂性。
总结:
- 系统 I/O 是直接的、底层的 I/O 操作,通常使用系统调用来进行读写,提供了更细粒度的控制。
- 标准 I/O 是基于系统 I/O 构建的高级 I/O 抽象,使用缓冲区来优化数据的读写,提供了更简洁、易于使用的接口。
在实际编程中,通常建议使用标准 I/O,除非有特定的需求或优化目标需要使用系统 I/O。标准 I/O 提供了足够的性能,并且更易于管理和维护。
三、 C语言实现文件的拷贝
3.1 实现效果要求
使用C语言实现cp函数一样的效果,进行文件的拷贝。
执行要求:
执行:./a.out ./1.txt …/2.txt
执行代码./a.out 后将当前文件下的./1.txt 拷贝到 …/2.txt
3.2 实现代码
#include <string.h>
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
int main(int argc, char *argv[]) {
if (argc != 3) {
fprintf(stderr, "Usage: %s <source_file> <destination_file>\n", argv[0]);
return 1;
}
const char *file1 = argv[1];
const char *file2 = argv[2];
// 打开源文件
int fd_source = open(file1, O_RDONLY);
if (fd_source == -1) {
perror("Error opening source file");
return 1;
}
// 获取源文件的权限
struct stat stat_source;
if (fstat(fd_source, &stat_source) == -1) {
perror("Error getting source file status");
close(fd_source);
return 1;
}
// 创建或打开目标文件
int fd_dest = open(file2, O_WRONLY | O_CREAT | O_TRUNC, stat_source.st_mode);
if (fd_dest == -1) {
perror("Error opening destination file");
close(fd_source);
return 1;
}
// 读取源文件并写入目标文件
char buffer[1024];
ssize_t bytes_read;
while ((bytes_read = read(fd_source, buffer, sizeof(buffer))) > 0) {
if (write(fd_dest, buffer, bytes_read) != bytes_read) {
perror("Error writing to destination file");
close(fd_source);
close(fd_dest);
return 1;
}
}
// 关闭文件描述符
close(fd_source);
close(fd_dest);
printf("File copied successfully.\n");
return 0;
}
read(fd_source, buffer, sizeof(buffer)):从 fd_source 文件描述符中读取数据,将读取的数据存储在 buffer 中,最多读取 buffer 的大小(即 1024 字节)。
如果 read 调用成功并读取了数据,bytes_read 将存储实际读取的字节数。
当 read 返回0(表示已到达文件末尾)或者返回一个错误(read 返回 -1)时,循环将结束。
3.3 实现效果
执行命令:

执行效果:
3.4 实现文件拷贝的底层内存刨析
当你从底层内存角度考虑文件复制操作时,实际上涉及到数据在计算机系统中的存储和处理方式。以下是从底层内存的角度详细解释文件拷贝的过程和原因:
-
数据的存储:
- 文件数据存储在硬盘或其他存储设备上的磁盘块中。
- 当你打开一个文件进行读取时,操作系统将这些磁盘块的内容读入内存的页缓存中。这样做是为了加速后续的读取操作,因为内存的读写速度远高于磁盘。
-
系统调用与缓冲:
- 使用
open和read系统调用时,操作系统会处理数据的缓冲和调度,确保数据被有效地从磁盘读入内存。 - 同样,使用
write系统调用时,操作系统会确保数据从内存写回到磁盘。
- 使用
-
数据的传输:
- 在执行文件复制时,数据首先从源文件的内存缓存中被读取到应用程序的地址空间(通常是通过
read系统调用实现的)。 - 然后,这些数据从应用程序的地址空间被写入到目标文件的内存缓存中(通过
write系统调用)。 - 最终,操作系统会确保目标文件的内存缓存中的数据被写回到磁盘上的相应位置。
- 在执行文件复制时,数据首先从源文件的内存缓存中被读取到应用程序的地址空间(通常是通过
-
性能考虑:
- 文件拷贝操作在内存和磁盘之间进行,这通常比直接在磁盘之间进行文件拷贝更快。因为内存操作的速度远快于磁盘操作。
- 此外,操作系统和硬件通常有各种优化,如预读、预写、缓冲等,进一步提高了数据传输的效率。
-
数据的完整性和一致性:
- 在数据传输过程中,操作系统会确保数据的完整性和一致性。这意味着,除非操作系统确定数据已经被完全写入目标文件,否则不会认为写操作已经完成。
总之,从底层内存的角度看,文件复制涉及数据在内存和磁盘之间的传输,操作系统在其中扮演了关键的角色,确保数据的正确、高效地传输。这也解释了为什么直接在磁盘之间执行文件拷贝通常比先将数据加载到内存中再写回更加高效。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- EarMaster Pro 7 简体中文破解版 v7.2.0.42 电脑版
- vue 中使用低版本高德地图1.4 , 解决热力图渲染展示在可视化区域内使用setFitViewt跳转不起作用,计算地图的缩放级别和中心点
- 更新钉钉文档封装好的代码
- 【图像分类】【深度学习】【轻量级网络】【Pytorch版本】ShuffleNet_V2模型算法详解
- STM32 串口Uart2频繁收发至其卡死的解决方案-基于正点原子库函数分析
- 六个实用的Python数据可视化图表
- React、Vue3中父组件如何调用子组件内部的方法
- CC工具箱使用指南:【属性映射】
- windows 插入的机械硬盘没有出现对应的硬盘,发现硬盘状态为没有初始化,磁盘分区形式为不适用
- 代码随想录算法训练营第25天 | 216.组合总和III + 17.电话号码的字母组合