翻译: Streamlit从入门到精通 高级用法缓存Cache和Session 五
Streamlit从入门到精通 系列:
- 翻译: Streamlit从入门到精通 基础控件 一
- 翻译: Streamlit从入门到精通 显示图表Graphs 地图Map 主题Themes 二
- 翻译: Streamlit从入门到精通 构建一个机器学习应用程序 三
- 翻译: Streamlit从入门到精通 部署一个机器学习应用程序 四

现在您已经了解了 Streamlit 应用程序如何运行和处理数据,让我们来谈谈效率。缓存允许您保存函数的输出,以便在重新运行时跳过它。会话状态允许您保存在重新运行之间保留的每个用户的信息。这不仅可以避免不必要的重新计算,还可以创建动态页面并处理渐进式流程。
1. Caching 缓存
Streamlit 缓存使您的应用程序即使在从 Web 加载数据、操作大型数据集或执行昂贵的计算时也能保持性能。
缓存背后的基本思想是存储成本高昂的函数调用的结果,并在再次出现相同的输入时返回缓存的结果,而不是在后续运行时调用函数。
要在 Streamlit 中缓存函数,您需要使用以下两个装饰器(st.cache_data 和 st.cache_resource)之一来装饰它:
@st.cache_data
def long_running_function(param1, param2):
return …
在此示例中,使用 @st.cache_data 装饰long_running_function告诉 Streamlit,每当调用该函数时,它都会检查两件事:
- 输入参数的值(在本例中为
param1和param2)。 - 函数内部的代码。
如果这是 Streamlit 第一次看到这些参数值和函数代码,它会运行该函数并将返回值存储在缓存中。下次使用相同的参数和代码调用函数时(例如,当用户与应用程序交互时),Streamlit 将完全跳过执行该函数并返回缓存的值。在开发过程中,缓存会随着函数代码的变化而自动更新,从而确保最新的更改反映在缓存中。
如前所述,有两个缓存装饰器:
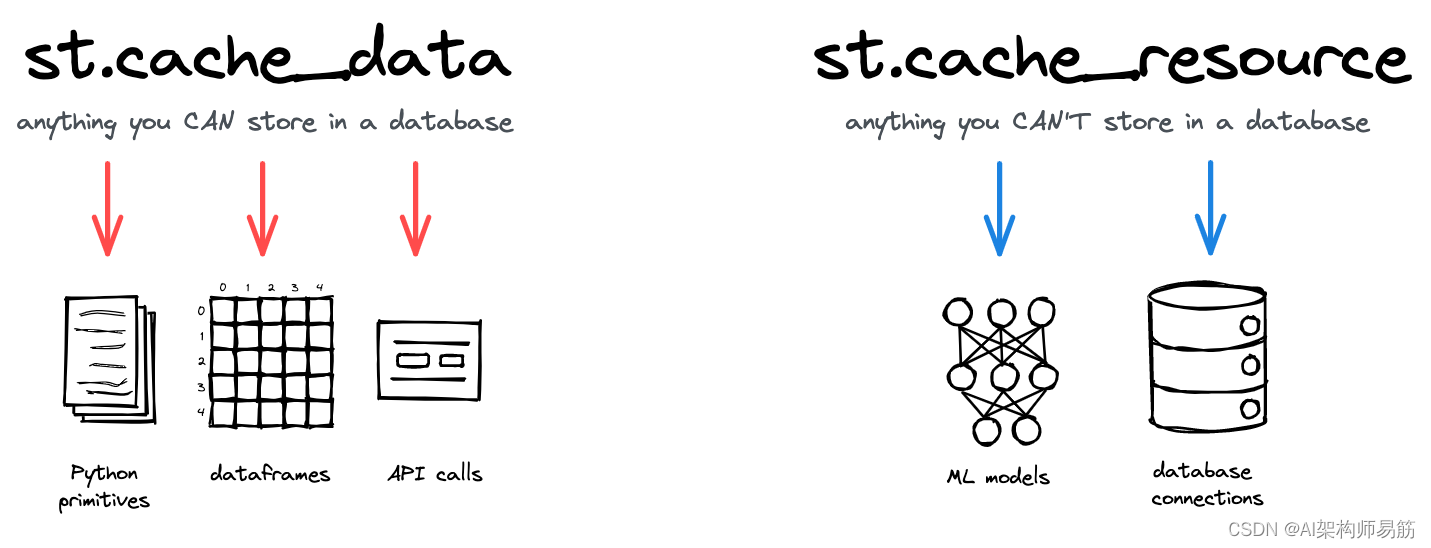
st.cache_data是缓存返回数据的计算的推荐方法:从CSV加载DataFrame、转换NumPy数组、查询API或任何其他返回可序列化数据对象的函数(str、int、float、DataFrame、array、list 等)。它会在每次函数调用时创建一个新的数据副本,使其免受突变和竞争条件的影响。st.cache_data的行为是您想要的——所以如果您不确定,请从st.cache_data开始,看看它是否有效!st.cache_resource是缓存全局资源(如 ML 模型或数据库连接)的推荐方法,这些资源是您不想多次加载的不可序列化对象。使用它,您可以在应用程序的所有重新运行和会话之间共享这些资源,而无需复制或复制。请注意,对缓存返回值的任何突变都会直接改变缓存中的对象(更多详细信息见下文)。
有关 Streamlit 缓存装饰器、其配置参数及其限制的详细信息,请参阅缓存。
2. Session State 会话状态
会话状态提供了一个类似于字典的界面,您可以在其中保存在脚本重新运行之间保留的信息。使用带有键或属性表示法st.session_state来存储和调用值。例如,st.session_state["my_key"] 或 st.session_state.my_key。请记住,小部件会自行处理其状态,因此您不必总是使用会话状态!
2.1 什么是会话Session?
会话是查看应用程序的单个实例。如果您从浏览器中的两个不同选项卡查看应用程序,则每个选项卡都有自己的会话。因此,应用的每个查看者都将有一个与其特定视图相关联的会话状态。Streamlit 在用户与应用程序交互时维护此会话。如果用户刷新其浏览器页面或重新加载应用的 URL,则其会话状态将重置,并重新开始新的会话。
2.2 使用会话状态的示例
这是一个简单的应用程序,用于计算页面的运行次数。每次单击该按钮时,脚本都会重新运行。
import streamlit as st
if "counter" not in st.session_state:
st.session_state.counter = 0
st.session_state.counter += 1
st.header(f"This page has run {st.session_state.counter} times.")
st.button("Run it again")
- 首次运行:首次为每个用户运行应用时,“会话状态”为空。因此,将创建一个键值对
("counter":0)。随着脚本的继续,计数器会立即递增("counter":1),并显示结果:“此页面已运行 1 次。当页面完全呈现时,脚本已完成,Streamlit 服务器等待用户执行某些操作。当该用户单击该按钮时,将开始重新运行。 - 第二轮:由于“counter”已经是会话状态中的键,因此不会重新初始化。随着脚本的继续,计数器将递增
("counter":2),并显示结果:“此页面已运行 2 次。
在一些常见情况下,会话状态很有帮助。如上所示,当您有一个渐进式进程,并且希望从一次重新运行到下一次重新运行时,将使用会话状态。会话状态还可用于防止重新计算,类似于缓存。但是,这些差异很重要:
- Cache缓存将存储的值与特定函数和输入相关联。所有会话中的所有用户都可以访问缓存的值。
- Session会话状态将存储的值与键(字符串)相关联。会话状态中的值仅在保存该值的单个会话中可用。
如果您的应用中具有随机数生成功能,则可能会使用会话状态。下面是一个示例,其中数据在每个会话开始时随机生成。通过将这些随机信息保存在会话状态中,每个用户在打开应用程序时都会获得不同的随机数据,但在他们与应用程序交互时,这些数据不会不断变化。如果使用选取器选择不同的颜色,则会看到数据不会在每次重新运行时重新随机化。(如果您在新选项卡中打开应用程序以开始新会话,您将看到不同的数据!
import streamlit as st
import pandas as pd
import numpy as np
if "df" not in st.session_state:
st.session_state.df = pd.DataFrame(np.random.randn(20, 2), columns=["x", "y"])
st.header("Choose a datapoint color")
color = st.color_picker("Color", "#FF0000")
st.divider()
st.scatter_chart(st.session_state.df, x="x", y="y", color=color)
如果要为所有用户提取相同的数据,则可能会缓存检索该数据的函数。另一方面,如果提取特定于用户的数据(例如查询其个人信息),则可能需要将其保存在会话状态中。这样,查询的数据仅在该会话中可用。
如主要概念中所述,会话状态也与小部件相关。小部件是神奇的,可以自己安静地处理状态。但是,作为一项高级功能,您可以通过为小部件分配键来操作代码中小部件的值。分配给小组件的任何键都将成为与小组件值绑定的会话状态中的键。这可用于操作小部件。了解完 Streamlit 的基础知识后,如果您有兴趣,请查看我们的 Widget 行为指南以深入了解详细信息。
参考
https://docs.streamlit.io/get-started/fundamentals/advanced-concepts#what-is-a-session
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!