【从零开始学习Redis | 第五篇】基于布隆过滤器解决Redis的穿透问题
前言:
? ? ? ? ?在如今的开发中,使用缓存中间件Redis已经成为一项很广泛的技术,Redis的高性能大大优化了我们的服务器性能,缓解了在高并发的情况下服务器的压力。它基于缓存的形式,在内存中保存数据,减少对磁盘的IO操作。然而尽管Redis有着很多的优点,但仍然有三朵乌云漂浮在Redis的上空:穿透,击穿,雪崩。而我们今天就把焦点聚焦于Redis的穿透问题。
目录

什么是Redis的穿透问题:
????????Redis的穿透问题是指当应用程序查询一个不存在于缓存中的数据时,请求会直接穿透到后端存储系统(如数据库),导致缓存无法发挥作用,增加了后端负载并降低了系统性能。
穿透问题通常发生在以下情况下:
- 缓存击穿:某个热门数据在缓存过期后被大量并发请求访问,此时缓存失效,请求会直接访问后端存储系统,导致后端负载过高。
- 恶意攻击:有意发送不存在的数据请求,以触发系统的请求流量,浪费服务器资源。
为了解决Redis的穿透问题,可以采取以下措施:
-
布隆过滤器(Bloom Filter):使用布隆过滤器可以在缓存层面进行快速的数据存在性检查。布隆过滤器是一种概率型的数据结构,可以高效地判断一个元素是否可能存在于集合中,通过在缓存层进行预先判断,可以防止不存在的数据请求直接穿透到后端存储系统。
-
空值缓存:对于后端存储中不存在的数据,可以将其在缓存中设置为空值缓存,即存储一个特殊的空值标识。这样,在下一次查询该数据时,即使缓存中为空值标识,也可以避免请求直接穿透到后端存储系统。
-
互斥锁(Mutex):当缓存失效时,可以使用互斥锁来保护后续的查询操作。在获取到锁之后,再从后端存储系统加载数据到缓存中。其他并发请求会等待锁的释放,避免了多个请求同时穿透到后端存储系统。
-
热点数据预加载:对于热门数据,可以在系统启动时或低峰期通过批量查询或模拟请求将其提前加载到缓存中,避免缓存冷启动时的穿透问题。
-
异步更新缓存:当缓存失效后,可以异步地从后端存储系统加载数据到缓存中,而不是阻塞请求等待数据加载完成。这样可以减少请求的等待时间,提高系统的响应速度。
需要根据具体的业务场景和系统需求选择合适的解决方案,综合考虑性能、复杂度和数据准确性等因素,以确保Redis的穿透问题得到有效解决。
而我们今天就来详细介绍一下布隆过滤器
布隆过滤器:
我们先来简单说一下布隆表达器的思想:
既然 直接访问Redis 可能会存在Redis的穿透问题,那么我们就设置一个容器,这个容器里面记录了Redis中都有哪些数据,而我们以后所有的对于Redis的数据操作,都需要先在这个存储装置中查找我们想要操作的数据是否存在,如果存在,才可以进入Redis进行相关数据操作。
例如这个容器里面说明了Redis中有张三,李四,王五 这三个数据。那么如果我们要查询赵六这个数据,按照以前的思想,就是直接在Redis中查询赵六这个数据。但Redis中并不存在,这就造成了Redis的穿透问题。而为了解决这个问题,我们就使用这个容器,我们先在这个容器中查询是否有赵六这个数据,如果有再查询Redis,如果没有就直接Return false就可以了。
相信通过这么说,大家肯定已经理解了布隆过滤器的思想:布隆过滤器就是一个记录Redis中存在哪些数据的容器
那么现在问题的核心已经变为:我们如何高效的构建这个容器?
因为容器的目的只是为了证明Redis中存在这个数据,如果我们要通过存储这个元素的全部信息来证明Redis中存在这个数据,那简直是太扯淡了。
相信大家自己可以想出很多简化存储数据形式的方法,而我们直接来为大家介绍一下布隆过滤器是怎么构建自己的存储方式的:
整个布隆过滤器,我们可以认为是一个存储0和1的一维数组

而他是怎么通过这些0和1来说明一个元素是否存在于Redis中呢?
布隆过滤器内部有自己的哈希算法,可以对数据进行哈希映射,将其映射为一个一维数组的下标,那么我们就修改这个下标对应的值为1。当我们判断当前数据在Redis中是否存在的时候,我们就使用相同的哈希算法,再次得到一个下标值,检查这个下标对应的位置是否为1。就可以快速判断当前数据是否在Redis中存在了。
例如我们的Redis中有张三这个数据,我们把他存储到布隆过滤器中:

此时如果我们输入一个数据是李四,而Hash(李四)=4,我们一查询这个一维数组,下标为4的位置数值为0,这就说明了Redis中不存在李四这个数据,那么我们就直接返回,避免了Redis的穿透问题。
看到这里,相信有善于思考的同学已经发现了问题:万一两个数据经过Hash函数得到的下标值是一样的呢?
假设Redis中存在数据A,Hash(A)=3,而我们输入的数据B,经过Hash算法之后,也得到了下标3,那么岂不是造成错误了?
其实这种情况是存在的,也就是说随之数据量的增加,布隆过滤器是一定会出现错误判断的情况的。而为了减少这种错误,我们的思维也很简单:我多使用几个Hash函数不就好了?,既然一次得到的下标会重复,我就对一个数据进行多次Hash,把得到的下标所对应的空间都标记为1。在判断数据的时候,我们就进行同样的操作,只有对应的下标空间都为1的时候,才证明该数据在Redis中存在。
例如我们在布隆过滤器中记录张三这个数据的时候,就多进行几次Hash,把得到的下标空间都标记为1。在进行判断数据是否存在的时候,就使用相同Hash函数进行相同次数的操作,判断得到的下标的空间是否为1
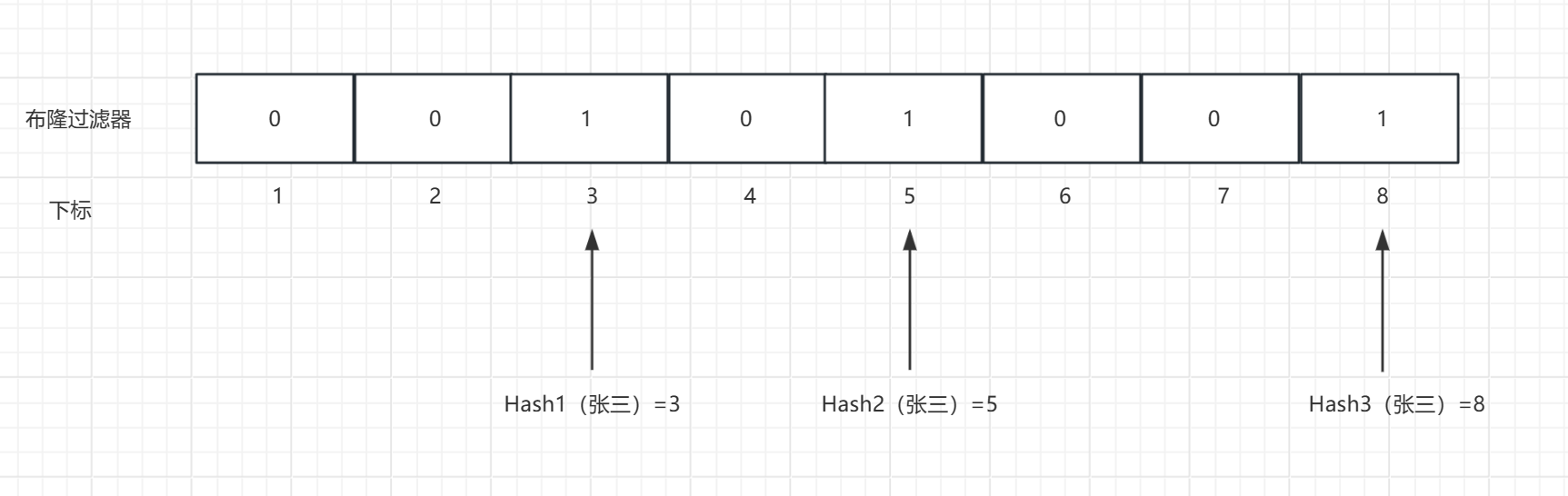
也就是说:布隆过滤器的误判率可以通过哈希函数的数量来进行调整。
而哈希函数越多,所映射出来的下标值就越多,下标值越多,一维数组的长度就越长,布隆过滤器的空间复杂度就越高。
基于Spring Boot实现布隆过滤器:
我们不手动实现布隆过滤器,而是直接使用Google Guava中提供的BloomFilter。
1.导入依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>xxx</version>
</dependency>2.创建并配置布隆过滤器:
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class BloomFilterConfig {
@Bean
public BloomFilter<String> bloomFilter() {
int expectedInsertions = 1000; // 期望的插入数量
double fpp = 0.01; // 期望的误判率
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.unencodedCharsFunnel(), expectedInsertions, fpp);
return bloomFilter;
}
}3.使用布隆过滤器:
import com.google.common.hash.BloomFilter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class MyService {
@Autowired
private BloomFilter<String> bloomFilter;
public boolean isElementExists(String element) {
return bloomFilter.mightContain(element);
}
public void addElement(String element) {
bloomFilter.put(element);
}
}?在这里我们再贴一下我自己的一个练手项目的使用:
跟上述的代码其实都差不多,主要在Service层中多添加一个方法,用于把Redis中的所有KEY 都放到布隆过滤器中: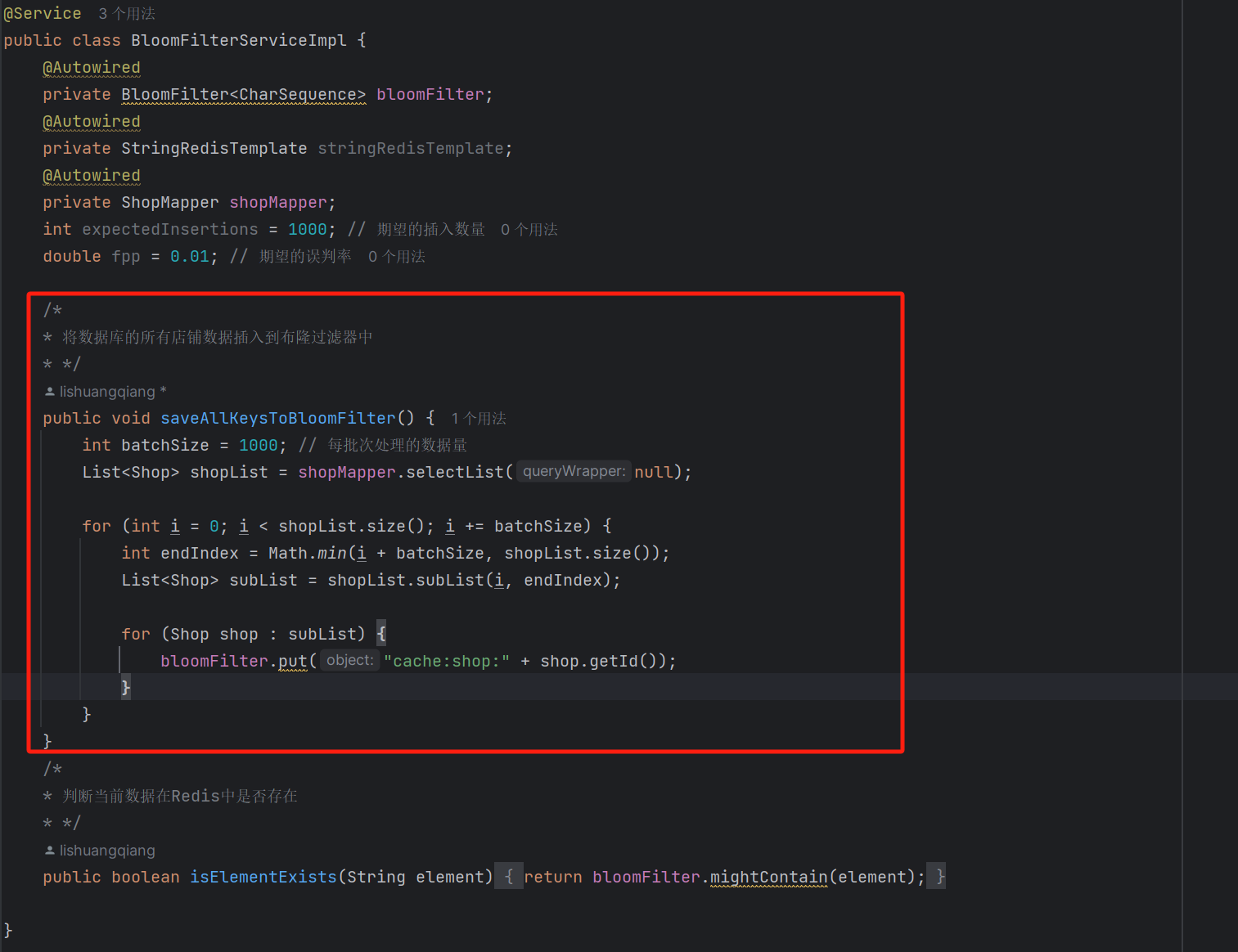 然后要设置在启动之后自动执行这个注入:
然后要设置在启动之后自动执行这个注入:

之后就可以在使用到Redis的方法中使用这个server层类:
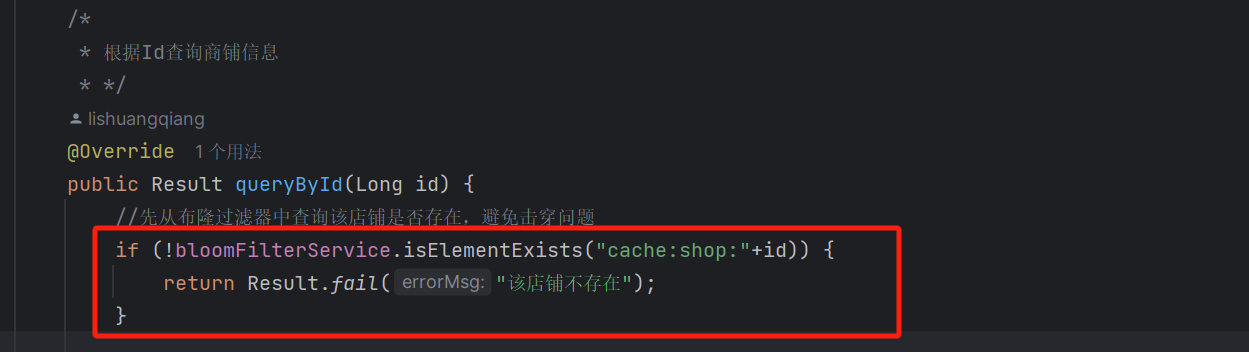
这样,我们就在这个项目中实现了基于布隆过滤器来缓解Redis的穿透问题。
所以其实我们可以看到,布隆过滤器的使用难点主要在于:如何在真实业务海量数据的背景下。实现对布隆过滤器的初始化,因为我们要直接从数据库中拿数据,这种大规模的IO操作势必会给服务器来带很大的压力
而我由于能力限制,想不出太多的方法,也无法真实模拟海量数据背景,所以在这方面有所欠缺。
而我能够想出的方法有:
1.创建定时任务,分批存储数据到布隆过滤器中。
2.创建多个布隆切片,分批处理数据。
不知道在实际业务开发中,我们是怎么使用布隆过滤器的,如果有知道的大佬还请赐教。
总结:
布隆过滤器是一种高效的概率型数据结构,用于快速判断一个元素是否可能存在于一个集合中。通过位数组和多个哈希函数的组合,布隆过滤器可以实现高效的元素插入和查询操作,并且占用较少的内存空间。
总的来说,布隆过滤器具有以下几个关键优点:
- 高效的插入和查询性能:布隆过滤器的时间复杂度都是O(k),其中k为哈希函数的数量。这使得它能够在常数时间内快速地判断一个元素是否可能存在于集合中,对于大规模数据集的重复查询非常有效。
- 节省内存空间:布隆过滤器只需要存储每个元素的哈希值对应的位数组位置信息,而不需要存储元素本身。相比于其他数据结构,它能够节省大量的内存空间,尤其适用于处理大规模数据集。
- 可调控的误判率:通过调整哈希函数的数量和位数组的大小,可以控制布隆过滤器的误判率。根据实际需求和应用场景,可以选择合适的参数配置,以达到平衡误判率和内存消耗的目标。
然而,布隆过滤器也有一些缺点需要注意:
- 存在一定的误判率:由于哈希函数的计算结果有可能冲突,布隆过滤器会出现一定程度的误判。这意味着在判断一个元素存在时,可能会出现一定的虚警情况,需要进行进一步的确认。
- 无法删除元素:由于布隆过滤器的位数组中的位只能置为1而不能置为0,所以无法从布隆过滤器中删除已插入的元素。如果需要删除元素的功能,布隆过滤器可能不适用。
综上所述,布隆过滤器是一种高效、节省内存的数据结构,通过牺牲一定的精确性来提高查询效率。它在多个领域应用广泛,特别适用于大规模数据集的查询和去重场景。在使用布隆过滤器时,需要根据实际需求选择合适的参数配置,并注意误判率和删除元素的限制。
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!