扩散模型参数量降低87%,且提升生成质量;通过蒸馏实现一步采样扩散模型;VideoCrafter2视频生成;深度感知图像合成
本文首发于公众号:机器感知
扩散模型参数量降低87%,且提升生成质量;通过蒸馏实现一步采样扩散模型;VideoCrafter2视频生成;深度感知图像合成
One-Step Diffusion Distillation via Deep Equilibrium Models
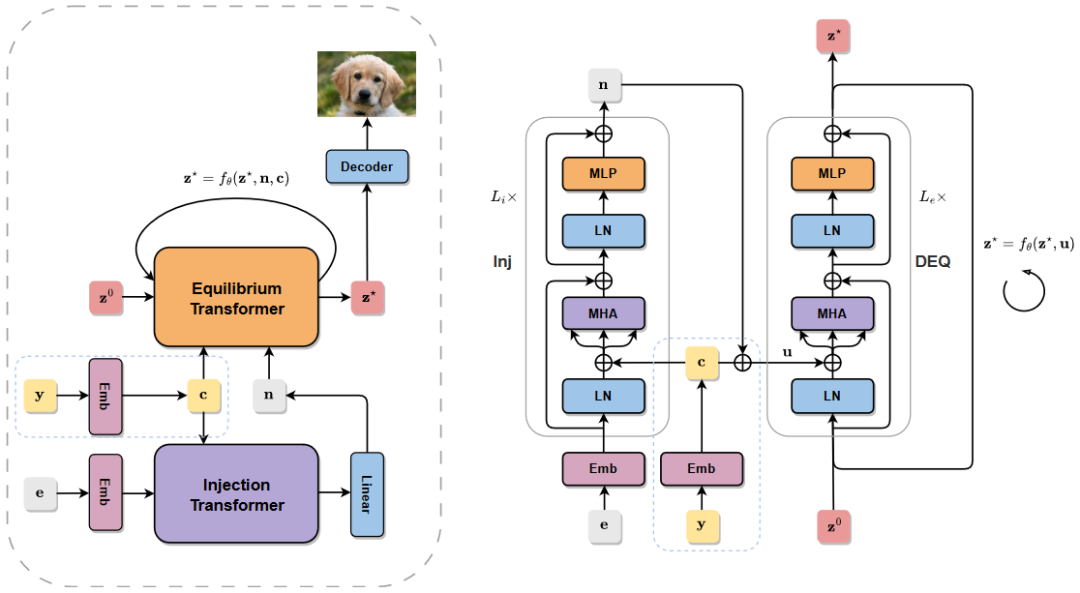
Diffusion models excel at producing high-quality samples but naively require hundreds of iterations, prompting multiple attempts to distill the generation process into a faster network. However, many existing approaches suffer from a variety of challenges: the process for distillation training can be complex, often requiring multiple training stages, and the resulting models perform poorly when utilized in single-step generative applications. In this paper, we introduce a simple yet effective means of distilling diffusion models directly from initial noise to the resulting image. Of particular importance to our approach is to leverage a new Deep Equilibrium (DEQ) model as the distilled architecture: the Generative Equilibrium Transformer (GET). Our method enables fully offline training with just noise/image pairs from the diffusion model while achieving superior performance compared to existing one-step methods on comparable training budgets.?
SAiD: Speech-driven Blendshape Facial Animation with Diffusion
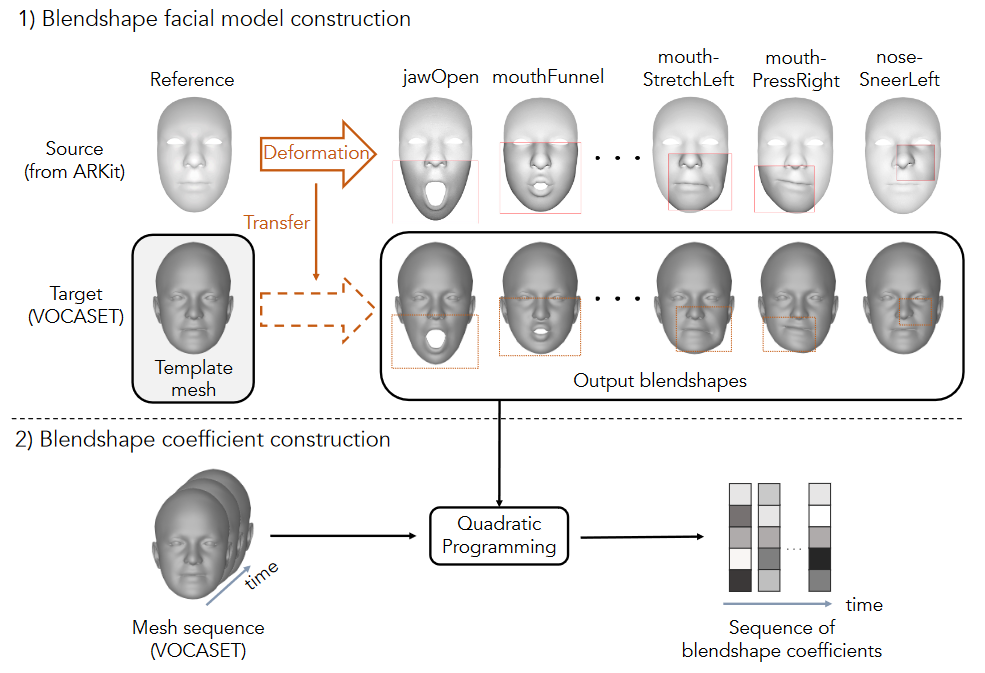
Speech-driven 3D facial animation is challenging due to the scarcity of large-scale visual-audio datasets despite extensive research. Most prior works, typically focused on learning regression models on a small dataset using the method of least squares, encounter difficulties generating diverse lip movements from speech and require substantial effort in refining the generated outputs. To address these issues, we propose a speech-driven 3D facial animation with a diffusion model (SAiD), a lightweight Transformer-based U-Net with a cross-modality alignment bias between audio and visual to enhance lip synchronization. Moreover, we introduce BlendVOCA, a benchmark dataset of pairs of speech audio and parameters of a blendshape facial model, to address the scarcity of public resources.
Fixed Point Diffusion Models

We introduce the Fixed Point Diffusion Model (FPDM), a novel approach to image generation that integrates the concept of fixed point solving into the framework of diffusion-based generative modeling. Our approach embeds an implicit fixed point solving layer into the denoising network of a diffusion model, transforming the diffusion process into a sequence of closely-related fixed point problems. Combined with a new stochastic training method, this approach significantly reduces model size, reduces memory usage, and accelerates training. Moreover, it enables the development of two new techniques to improve sampling efficiency: reallocating computation across timesteps and reusing fixed point solutions between timesteps.?
VideoCrafter2: Overcoming Data Limitations for High-Quality Video Diffusion Models

Text-to-video generation aims to produce a video based on a given prompt. Recently, several commercial video models have been able to generate plausible videos with minimal noise, excellent details, and high aesthetic scores. However, these models rely on large-scale, well-filtered, high-quality videos that are not accessible to the community. Many existing research works, which train models using the low-quality WebVid-10M dataset, struggle to generate high-quality videos because the models are optimized to fit WebVid-10M. In this work, we explore the training scheme of video models extended from Stable Diffusion and investigate the feasibility of leveraging low-quality videos and synthesized high-quality images to obtain a high-quality video model.?
Compose and Conquer: Diffusion-Based 3D Depth Aware Composable Image Synthesis

Addressing the limitations of text as a source of accurate layout representation in text-conditional diffusion models, many works incorporate additional signals to condition certain attributes within a generated image. Although successful, previous works do not account for the specific localization of said attributes extended into the three dimensional plane. In this context, we present a conditional diffusion model that integrates control over three-dimensional object placement with disentangled representations of global stylistic semantics from multiple exemplar images.
Consistent3D: Towards Consistent High-Fidelity Text-to-3D Generation with Deterministic Sampling Prior

Score distillation sampling (SDS) and its variants have greatly boosted the development of text-to-3D generation, but are vulnerable to geometry collapse and poor textures yet. To solve this issue, we first deeply analyze the SDS and find that its distillation sampling process indeed corresponds to the trajectory sampling of a stochastic differential equation (SDE): SDS samples along an SDE trajectory to yield a less noisy sample which then serves as a guidance to optimize a 3D model. However, the randomness in SDE sampling often leads to a diverse and unpredictable sample which is not always less noisy, and thus is not a consistently correct guidance, explaining the vulnerability of SDS.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 我们是如何测试人工智能的(一)基础效果篇
- 产品分类功能阿里巴巴国际站店铺装修首页装修颜色分类产品分类效果代码生成器工具制作编辑器旺铺 首页外贸平台alibaba装修
- 1688平台API接口|阿里1688布局跨境业务,瞄准海外代采
- C/C++ 控制台窗口光标移动位置实现(Linux/Windows)
- Python 错误 Valueerror: Expected 2d Array Got 1d Array Instead
- 思绪记忆:伦敦金是以美元计价的黄金!
- 数据可视化---柱状图
- 招贤令:一起来搞一个新开源项目
- 一键搞定!用Maven命令把本地JAR包装进Maven仓库
- Java解决删除子串后的字符串最小长度