【根据loss曲线看模型微调效果】如何使用loss曲线诊断机器学习模型性能
一、Loss曲线
????在模型的预训练或者微调过程中,我们一般通过观察loss曲线来得出模型对于数据集的学习效果等信息。那么我们如何根据loss曲线得到一些信息呢?
????通常数据集会被划分成三部分,训练集(training dataset)、验证集(validation dataset)、测试集(test dataset)。我们在训练模型时也经常会根据训练集的loss和验证集loss来诊断模型,从而期望能够优化参数训练处一个更好的模型,这个更好指的是能在测试集上表现更好的模型,也就是泛化能力(generalization)强的模型。那怎么根据loss曲线去诊断模型呢?
????首先根据模型的表现我们把它分成三类:
- Underfit(欠拟合)
- Overfit(过拟合)
- Good fit (完美拟合)
????那我们目标肯定是得到一个good-fit模型,但是在训练过程中会出现Underfit和Overfit。那么我们需要做的就是首先根据loss曲线判断模型现在处于哪种拟合情况,然后再进行调整参数。那我们先看看每种拟合的loss曲线是怎样的?
1.Underfit(欠拟合)
Underfit指的是模型不能很好的学习训练集。
????如下图所示,这就是一个Underfit的例子,仅根据training loss就可以判断。这个training loss下降的非常平缓以致于好像都没有下降,这说明模型根本没有从训练集学到什么东西!
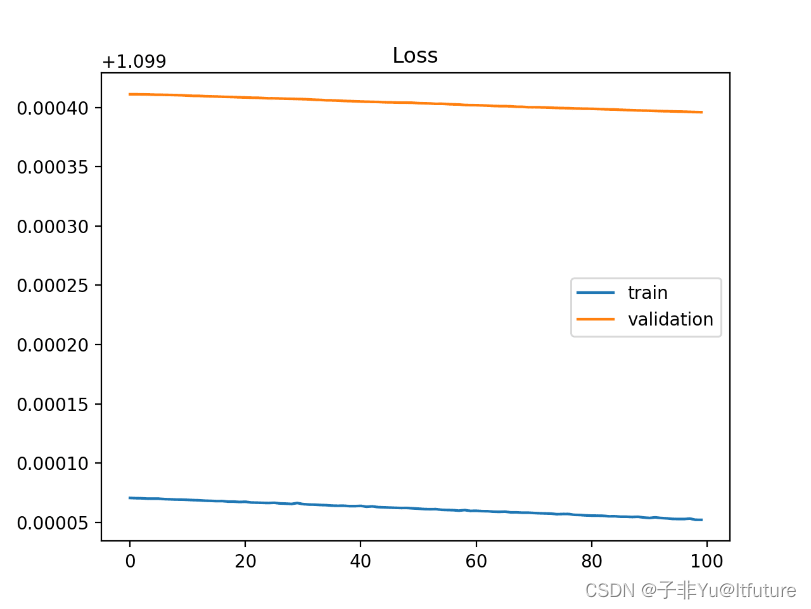
????下图也是Underfit情况,这种情况的特点是在训练结束时候training loss还在继续下降,这说明还有学习空间,模型还没来得及学就结束了。
2.Overfit(过拟合)
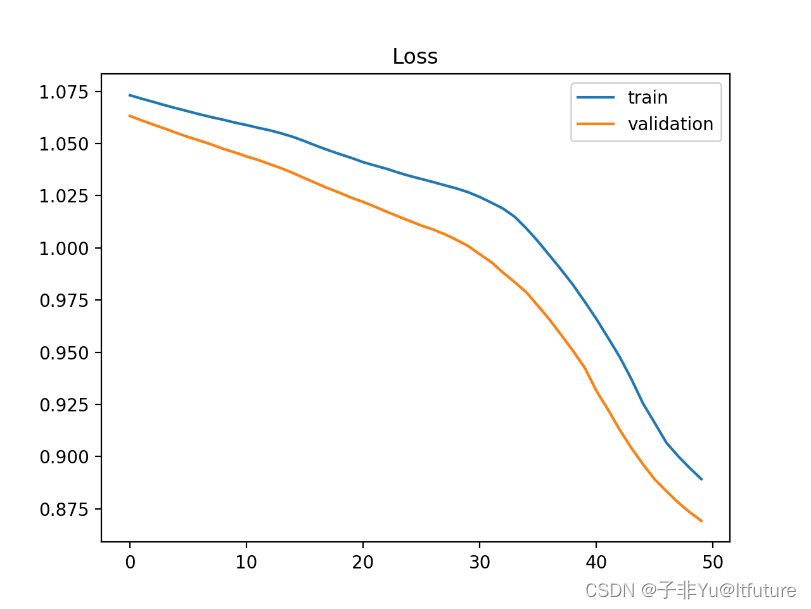
????Overfit指的是模型把训练集学的有点过了,以致于把一些噪音(noise)和随机波动(random fluctuations)也学进来了。就好像抄别人卷子时候把别人的错别字也照抄一样。这也是我们在训练中最经常出现的问题,overfit有时候是因为训练太久造成的。那Overfit的loss曲线长什么样呢?
????如下图所示,overffit时候training loss一直在不断地下降,而validation loss在某个点开始不再下降反而开始上升了,这就说明overfit,我们应该在这个拐点处停止训练。
3.Good fit (完美拟合)
????Good git是我们的目标,它在loss曲线上的特点是training loss和validation loss都已经收敛并且之间相差很小很小。如下图所示,模型在20轮过后,两个loss曲线都开始收敛,而且两者之间并没有肉眼的差距。 通常traing loss会更小,这样他们之间就会有个gap,这个gap叫做generalization gap。
二、不同Loss表现
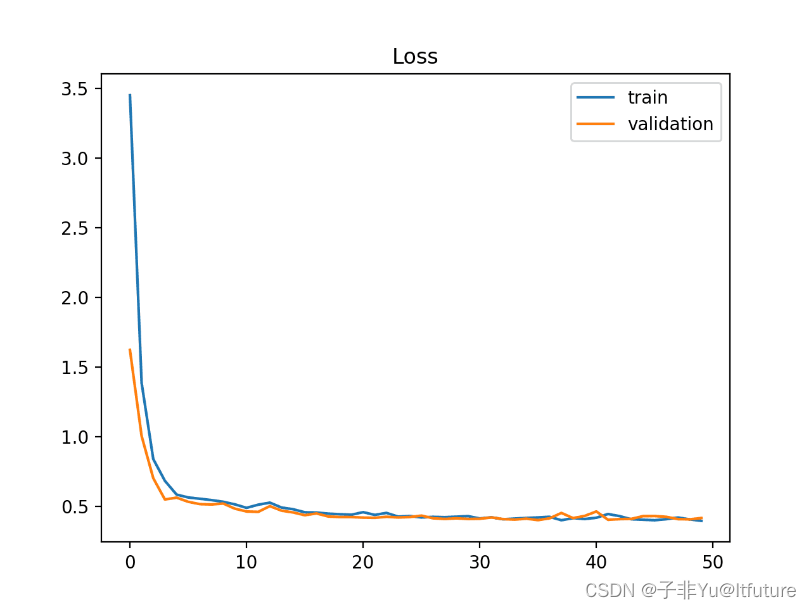
3.1 Underfit
我们使用随机梯度下降(SGD)优化器,学习率为0.01,训练10轮,代码如下
#underfit
epochs = 10
sgd = optimizers.sgd(lr=0.01)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])
然后我们就得到了一个Underfitting模型,如下图所示,在训练结束的时候training loss还在下降,这说明模型还未学习充分。

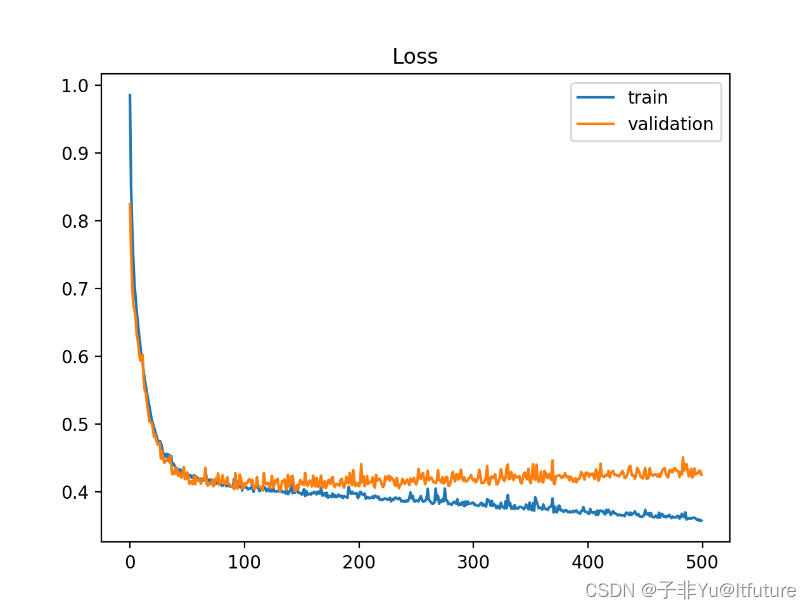
3.2 Overfit
然后我们使用sgd作为优化器时候,训练30轮
#overfit
epochs = 30
sgd = optimizers.sgd(lr=0.01)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])
结果出现了过拟合的情况,loss曲线如下图
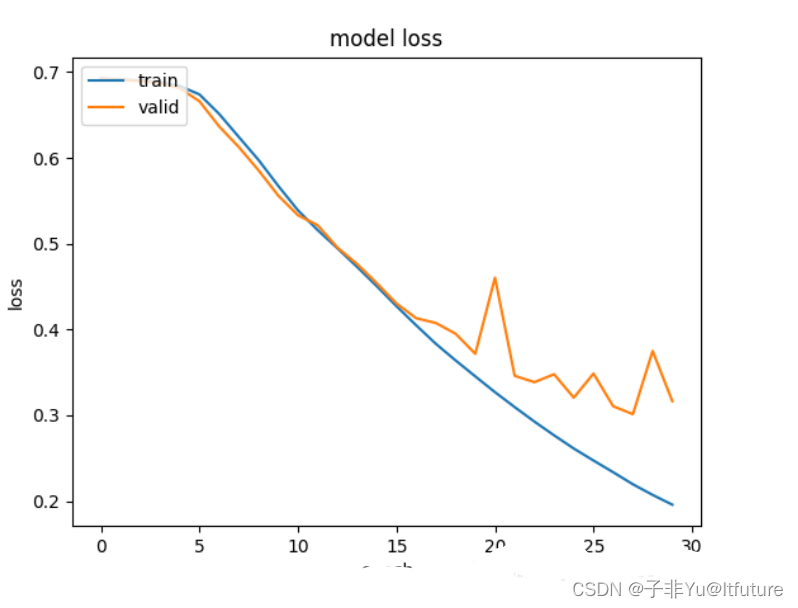
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- CTF-PWN-栈溢出-中级ROP-【栈迁移】
- Socket多进程模型
- elementUI 时间段快捷选择及禁用(包含d2-crud-plus中使用)
- 系列六、MindManager取消首字母自动大写
- C波段数据链和DAA技术实现BVLOS超视距飞行-乔克托族BEYOND计划获得FAA扩大批准
- 长短期记忆(LSTM)神经网络-多输入分类
- 万物简单AIoT物联网平台快速开始
- 【SVN】使用教程
- 设计一个LLMops的端到端业务流程需要哪些存储技术
- SQL-DCL-如何用户管理,如何给用户权限?