助力智能人群检测计数,基于DETR(DEtectionTRansformer)开发构建通用场景下人群检测计数识别系统
在一些人流量比较大的场合,或者是一些特殊时刻、时段、节假日等特殊时期下,密切关注当前系统所承载的人流量是十分必要的,对于超出系统负荷容量的情况做到及时预警对于管理团队来说是保障人员安全的重要手段,本文的主要目的是想要基于通用的数据开发构建用于通用场景下的人群检测计数系统。
前文我们基于比较经典的YOLOv3、YOLOv5、YOLOv6、YOLOv7以及YOLOv8开发实现了检测计数系统,感兴趣的话可以自行移步阅读即可:
《助力智能人群检测计数,基于YOLOv3开发构建通用场景下人群检测计数识别系统》
《助力智能人群检测计数,基于YOLOv4开发构建通用场景下人群检测计数识别系统》?
《助力智能人群检测计数,基于YOLOv5全系列模型【n/s/m/l/x】开发构建通用场景下人群检测计数识别系统》
《助力智能人群检测计数,基于YOLOv6开发构建通用场景下人群检测计数系统》
《助力智能人群检测计数,基于YOLOv8开发构建通用场景下人群检测计数识别系统》?
《助力智能人群检测计数,基于YOLOv7开发构建通用场景下人群检测计数识别系统》
DETR (DEtection TRansformer) 是一种基于Transformer架构的端到端目标检测模型。与传统的基于区域提议的目标检测方法(如Faster R-CNN)不同,DETR采用了全新的思路,将目标检测问题转化为一个序列到序列的问题,通过Transformer模型实现目标检测和目标分类的联合训练。
DETR的工作流程如下:
输入图像通过卷积神经网络(CNN)提取特征图。
特征图作为编码器输入,经过一系列的编码器层得到图像特征的表示。
目标检测问题被建模为一个序列到序列的转换任务,其中编码器的输出作为解码器的输入。
解码器使用自注意力机制(self-attention)对编码器的输出进行处理,以获取目标的位置和类别信息。
最终,DETR通过一个线性层和softmax函数对解码器的输出进行分类,并通过一个线性层预测目标框的坐标。
DETR的优点包括:
端到端训练:DETR模型能够直接从原始图像到目标检测结果进行端到端训练,避免了传统目标检测方法中复杂的区域提议生成和特征对齐的过程,简化了模型的设计和训练流程。
不受固定数量的目标限制:DETR可以处理变长的输入序列,因此不受固定数量目标的限制。这使得DETR能够同时检测图像中的多个目标,并且不需要设置预先确定的目标数量。
全局上下文信息:DETR通过Transformer的自注意力机制,能够捕捉到图像中不同位置的目标之间的关系,提供了更大范围的上下文信息。这有助于提高目标检测的准确性和鲁棒性。
然而,DETR也存在一些缺点:
计算复杂度高:由于DETR采用了Transformer模型,它在处理大尺寸图像时需要大量的计算资源,导致其训练和推理速度相对较慢。
对小目标的检测性能较差:DETR模型在处理小目标时容易出现性能下降的情况。这是因为Transformer模型在处理小尺寸目标时可能会丢失细节信息,导致难以准确地定位和分类小目标。
接下来看下我们自己构建的数据集:


官方项目地址在这里,如下所示:

可以看到目前已经收获了超过1.2w的star量,还是很不错的了。
DETR整体数据流程示意图如下所示:

官方也提供了对应的预训练模型,可以自行使用:
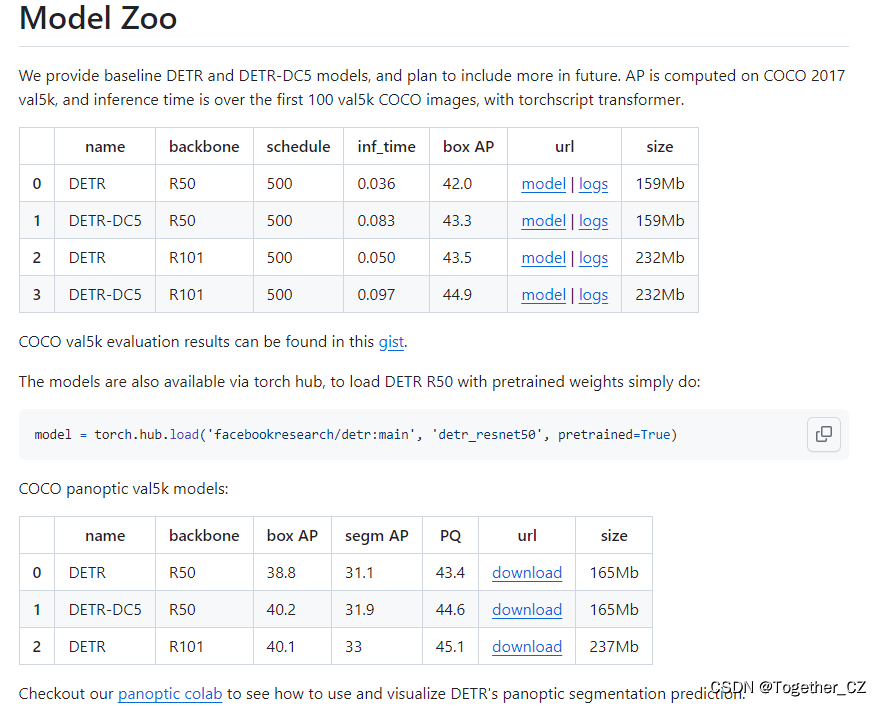
本文选择的预训练官方权重是detr-r50-e632da11.pth,首先需要基于官方的预训练权重开发能够用于自己的 个性化数据集的权重,如下所示:
pretrained_weights = torch.load("./weights/detr-r50-e632da11.pth")
num_class = 1 + 1
pretrained_weights["model"]["class_embed.weight"].resize_(num_class+1,256)
pretrained_weights["model"]["class_embed.bias"].resize_(num_class+1)
torch.save(pretrained_weights,'./weights/detr_r50_%d.pth'%num_class)因为这里我的类别数量为1,所以num_class修改为:1+1,根据自己的实际情况修改即可。生成后如下所示:

终端执行:
python main.py --dataset_file "coco" --coco_path "/0000" --epoch 100 --lr=1e-4 --batch_size=32 --num_workers=0 --output_dir="outputs" --resume="weights/detr_r50_2.pth"
即可启动训练。训练启动如下:

训练完成输出如下:
Accumulating evaluation results...
DONE (t=0.26s).
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.347
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.701
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.296
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.053
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.143
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.478
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.030
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.232
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.463
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.147
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.302
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.590【Precision曲线】
精确率曲线(Precision-Recall Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能。
F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
?

loss可视化如下所示:
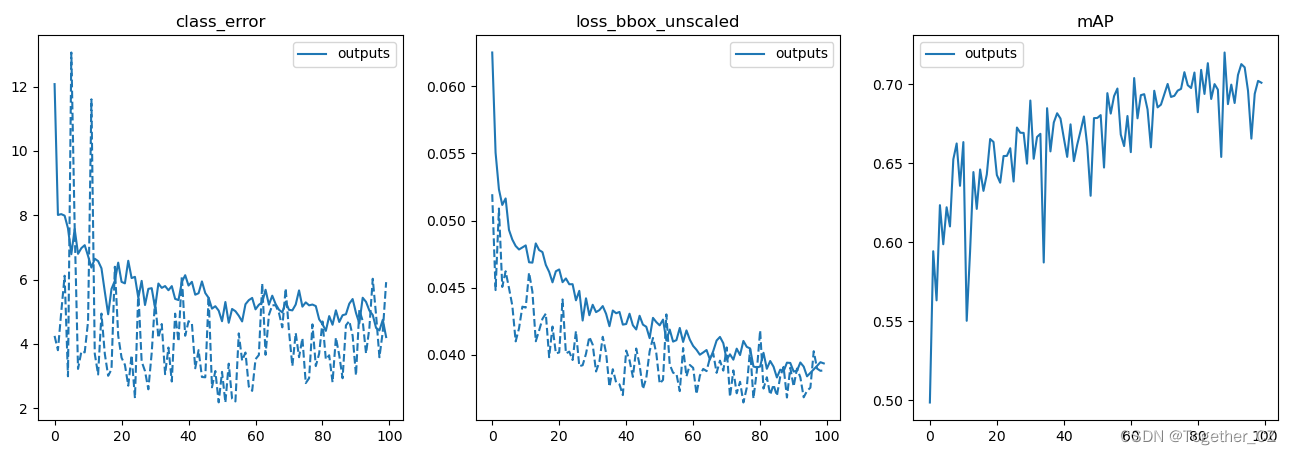
感兴趣的话可以自行动手实践尝试下!
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- react组件注意事项
- 实景无人直播系统:开创智能直播新纪元,实现高效商业营销
- 【开源】基于JAVA语言的企业项目合同信息系统
- 二分算法
- macOS系统下载百度网盘的操作流程
- 代码随想录刷题第三十八天| 理论基础 ● 509. 斐波那契数 ● 70. 爬楼梯 ● 746. 使用最小花费爬楼梯
- 哈希(hash)
- 在 Walrus 上轻松集成 OpenTofu
- 中国电子学会2022年12月份青少年软件编程Scratch图形化等级考试试卷二级真题(含答案)
- 聚观早报 |XREAL Air 2 Ultra发布;一加Ace 3开启销售