Netty RPC 实现(二)
Netty RPC 实现
概念
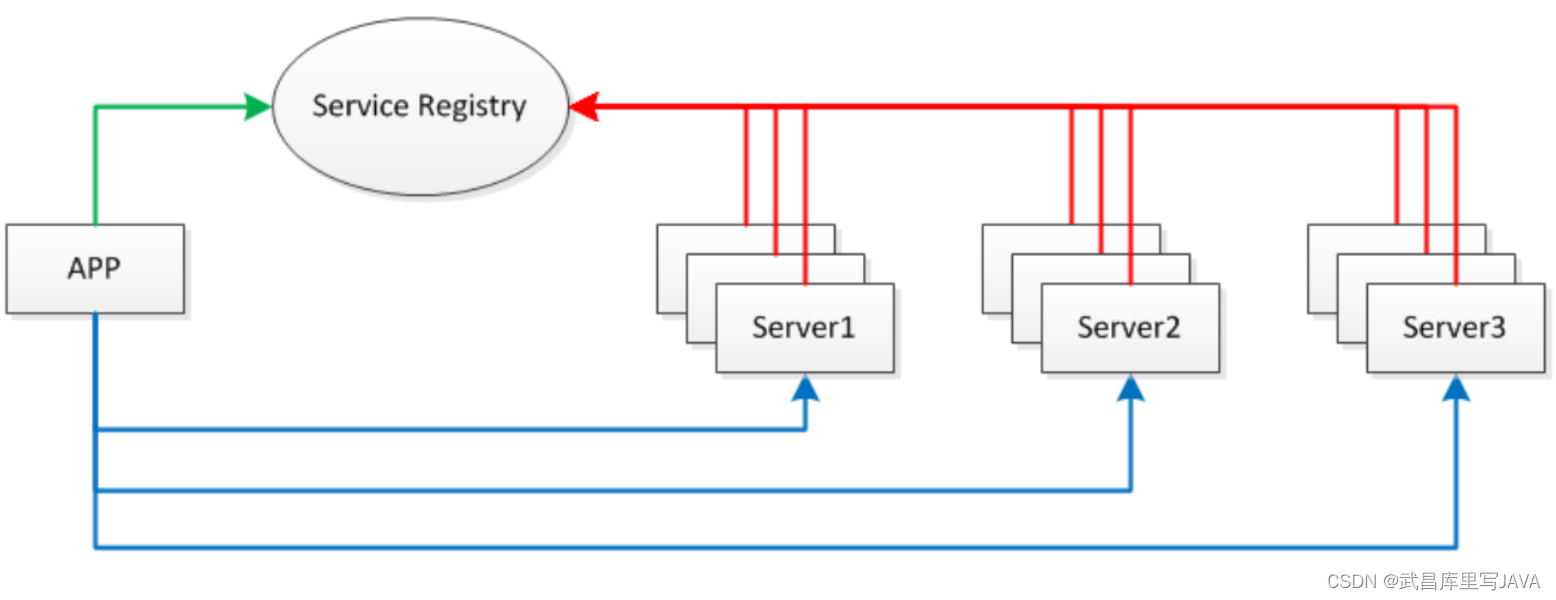
RPC,即 Remote Procedure Call(远程过程调用),调用远程计算机上的服务,就像调用本地服务一样。RPC 可以很好的解耦系统,如 WebService 就是一种基于 Http 协议的 RPC。这个 RPC 整体框架如下:
关键技术
-
服务发布与订阅:服务端使用 Zookeeper 注册服务地址,客户端从 Zookeeper 获取可用的服务地址。
-
通信:使用 Netty 作为通信框架。
-
Spring:使用 Spring 配置服务,加载 Bean,扫描注解。
-
动态代理:客户端使用代理模式透明化服务调用。
-
消息编解码:使用 Protostuff 序列化和反序列化消息。
核心流程
-
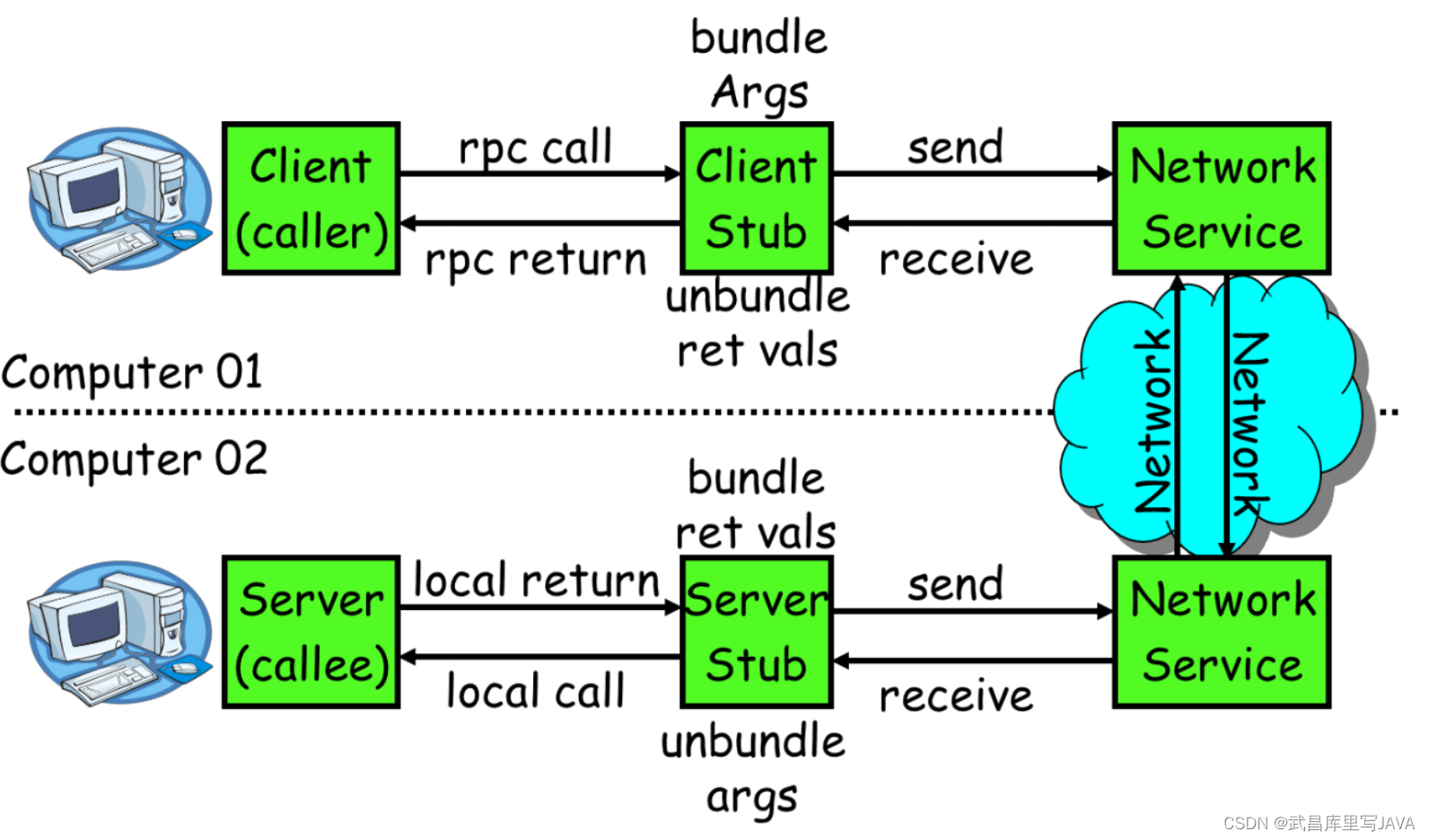
服务消费方(client)调用以本地调用方式调用服务;
-
client stub 接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
-
client stub 找到服务地址,并将消息发送到服务端;
-
server stub 收到消息后进行解码;
-
server stub 根据解码结果调用本地的服务;
-
本地服务执行并将结果返回给 server stub;
-
server stub 将返回结果打包成消息并发送至消费方;
-
client stub 接收到消息,并进行解码;
-
服务消费方得到最终结果。
RPC 的目标就是要 2~8 这些步骤都封装起来,让用户对这些细节透明。JAVA 一般使用动态代理方式实现远程调用。
消息编解码
息数据结构(接口名称+方法名+参数类型和参数值+超时时间+ requestID)
客户端的请求消息结构一般需要包括以下内容:
-
接口名称:在我们的例子里接口名是“HelloWorldService”,如果不传,服务端就不知道调用哪个接口了;
-
方法名:一个接口内可能有很多方法,如果不传方法名服务端也就不知道调用哪个方法;
-
参数类型和参数值:参数类型有很多,比如有 bool、int、long、double、string、map、list,甚至如 struct(class);以及相应的参数值;
-
超时时间:
-
requestID,标识唯一请求 id,在下面一节会详细描述 requestID 的用处。
-
服务端返回的消息 : 一般包括以下内容。返回值+状态 code+requestID
序列化
目前互联网公司广泛使用 Protobuf、Thrift、Avro 等成熟的序列化解决方案来搭建 RPC 框架,这些都是久经考验的解决方案。
通讯过程
核心问题(线程暂停、消息乱序)
如果使用 netty 的话,一般会用 channel.writeAndFlush()方法来发送消息二进制串,这个方法调用后对于整个远程调用(从发出请求到接收到结果)来说是一个异步的,即对于当前线程来说,将请求发送出来后,线程就可以往后执行了,至于服务端的结果,是服务端处理完成后,再以消息的形式发送给客户端的。于是这里出现以下两个问题:
- 怎么让当前线程“暂停”,等结果回来后,再向后执行?
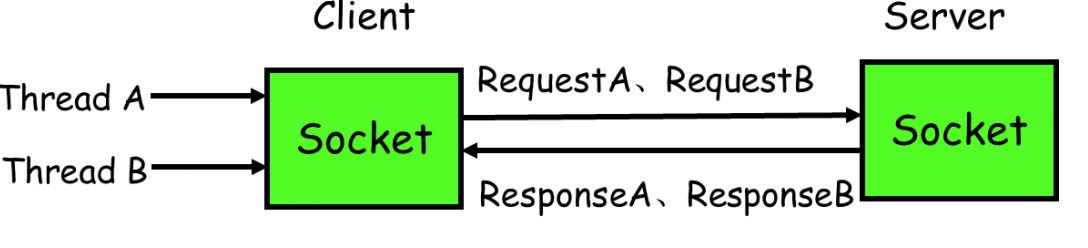
- 如果有多个线程同时进行远程方法调用,这时建立在 client server 之间的 socket 连接上会有很多双方发送的消息传递,前后顺序也可能是随机的,server 处理完结果后,将结果消息发送给 client,client 收到很多消息,怎么知道哪个消息结果是原先哪个线程调用的?如下图所示,线程 A 和线程 B 同时向 client socket 发送请求 requestA 和 requestB,socket 先后将 requestB 和 requestA 发送至 server,而 server 可能将 responseB 先返回,尽管 requestB 请求到达时间更晚。我们需要一种机制保证 responseA 丢给ThreadA,responseB 丢给 ThreadB。
通讯流程
requestID 生成-AtomicLong
- client 线程每次通过 socket 调用一次远程接口前,生成一个唯一的 ID,即 requestID(requestID 必需保证在一个 Socket 连接里面是唯一的),一般常常使用 AtomicLong从 0 开始累计数字生成唯一 ID;
存放回调对象 callback 到全局 ConcurrentHashMap
- 将处理结果的回调对象 callback ,存放到全局 ConcurrentHashMap 里 面put(requestID, callback);
synchronized 获取回调对象 callback 的锁并自旋 wait
- 当线程调用 channel.writeAndFlush()发送消息后,紧接着执行 callback 的 get()方法试图获取远程返回的结果。在 get()内部,则使用 synchronized 获取回调对象 callback 的锁,再先检测是否已经获取到结果,如果没有,然后调用 callback 的 wait()方法,释放
callback 上的锁,让当前线程处于等待状态。
监听消息的线程收到消息,找到 callback 上的锁并唤醒
- 服务端接收到请求并处理后,将 response 结果(此结果中包含了前面的 requestID)发送给客户端,客户端 socket 连接上专门监听消息的线程收到消息,分析结果,取到requestID ,再从前面的 ConcurrentHashMap 里 面 get(requestID) ,从而找到callback 对象,再用 synchronized 获取 callback 上的锁,将方法调用结果设置到callback 对象里,再调用 callback.notifyAll()唤醒前面处于等待状态的线程。
public Object get() {
synchronized (this) { // 旋锁
while (true) { // 是否有结果了
If (!isDone){
wait(); //没结果释放锁,让当前线程处于等待状态
}else{//获取数据并处理
}
}
}
}
private void setDone(Response res) {
this.res = res;
isDone = true;
synchronized (this) { //获取锁,因为前面 wait()已经释放了 callback 的锁了
notifyAll(); // 唤醒处于等待的线程
}
}
RMI 实现方式
Java 远程方法调用,即 Java RMI(Java Remote Method Invocation)是 Java 编程语言里,一种用于实现远程过程调用的应用程序编程接口。它使客户机上运行的程序可以调用远程服务器上的对象。远程方法调用特性使 Java 编程人员能够在网络环境中分布操作。RMI 全部的宗旨就是尽可能简化远程接口对象的使用。
实现步骤
-
编写远程服务接口,该接口必须继承 java.rmi.Remote 接口,方法必须抛出java.rmi.RemoteException 异常;
-
编写远程接口实现类,该实现类必须继承 java.rmi.server.UnicastRemoteObject 类;
-
运行 RMI 编译器(rmic),创建客户端 stub 类和服务端 skeleton 类;
-
启动一个 RMI 注册表,以便驻留这些服务;
-
在 RMI 注册表中注册服务;
-
客户端查找远程对象,并调用远程方法;
1:创建远程接口,继承 java.rmi.Remote 接口
public interface GreetService extends java.rmi.Remote {
String sayHello(String name) throws RemoteException;
}
2:实现远程接口,继承 java.rmi.server.UnicastRemoteObject 类
public class GreetServiceImpl extends java.rmi.server.UnicastRemoteObject implements GreetService {
private static final long serialVersionUID = 3434060152387200042L;
public GreetServiceImpl() throws RemoteException {
super();
}
@Override
public String sayHello(String name) throws RemoteException {
return "Hello " + name;
}
}
3:生成 Stub 和 Skeleton;
4:执行 rmiregistry 命令注册服务
5:启动服务
LocateRegistry.createRegistry(1098);
Naming.bind("rmi://10.108.1.138:1098/GreetService", new GreetServiceImpl());
6.客户端调用
GreetService greetService = (GreetService)
Naming.lookup("rmi://10.108.1.138:1098/GreetService");
System.out.println(greetService.sayHello("Jobs"));
Protoclol Buffer
protocol buffer 是 google 的一个开源项目,它是用于结构化数据串行化的灵活、高效、自动的方法,例如 XML,不过它比 xml 更小、更快、也更简单。你可以定义自己的数据结构,然后使用代码生成器生成的代码来读写这个数据结构。你甚至可以在无需重新部署程序的情况下更新数据结构。
特点
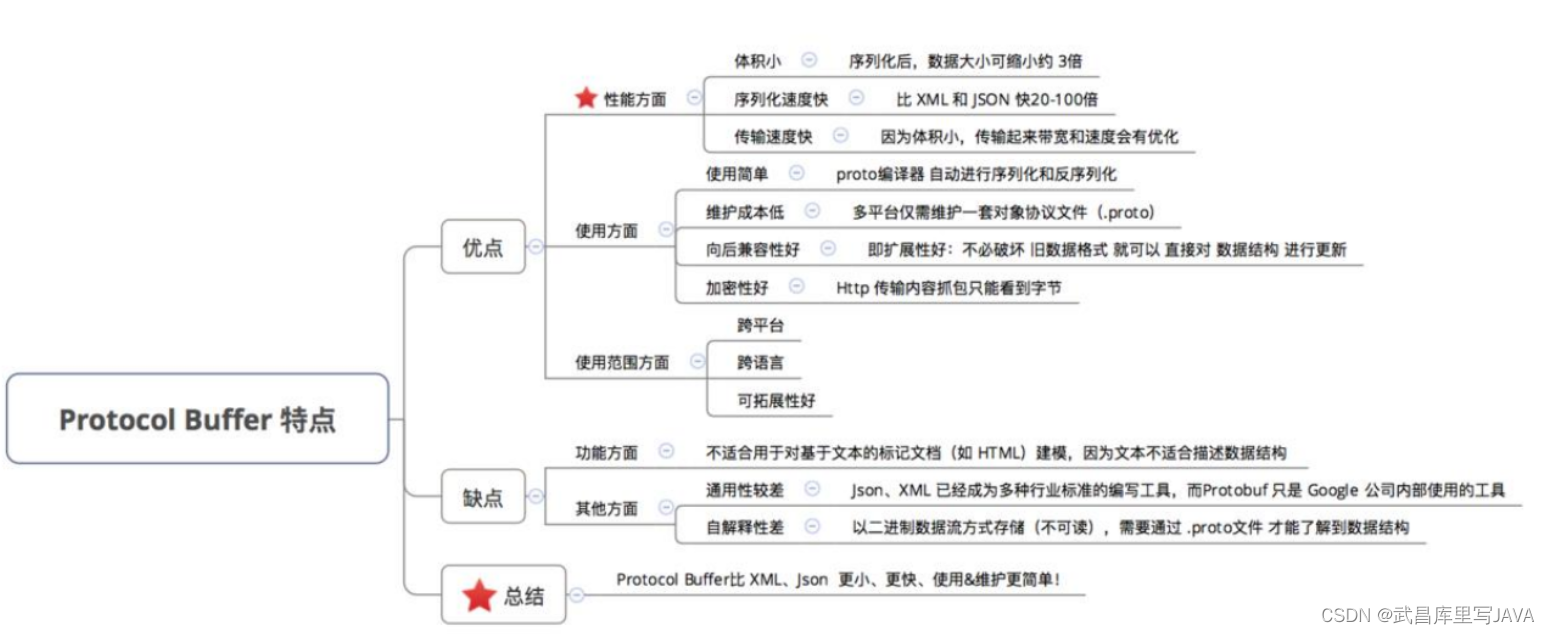
Protocol Buffer 的序列化 & 反序列化简单 & 速度快的原因是:
- 编码 / 解码 方式简单(只需要简单的数学运算 = 位移等等)
- 采用 Protocol Buffer 自身的框架代码 和 编译器 共同完成
Protocol Buffer 的数据压缩效果好(即序列化后的数据量体积小)的原因是:
- a. 采用了独特的编码方式,如 Varint、Zigzag 编码方式等等
- b. 采用 T - L - V 的数据存储方式:减少了分隔符的使用 & 数据存储得紧凑
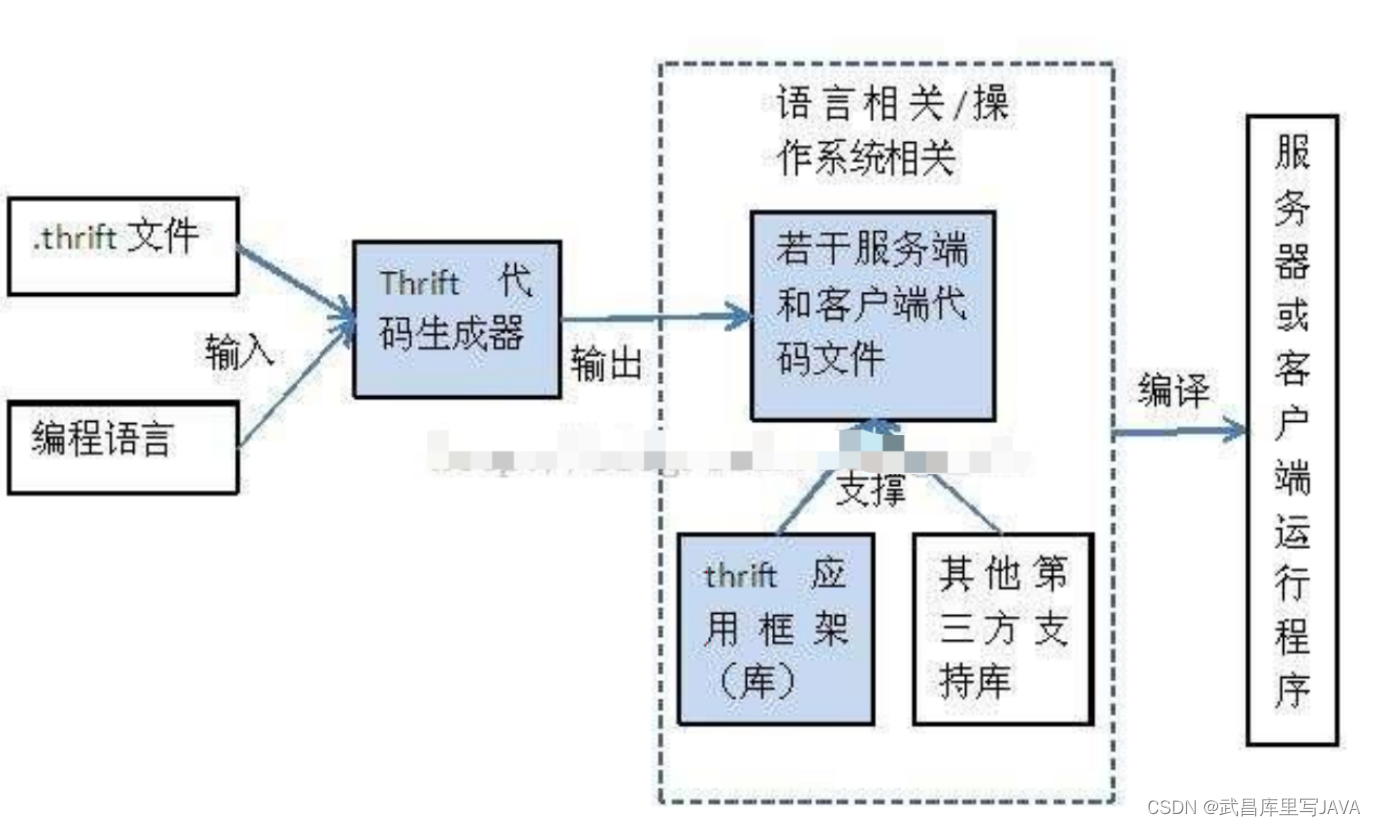
Thrift
Apache Thrift 是 Facebook 实现的一种高效的、支持多种编程语言的远程服务调用的框架。本文将从Java 开发人员角度详细介绍 Apache Thrift 的架构、开发和部署,并且针对不同的传输协议和服务类型给出相应的 Java 实例,同时详细介绍 Thrift 异步客户端的实现,最后提出使用 Thrift 需要注意的事项。
目前流行的服务调用方式有很多种,例如基于 SOAP 消息格式的 Web Service,基于 JSON 消息格式的 RESTful 服务等。其中所用到的数据传输方式包括 XML,JSON 等,然而 XML 相对体积太大,传输效率低,JSON 体积较小,新颖,但还不够完善。本文将介绍由 Facebook 开发的远程服务调用框架Apache Thrift,它采用接口描述语言定义并创建服务,支持可扩展的跨语言服务开发,所包含的代码生成引擎可以在多种语言中,如 C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, Smalltalk 等创建高效的、无缝的服务,其传输数据采用二进制格式,相对 XML 和 JSON 体积更小,对于高并发、大数据量和多语言的环境更有优势。本文将详细介绍 Thrift 的使用,并且提供丰富的实例代码加以解释说明,帮助使用者快速构建服务。
为什么要 Thrift:
1、多语言开发的需要 2、性能问题
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 文心一言 VS 讯飞星火 VS chatgpt (161)-- 算法导论13.1 1题
- 学习-面试java基础-(集合)
- ssm/php/node/python中药城药材销售管理系统
- leetcode:三数之和---双指针
- idea个人常用快捷键汇总
- 开源C语言库Melon:多线程治理
- 选型必备!9款日志采集和管理工具对比!
- 根据屏幕尺寸设置html根字号fontSize大小并刷新
- Gdevops北京站 2023年全球敏捷运维峰会:核心内容与学习收获(附大会核心PPT下载)
- 08-JVM调优实战及常量池详解