算法的时间复杂度
????????在计算机科学中,算法的时间复杂度(time complexity)是一个函数,它定性描述该算法的运行时间。这是一个代表算法输入值的字符串的长度的函数。(这段话不必急于理解,往下看)
????????时间复杂度常用大O符号表述,不包括这个函数的低阶项和首项系数。使用这种方式时,时间复杂度可被称为是渐近的,亦即考察输入值大小趋近无穷时的情况。例如,如果一个算法对于任何大小为?n?的输入,它至多需要?5n^3?+ 3n?的时间运行完毕,那么它的渐近时间复杂度是 O(n^3)。
? ? ? ? 说明:首项系数为:5,低阶项为:3n,因此它的时间复杂度就是O(n^3)。大O时间复杂度并不具体表示代码真正的执行时间,而是表示代码执行时间随数据规模增长的变化趋势,所以,也叫作渐进时间复杂度,简称时间复杂度。
? ? ? ? 常见的时间复杂度分类有很多,咱们由易到难,逐步分析:
一、常数时间复杂度
????????常数时间复杂度 O(1) 意味着算法的执行时间是常量,不随输入规模的增加而增加。以下是一些常见的具有常数时间复杂度的例子:
? ? ? ? 1、数组和哈希表的访问:
- 直接访问数组元素或者从哈希表中查找一个元素的时间都是常数。例如,通过索引访问数组元素
arr[5]或者通过键查找哈希表中的元素hashTable['key']。
const array = [1, 2, 3, 4, 5];
const element = array[2]; // O(1)
const hashMap = { 'a': 1, 'b': 2, 'c': 3 };
const value = hashMap['b']; // O(1)
????????2、固定大小的循环:
- 循环的执行次数不受输入规模的影响。例如,一个执行固定次数的 for 循环。
const n = 10;
// 与n无关
for (let i = 0; i < 5; i++) {
console.log(i); // O(1)
}
????????3、简单的数学运算:
- 像加法、减法、乘法、除法等基本数学运算都是常数时间复杂度。
const result = 2 + 3; // O(1)
二、二次方时间复杂度
????????冒泡排序是一种简单的排序算法,其时间复杂度为 O(n^2)。让我们通过冒泡排序的实现来说明它的二次时间复杂度。
????????冒泡排序的基本思想是多次遍历待排序的序列,每次遍历都比较相邻的两个元素,如果它们的顺序不符合要求就交换它们。这样,经过一轮的遍历,最大的元素就会"冒泡"到序列的末尾。重复这个过程,直到整个序列有序。
以下是冒泡排序的 JavaScript 实现:
function bubbleSort(arr) {
const n = arr.length;
for (let i = 0; i < n - 1; i++) {
for (let j = 0; j < n - 1 - i; j++) {
// 比较相邻的两个元素
if (arr[j] > arr[j + 1]) {
// 交换它们的位置
const temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
return arr;
}
// 示例
const unsortedArray = [64, 34, 25, 12, 22, 11, 90];
const sortedArray = bubbleSort(unsortedArray);
console.log(sortedArray);
在冒泡排序中,外层循环控制需要进行多少轮遍历,而内层循环负责实际的比较和交换操作。因为每一轮内层循环都会对序列中的元素进行比较和可能的交换,所以总的操作次数(即交换次数)是 n * (n-1) / 2,其中 n 是序列的长度。
? ? ? ? 解释:总的比较和交换次数可以表示为:(n?1)+(n?2)+…+1
????????这是一个等差数列的和,可以使用等差数列求和公式来计算。
这样的二次时间复杂度 O(n^2) 。意味着,随着输入规模的增加,算法的执行时间将按平方级别增长。因此,冒泡排序在大规模数据集上可能不够高效。
进阶1:
? ? ? ? 思考:最优时间复杂度?最差时间复杂度?
- 最优时间复杂度:O(n),当输入数据已经是正序排列时,冒泡排序只需要进行一次扫描,就能确定所有元素已经有序。
- 最差时间复杂度:O(n^2),当输入数据是逆序排列时,冒泡排序需要进行最大次数的比较和交换。
进阶2:
? ? ? ? 思考:冒泡排序能否进一步优化?
-
提前结束: 如果在一轮冒泡过程中没有发生元素交换,说明数组已经有序,可以提前结束排序。
-
记录最后交换位置: 在一轮冒泡中,最后发生交换的位置之后的元素已经有序,下一轮无需再考虑这些元素。
function bubbleSort(arr) {
const n = arr.length;
for (let i = 0; i < n - 1; i++) {
// 标志位,用于记录是否发生交换
let swapped = false;
for (let j = 0; j < n - 1 - i; j++) {
// 比较相邻的两个元素
if (arr[j] > arr[j + 1]) {
// 交换它们的位置
const temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
// 设置标志位为true
swapped = true;
}
}
// 如果一轮冒泡中没有发生交换,说明数组已经有序,提前结束
if (!swapped) {
break;
}
}
return arr;
}
这种优化在某些情况下可以显著提高性能,特别是对于部分有序的数组。
思考3:
????????时间复杂度为什么不包含函数的低阶项和首项系数?
????????时间复杂度的目的是描述算法的增长趋势,而不是精确测量运行时间。省略低阶项和首项系数是为了更好地抽象出算法的主要增长趋势,使得我们可以更好地比较不同算法的性能。
????????考虑一个算法的时间复杂度表示为O(an^2 + bn + c),其中 a、b、c 都是常数。在这个表示中,an^2 是主要的增长项,而bn和c是低阶项。当我们关注算法的增长趋势时,我们更关心的是随着输入规模n的增加,主要增长项对运行时间的影响。因此,我们将注意力集中在主要项上,而省略掉低阶项和常数系数。
????????这种抽象的好处在于,它让我们能够更通用地评估算法,而不受具体实现中的一些细节影响。不同机器上运行相同算法的实际运行时间可能会有很大差异,因此时间复杂度提供了一个更抽象、更一般的度量方式。
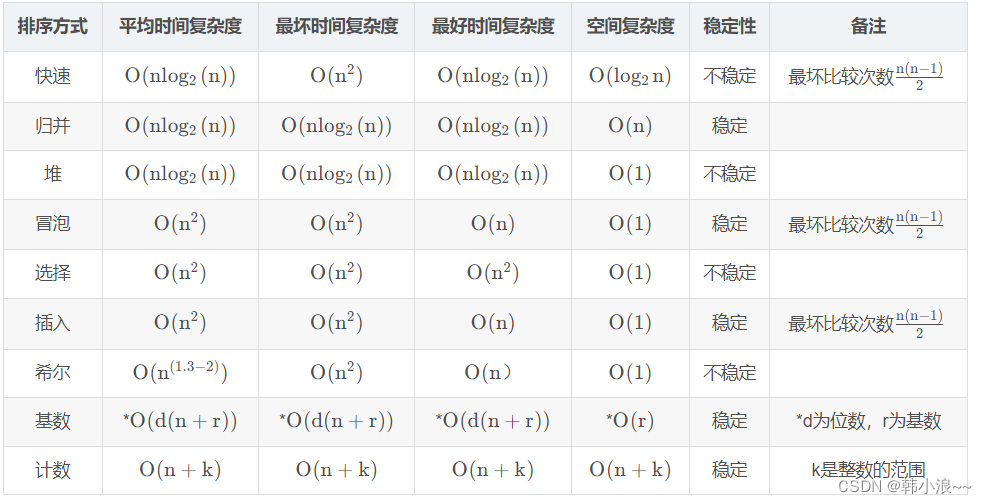
三、其他排序算法
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!