快速排序(三)——hoare法

目录
 一.前言
一.前言
本文给大家带来的是快速排序,快速排序是一种很强大的排序方法,相信大家在学习完后一定会有所收获。
码字不易,希望大家多多支持我呀!(三连+关注,你是我滴神!)
二.快速排序
快速排序是Hoare与1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素排序中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
?
?
上述为快速排序递归实现的主框架,发现于二叉树前序遍历规则非常像,同学们在写递归框架时可想想二叉树前序遍历规则即可快速写出来,后序只需分析如何按照基准值来对区间中数据进行划分的方式即可。?
?
今天我们来学习的是第一种版本:
hoare排法?
下面是动态图例:?
 ?
?
开始解析:?
?
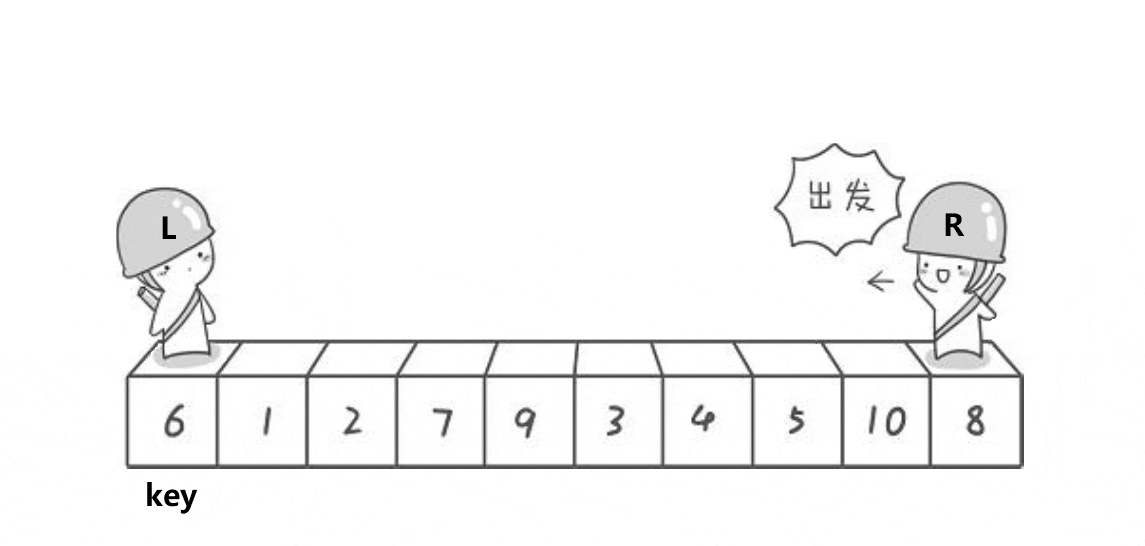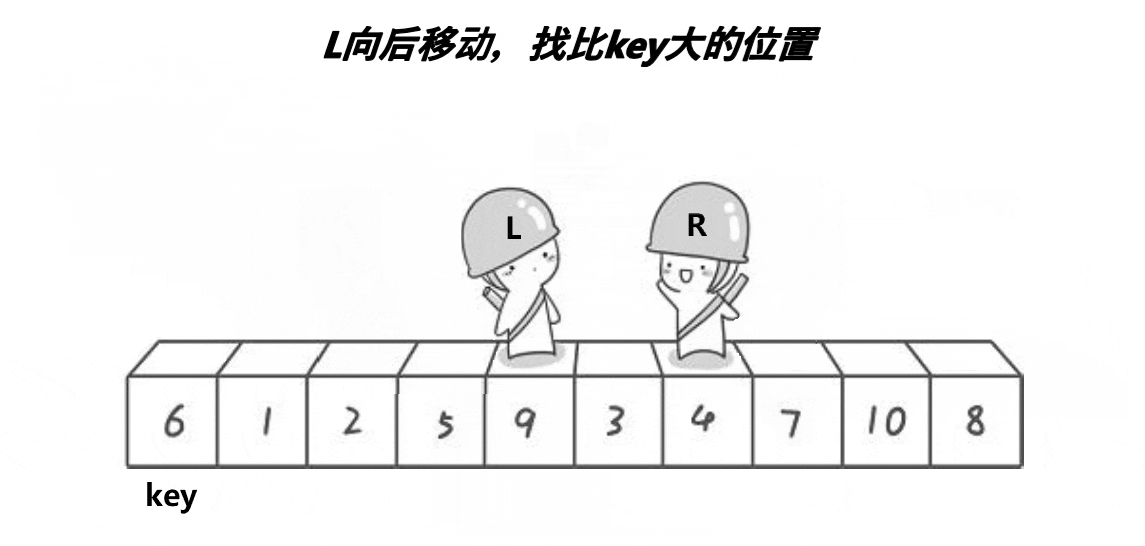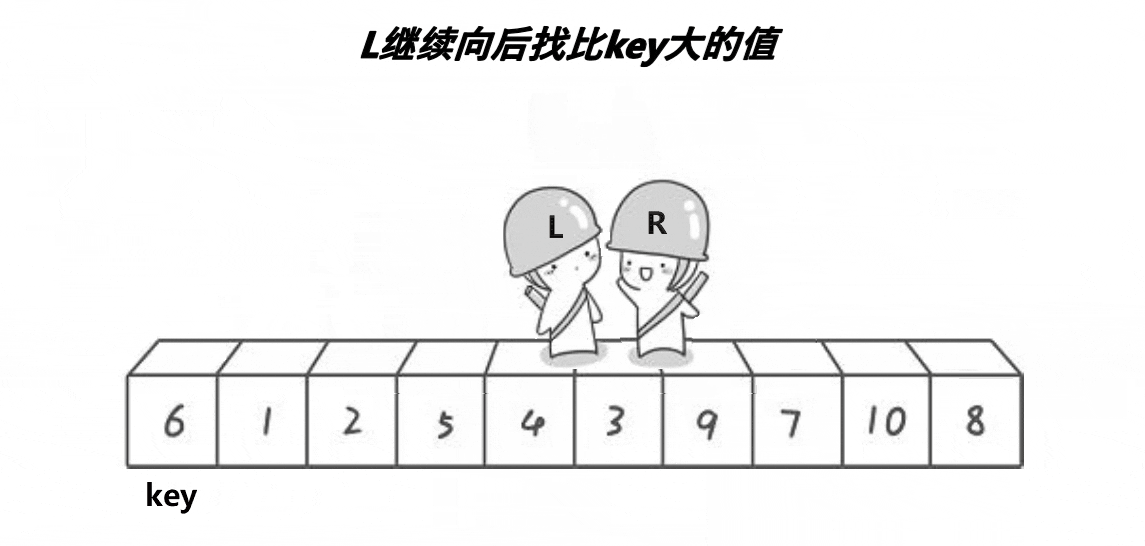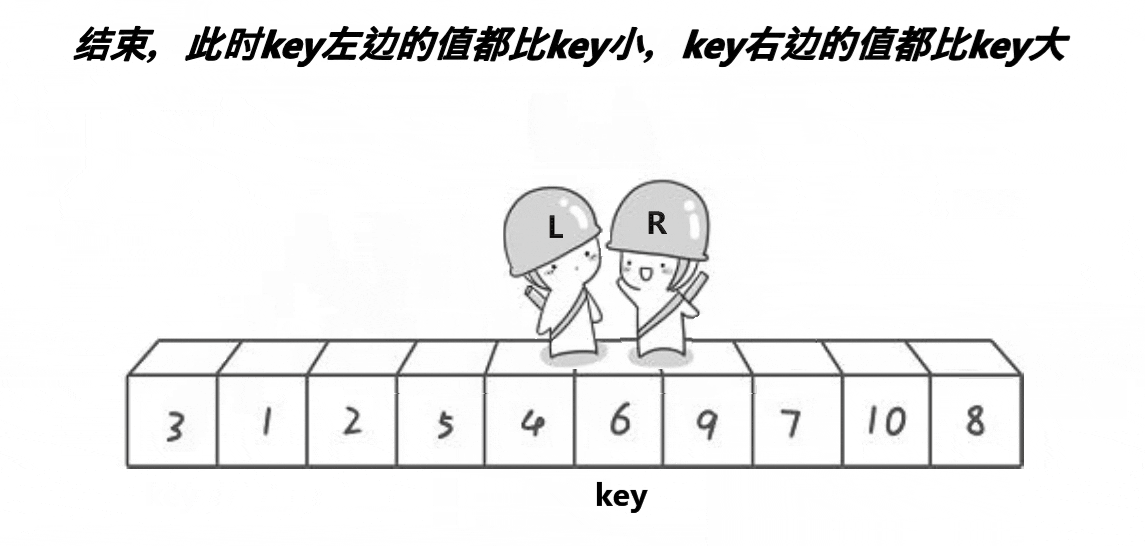
简单点讲就是我们找到一个数成为key,然后从右边出发找到比key小的数(如5)
?
然后左边再出发找比key大的数(如7)
?
然后让这两个值交换,意义是把比key小的值尽量放左边,比key大的值尽量放右边
?
交换完之后呢,右边再继续找小(如4)
?
左边也继续找大(如9)
?
然后两者再进行交换
?
再继续找小(如3)
?
再继续找大,但没找到反而相遇了,那就停下
?
然后最让key与相遇的位置交换
?
最后我们发现比key小的都在其左边,比key大的都在右边了。
 ?
?
右边找比key小的值找到后停下换左边找比key大的值然后也停下最后二者交换,直到key到达最终位置。
所以单趟的意义就是:使key到达正确(排好序要放的位置)
老规矩,我们先来分析一下单趟排序代码:
?
那不妨想一想如果key左边5个数有序,右边4个数也有序,那么就完成排序的目的了。
而这又与我们之前学习的二叉树遍历很像,根,左子树,右子树遍历,再对左子树进行分割根,左子树,右子树遍历——前序遍历。
当我们把这个想象成二叉树分治遍历,那么就是排序全部完成的时候了。
?
我们可以快速来一遍单趟,设3为key,然后右边找小(2),左边找大(没找到相遇了),与key交换。?
?
3不用动了,再分割出左边选一个key出来。?
??
继续右边找小(找不到)交换。?
??
我们把它看成二叉树,当排好最后一组时开始往回递归,遇到key为2的一组时再往右递进,发现是空子树回归,然后继续往上到key为3的一组,对其右子树(5 4 )继续递进。
?
至此,左边排序已经排好了。?
??
?这样对右子树(6右边的排序)持续下去结束后,整个数组的排序完成。
?接下来是代码部分:
int PartSort(int* a, int left, int right) { int key = a[left]; while (left < right) { //找小 while (a[right] > key) { right--; } //找大 while (a[left] < key) { left++; } Swap(&a[right], &a[left]); } Swap(key, &a[left]); return left; }我们定好key下标,首先当left与right相遇的时候(left==right)才会让key交换,所以我们第一层循环用的是left<right。
然后是找大和找小我们第二层循环就正常比较大小++和--就行了。
我们作好大体框架再从细节处出发(找bug):
当我们修改数组中的2个数字再次排序时。
?
我们会发现left与right都会在6这个位置停下,这样造成的结果就是死循环!
所以我们需要修改条件
?
而在我们处理好上面这个问题后又会出现新问题:数组越界?
?
可以发现如果是如图中数组,那么right就会不断--移出数组外造成越界问题。
?
所以需要添加条件(让right--时遇到left就停下,避免越界),left同理。?
int PartSort(int* a, int left, int right)
{
int key = a[left];
while (left < right)
{
//找小
while (left<right && a[right] >= key)
{
right--;
}
//找大
while (left < right && a[left] <= key)
{
left++;
}
Swap(&a[right], &a[left]);
}
Swap(&key, &a[left]);
return left;
}还有一个问题:当key发生交换的时候只是数值发生了交换,但key还是在原来的位置,所以我们需要把它移动到交换后的位置。
?
这样就可以
int PartSort(int* a, int left, int right) { int keyi = left; while (left < right) { //找小 while (left<right && a[right] >= a[keyi]) { right--; } //找大 while (left < right && a[left] <= a[keyi]) { left++; } Swap(&a[right], &a[left]); } Swap(&a[keyi], &a[left]); return left; }
接下来就是处理分治问题:?
void QuickSort(int* a, int begin, int end)
{
int keyi = PartSort(a, begin, end);
//[begin,keyi-1]key[keyi+1,end]
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi + 1, end);
} ?
?
然后我们需要制定一个结束的条件:
- 只有一个数的时候(left==right)结束
- 没有数的时候(left>right)
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
{
return;
}
int keyi = PartSort(a, begin, end);
//[begin,keyi-1]key[keyi+1,end]
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi + 1, end);
}?
下面这是递归展开图:?
 ?
?
我们来用100万个随机数来测试一下快排的性能
 ?
?
可以看到快排的效率是名不虚传的~
在我们写完快排后再来回顾几个问题:
为什么相遇的位置一定比key小呢?
如果相遇的位置比key大,那交换肯定是会出问题的。
?
?
我们重新按原位置开始走,当快要相遇时,在R先走的情况下?,能让R停下的是比key小的3。这样是让L走然后与R相遇。验证了R先走,相遇值比key小。
?
如果一开始是L先走,走到同样情景时,因为是L先走它会去找比key大的数,就这样找到了9,也与R相遇,但这样最后交换是错误的,相遇的位置比key大。
?
我们再换一种情况,把3换成10:
?
我们会发现如果是R先走,那么它会找小,最后越过10找到了4并与L相遇.因为L的位置一定是比key小的数字,毕竟它下标对应的数字是由R(负责找比key小的数字)找到并交换过来的。验证了R先走,相遇值比key小。
?
那如果是L先走呢?在10停下后等R相遇然后交换,最后发现交换是错误的,因为出现了左边(10)比key(6)大的情况,相遇值比key大。
最后是一种极端情况:在几乎是升序的数组里R从右边先走直到和L相遇,相遇的位置没有比key小。交换后对其右边的一组数值再进行分治划分,
??
经过这几种情况分析我们可以发现,如果是L先走然后相遇值都是比key大的,并且交换都会出现错误。而在R先走然后相遇值都是比key小的,并且交换不会出现错误。
相信大家应该发现了,key在左边的时候我们就让右边先走,key在右边的时候我们让左边先走。
因为当key在左边的时候我们要确保最后的相遇值是比key小的,这样交换过来才能符合升序的规则,所以我们让R先走确保它找到的值一定是小的。同理key在右边时我们要确保交换过来的相遇值要比key大,这样才能符合升序规则,而让L先走就一定能确保它找到的是比key大的值。
最终我们需要学会根据key的位置不同,升序降序的规则不同合理作出相应的变化~
下面我们来分析快排的第二个问题:快排的效率分析
假设我们每一次选出的key都是中位数就会呈现出这种情况
?
我们可以看到每一层的单趟排序其实都可以看作是N次执行(在数很多的情况下),因为每一层合计起来也差不多是N这个量级。
?
而它的高度是logN,这样它的总的时间复杂度度就是O(N*logN)
?
但这只是比较理想的情况下,如果是在接近有序的情况下,它的高度就会变成N,这样时间复杂度的就会是O(N^2)
?
为了避免快排在有序的情况下效率受到干扰,我们设置了一个叫三数取中的方法。(不是位置取中,而是数值取中)
改变选key的策略,不再是固定选左边的值作key,但如果是中间的值作key又是先走左边还是右边呢,这样也会影响到单趟排序。其实我们可以一直选左边的值作key,就算你选到的key在中间把它换到左边就行了。
这样无论是有序还是无序最终key的交换落点都能尽量落到与下图差不多的位置,避免了有序时算法效率的损耗。
最终代码:?
int GetMidi(int* a, int left, int right)
{
int mid = (left + right) / 2;
// left mid right
if (a[left] < a[mid])
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[left] > a[right]) // mid是最大值
{
return left;
}
else
{
return right;
}
}
else // a[left] > a[mid]
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[left] < a[right]) // mid是最小
{
return left;
}
else
{
return right;
}
}
}
int PartSort(int* a, int left, int right)
{
int midi = GetMidi(a,left,right);
Swap(&a[midi], &a[left]);
int keyi = left;
while (left < right)
{
//找小
while (left<right && a[right] >= a[keyi])
{
right--;
}
//找大
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[right], &a[left]);
}
Swap(&a[keyi], &a[left]);
return left;
}
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
{
return;
}
int keyi = PartSort(a, begin, end);
//[begin,keyi-1]key[keyi+1,end]
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi + 1, end);
} 三.结语
三.结语
本次我们介绍了hoare的快排法,相信大家都发现了有很多的坑点需要我们注意,不过放心,下一篇文章我会介绍在原基础上优化更加的其他快排法~最后感谢大家的观看,友友们能够学习到新的知识是额滴荣幸,期待我们下次相见~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Springboot+vue项目使用RSA公私钥对返回数据加解密
- 力扣labuladong——一刷day95
- 用友U8 Cloud smartweb2.RPC.d XXE漏洞复现
- RT-Thread简介
- 数据结构学习 Jz48最长不含重复字符的子字符串
- 【C语言】作用域 和 生命周期
- echarts tooltip 提示框阴影设置
- 品牌全球化:关于跨界合作的探索与解析
- c++拷贝控制
- RabbitMQ搭建集群环境、配置镜像集群、负载均衡