【大数据】Hudi HMS Catalog 完全使用指南
Hudi HMS Catalog 完全使用指南
1.Hudi HMS Catalog 基本介绍
功能亮点:当 Flink 和 Spark 同时接入 Hive Metastore(HMS)时,用 Hive Metastore 对 Hudi 的元数据进行管理,无论是使用 Flink 还是 Spark 引擎建表,另外一种引擎或者 Hive 都可以直接查询。
本文以 HDP 集群为例,其他版本分别为:
- Flink:
1.13.6 - Spark:
3.2.1 - Hudi:
0.12.0
在 HDP 集群中,Hive 的配置文件路径为 /etc/hive/conf,所以在 Flink SQL Client 中使用 Hive 的配置文件来创建 hudi-hive catalog,从而将 Hudi 元数据存储于 hive metastore 中。
2.在 Flink 中写入数据
在 Flink SQL Client 中进行如下操作:
create catalog hudi with(
'type' = 'hudi',
'mode' = 'hms',
'hive.conf.dir'='/etc/hive/conf'
);
--- 创建数据库供hudi使用
create database hudi.hudidb;
Flink SQL Client 中建表:
--- order表
CREATE TABLE hudi.hudidb.orders_hudi(
uuid INT,
ts INT,
num INT,
PRIMARY KEY(uuid) NOT ENFORCED
) WITH (
'connector' = 'hudi',
'table.type' = 'MERGE_ON_READ',
'hive_sync.conf.dir' = '/etc/hive/conf' --如果hive是配置了Kerberos,必须指定
);
--- product表
CREATE TABLE hudi.hudidb.product_hudi(
uuid INT,
ts INT,
name STRING,
PRIMARY KEY(uuid) NOT ENFORCED
) WITH (
'connector' = 'hudi',
'table.type' = 'MERGE_ON_READ',
'hive_sync.conf.dir' = '/etc/hive/conf'
);
--- 宽表
CREATE TABLE hudi.hudidb.orders_product_hudi(
uuid INT,
ts INT,
name STRING,
num INT,
PRIMARY KEY(uuid) NOT ENFORCED
) WITH (
'connector' = 'hudi',
'table.type' = 'MERGE_ON_READ',
'hive_sync.conf.dir' = '/etc/hive/conf'
);
使用 Flink SQL 进行数据写入:
insert into hudi.hudidb.orders_hudi values
(1, 1, 2),
(2, 2, 3),
(3, 3, 4);
insert into hudi.hudidb.product_hudi values
(1, 1, 'tony'),
(2, 2, 'mike'),
(3, 3, 'funny');
insert into hudi.hudidb.orders_product_hudi
select
hudi.hudidb.orders_hudi.uuid as uuid,
hudi.hudidb.orders_hudi.ts as ts,
hudi.hudidb.product_hudi.name as name,
hudi.hudidb.orders_hudi.num as num
from hudi.hudidb.orders_hudi
inner join hudi.hudidb.product_hudi on hudi.hudidb.orders_hudi.uuid = hudi.hudidb.product_hudi.uuid;
3.在 Flink SQL 中查看数据
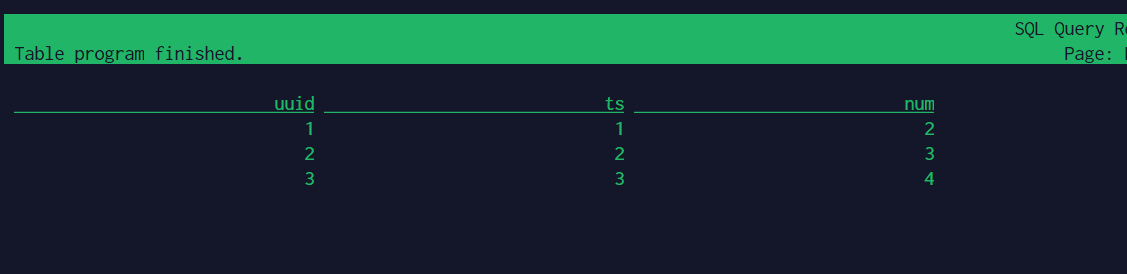
select * from hudi.hudidb.orders_hudi;
得到:
select * from hudi.hudidb.product_hudi;
得到:

select * from hudi.hudidb.orders_product_hudi;
得到:

4.在 Spark 中查看数据
Hive 为了连接集群 Hive Metastore,只需要将 Hive 的配置文件 hive-site.xml 放置到 Spark 的配置文件目录即可。
通过 beeline 连接 spark thriftserver,查看数据库:
show databases;
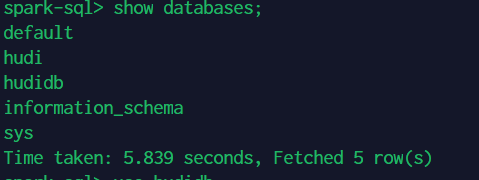
可以看到刚刚在 Flink 中创建的 hudidb 数据库。现在查看里面的表:
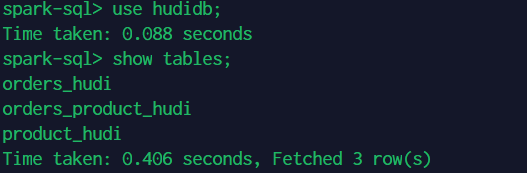
use hudidb;
show tables;
由于在将数据写入 Hudi 时,默认会新增 _hoodie_commit_time、_hoodie_record_key、precombine 以及 _hoodie_file_name 用于内部使用,如果使用 select * 进行查询时会查出上述字段。
以查看 orders_hudi 表数据为例:
select * from orders_hudi;

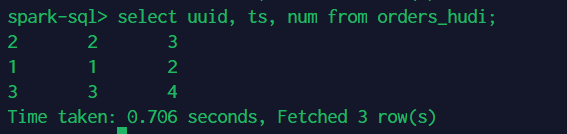
所以为了正确查询,需要指定字段:
select uuid, ts, num from orders_hudi;
5.在 Hive 中查看数据
Hudi MOR 表在将元数据同步到 Hive 时,会同时生成以 _ro 和 _rt 结尾的两张子表。例如有一张表名称为 product_hudi,那么此时,数据库中会有三张和 product_hudi 相关的表,分别为原始 product_hudi 表、product_hudi_ro 和 product_hudi_rt。
ro表表示读优化(read-optimized)查询,只查询 MOR 表中的parquet文件部分。rt表表示快照(real-time,实时)查询,查询全表,该操作需要合并avro和parquet文件,较为耗时。product_hudi表用于 Flink 或者 Spark 的元数据管理。
为了在 Hive 引擎中查看,对于 MERGE_ON_READ 表,至少需要执行过一次压缩,也就是把 avro 文件压缩为 parquet 文件,才能够正常查看数据。由于上述操作为批量操作,默认是不会触发压缩操作的,所以需要手动触发压缩(该操作 master 分支会支持)。
所以对 product_hudi 表进行手动压缩
./bin/flink run -c \
org.apache.hudi.sink.compact.HoodieFlinkCompactor \
lib/hudi-flink1.13-bundle_2.12-0.12.0.jar \
--path hdfs://bigdata:8020/warehouse/tablespace/managed/hive/hudidb.db/product_hudi \
--schedule
注意:如果是使用 Flink 将数据实时流式写入 Hudi 的话,默认在写入五次时会自动触发压缩,不需要手动执行。
为了在 Hive 中查看 Hudi 所有数据,需要设置如下参数:
set hive.input.format = org.apache.hadoop.hive.ql.io.HiveInputFormat;
如果设置该参数出现如下报错:
Error: Error while processing statement: Cannot modify hive.input.format at runtime. It is not in list of params that are allowed to be modified at runtime (state=42000,code=1)
那么通过如下方式修改 hive-site.xml 配置,新增如下配置,然后重启 Hive 即可。
hive.security.authorization.sqlstd.confwhitelist.append = hive.input.format

进入 Hive 客户端
设置变量:
set hive.input.format = org.apache.hadoop.hive.ql.io.HiveInputFormat;
查看数据库:
show databases;
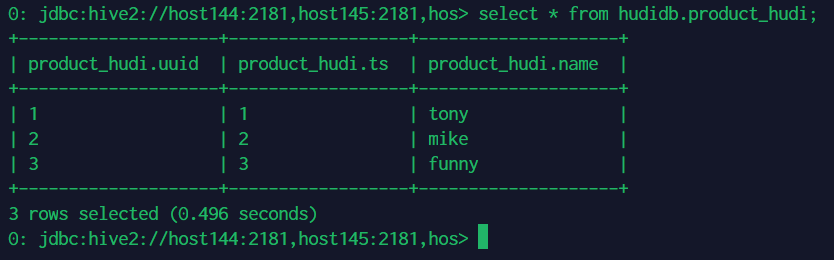
查看 hudidb 库中 product_hudi 表数据:
select * from hudidb.product_hudi;
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 用友U8+CRM help2 任意文件读取漏洞复现
- 数组中的内存(java)
- 7+非肿瘤+WGCNA+机器学习+诊断模型,构思巧妙且操作简单
- Android 最新版build.gradle添加GMS、firebase.crashlytics
- vue 响应式页面使用transform实现
- 手撕HashMap底层源码
- 【万题详解】洛谷P1252 马拉松接力赛
- Nodejs获取IP地理地址和免费接口
- 众和策略:大盘震荡企稳开年来调整或渐近尾声
- JVM—垃圾回收