S^3 FD: Single Shot Scale-invariant Face Detector(2017)

Abstract
本文提出了一种单镜头尺度不变人脸检测器(Single Shot Scale-invariant face detector, s^3fd),该检测器利用单个深度神经网络对不同尺度的人脸进行检测,尤其对小人脸的检测效果更好。具体地说,我们试图解决一个常见的问题,即基于锚点的检测器会随着目标的变小而急剧退化。
我们在以下三个方面做出了贡献:1)提出了一个尺度均衡的人脸检测框架,可以很好地处理不同尺度的人脸。我们在广泛的图层上平铺锚点,以确保所有尺度的人脸都有足够的特征用于检测。此外,我们还基于有效接受野和提出的等比例区间原则设计锚定尺度;2)采用尺度补偿锚点匹配策略提高小人脸的召回率;3)通过max-out背景标签降低小人脸的误报率。
因此,我们的方法在所有常见的人脸检测基准测试中实现了最先进的检测性能,包括AFW、PASCAL人脸、FDDB和WIDER face数据集,并且可以在Nvidia Titan X (PASCAL)上以36 FPS的速度运行vga分辨率图像。
Introduction
锚点探测器的性能随着物体变小而急剧下降。为了提出一种基于尺度不变锚点的人脸检测方法,我们综合分析了上述问题背后的原因: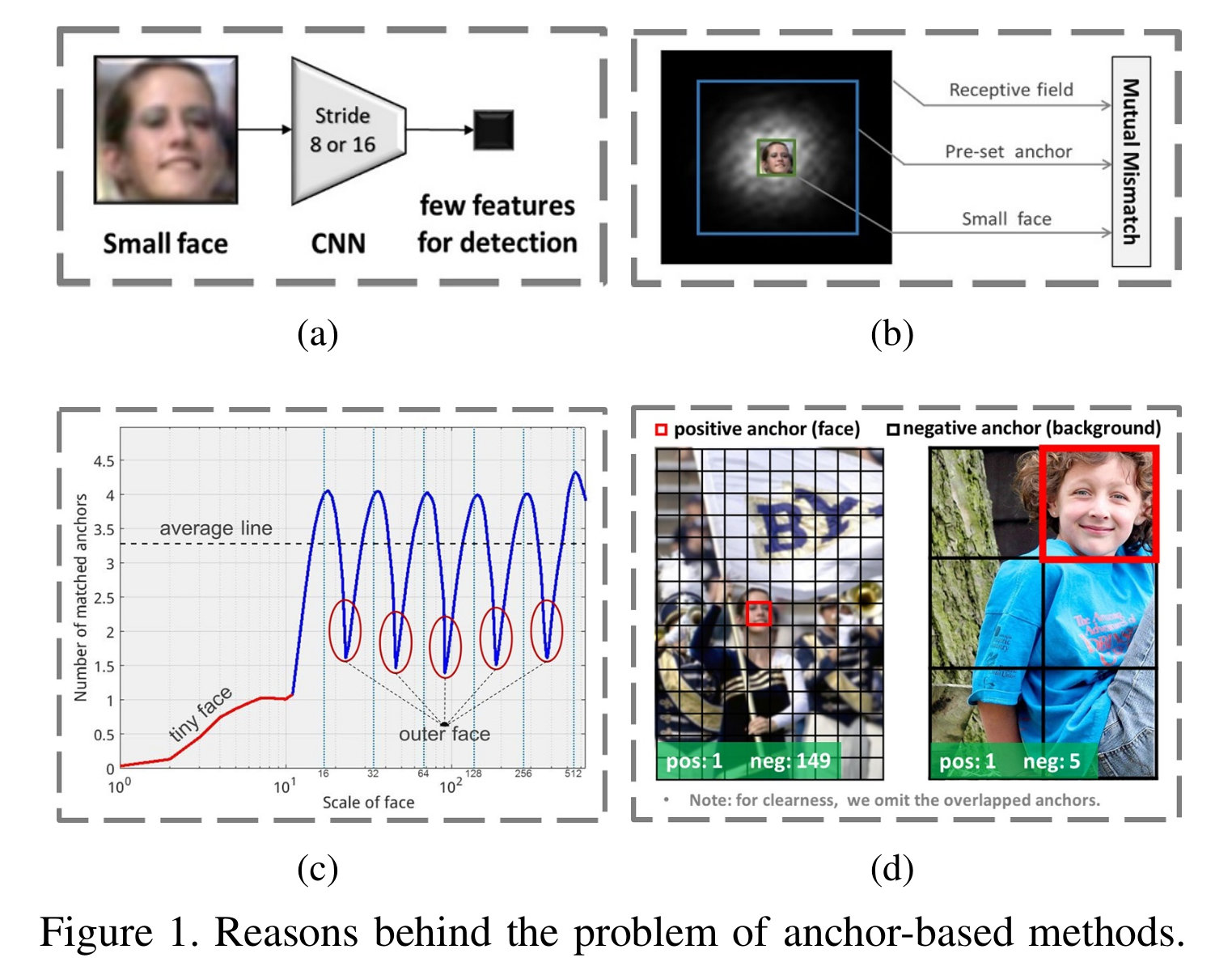
a)小人脸在检测层的特征较少。b)锚定尺度与接受野不匹配,两者都太大,无法适应小脸。
d)这两个图形具有相同的分辨率。左边的一个贴小锚来检测小脸,右边的一个贴大锚来检测大脸。小锚会在背景上带来大量的负面锚。
Biased framework
基于锚点的检测框架容易遗漏中小面。首先,最低锚关联层的步长太大(例如,[26]为8像素,[38]为16像素),因此这些层上的小面和中面被高度压缩,并且用于检测的特征很少,见图1(a)。其次,小脸、锚定尺度和感受野是相互不匹配的:锚定尺度与感受野不匹配,两者都太大而无法适应小脸,见图1(b)。为了解决上述问题,我们提出了一个尺度公平的人脸检测框架。我们将锚点平铺在跨度从4到128像素不等的大范围层上,这保证了不同尺度的人脸有足够的特征进行检测。此外,我们根据有效感受场[29]和新的等比例间隔原则,设计了不同层上16 ~ 512像素的锚点,确保了不同层的锚点与其对应的有效感受场相匹配,并且不同尺度的锚点均匀分布在图像上。
Anchor matching strategy
在基于锚点的检测框架中,锚点尺度是离散的(即在我们的方法中为16,32,64,128,256,512),但人脸尺度是连续的。因此,那些尺度偏离锚点尺度的人脸无法匹配足够的锚点,如图1?中的小脸和外脸,导致其召回率较低。为了提高这些被忽略的人脸的召回率,我们提出了一种分两阶段的尺度补偿锚匹配策略。第一阶段遵循当前的锚点匹配方法,但调整了一个更合理的阈值。第二阶段通过尺度补偿确保每个尺度的面匹配足够的锚点。
Background from small anchors
为了很好地检测小人脸,必须在图像上密集地平铺大量的小锚点**。如图1(d)所示,这些小锚导致背景上的负面锚数量急剧增加**,产生了许多假阳性面孔。例如,在我们的尺度均衡框架中,超过75%的负面锚点来自最低的conv33层,该层用于检测小面孔。为了降低小人脸的误报率,本文在最低检测层提出了一种最大输出背景标签。
Contribution
?提出一种尺度均衡的人脸检测框架,该框架具有广泛的锚关联层和一系列合理的锚尺度,可以很好地处理不同尺度的人脸。
?提出一种尺度补偿锚匹配策略,提高小人脸的召回率。
?引入max-out背景标签,降低小人脸的高误报率。
?以实时速度在AFW, PASCAL face, FDDB和WIDER face上实现最先进的结果。
Single shot scale-invariant face detector
Scale-equitable framework
我们的尺度均衡框架是基于基于锚点的检测框架,如RPN[38]和SSD[26]。尽管取得了巨大的成就,但该框架的主要缺点是,随着人脸变小,性能会急剧下降[12]。为了提高对面尺度的鲁棒性,我们开发了一个具有广泛锚相关层的网络架构,其步幅大小从4像素逐渐增加到128像素。因此,我们的架构确保了不同尺度的人脸在相应的锚相关层具有足够的特征进行检测。在确定锚点位置后,我们根据有效接受场和等比例间隔原则设计了16 ~ 512像素的锚点尺度。前者保证每个尺度的锚点与相应的有效感受野匹配良好,后者使不同尺度的锚点在图像上具有相同的密度。
Constructing architecture

它由基础卷积层、额外卷积层、检测卷积层、归一化层、预测卷积层和多任务损失层组成。
?基础卷积层:我们保留从conv11到pool5的VGG16层,并删除所有其他层
?额外的卷积层:我们通过对VGG16的fc6和fc7的参数进行子采样[4],将其转换为卷积层,然后在其后面添加额外的卷积层。这些层的大小逐渐减小,形成多尺度特征图。
?检测卷积层:我们选择conv3.3、conv4.3、conv5.3、convfc7、conv6.2和conv7.2作为检测层,它们与不同尺度的锚相关联,以预测检测。
?归一化层:与其他检测层相比,conv3.3、conv4.3和conv5.3具有不同的特征尺度。因此,我们使用L2归一化[27]将它们的范数分别调整为10,8和5,然后在反向传播过程中学习尺度。
?预测卷积层:每个检测层后面是一个p×3×3×q卷积层,其中p和q为输入和输出的通道号,3×3为内核大小。对于每个锚点,我们预测相对于其坐标的4个偏移量和N s评分用于分类,其中对于conv33检测层,N s = N m + 1 (N m是最大背景标签),对于其他检测层,N s = 2。
?多任务损失层:我们使用softmax损失进行分类,使用平滑L1损失进行回归
Designing scales for anchors
六个检测层中的每一个都与特定的尺度锚点(即表1中的第三列)相关联,以检测相应的尺度面。我们的锚是1:1的宽高比(即方形锚),因为人脸的边界框近似为方形。如表1第二列和第四列所示,每个检测层的步长和接受野是固定的,这是我们设计锚定尺度时的两个基点:
?有效接受野
?等比例间隔原理
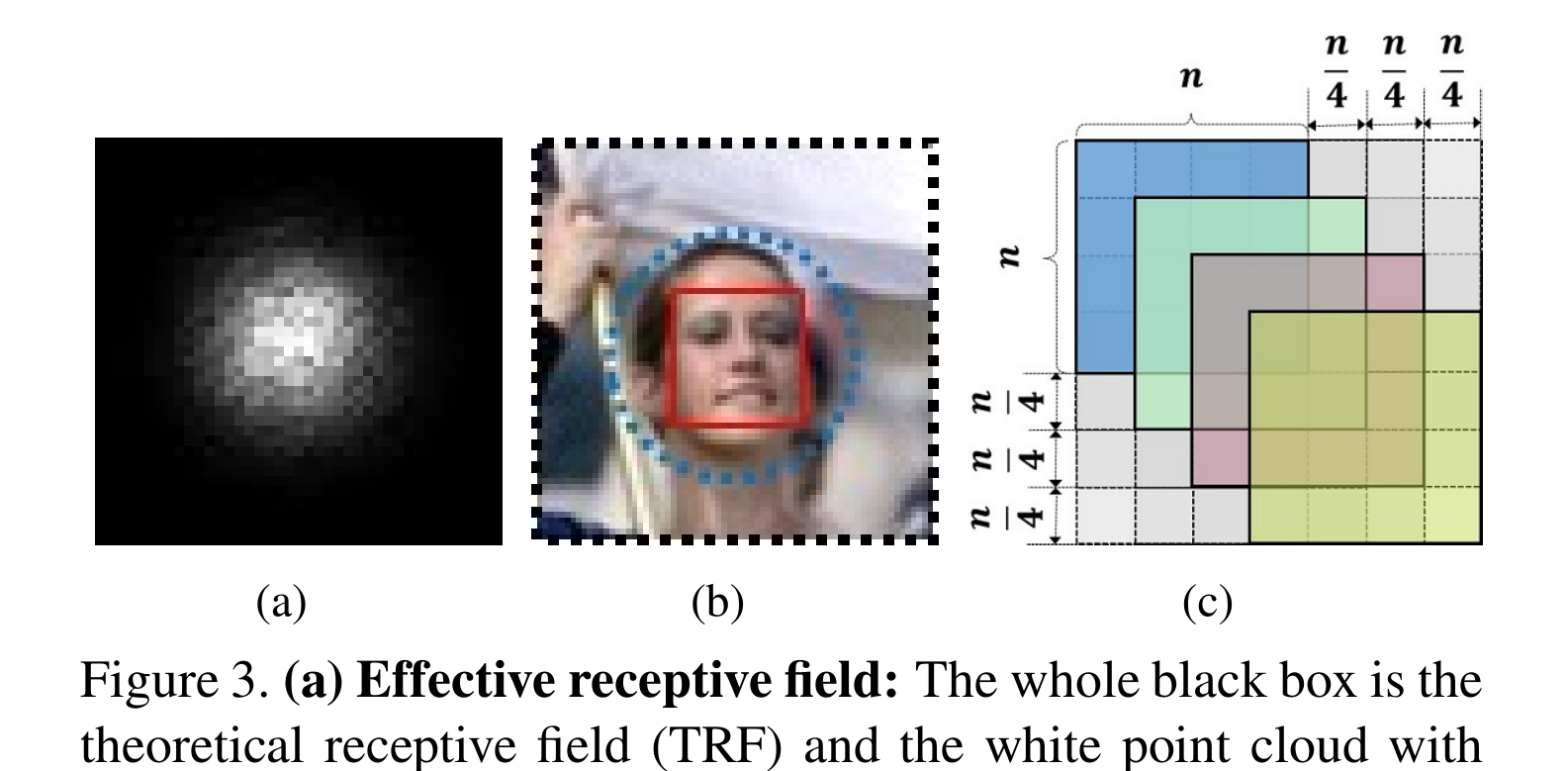
整个黑箱为理论感受野(TRF),具有高斯分布的白点云为有效感受野(ERF)。ERF只占TRF的一小部分,b中篮筐为ERF
?等比例区间原则:设n为锚标,则n/4为该尺度锚标的区间。N /4也对应于与此锚关联的层的步长。
Scale compensation anchor matching strategy
?第一阶段:我们遵循当前的锚匹配方法,但将阈值从0.5降低到0.35,以增加匹配锚的平均数量。
?第二阶段:在第一阶段之后,一些面仍然没有匹配足够的锚点,例如图4(a)中灰色虚线标记的微小面和外部面。我们对每一个面进行如下处理:首先挑选出与该面jaccard重叠度大于0.1的锚点,然后对它们进行排序,选择top-N作为该面的匹配锚点。我们设N为阶段一的平均值。
(a)比较当前锚点匹配方法与我们的尺度补偿锚点匹配策略对不同尺度人脸的匹配数量。(b)最大化背景标签的说明
Max-out background label
在图像上密集地铺上大量的小锚点来检测小人脸,这会导致负锚点的数量急剧增加。例如,如表2所示,一张640 × 640的图像共有34125个锚点,其中约75%来自与最小锚点相关联的conv33检测层(16 × 16)。这些最小的锚对假阳性面孔的贡献最大。因此,通过平铺小锚来提高小人脸的检出率,必然会导致小人脸的高假阳性率
为了解决这个问题,我们建议在底层应用更复杂的分类策略来处理来自小锚点的复杂背景。我们对conv33检测层应用max-out背景标签。对于每个最小的锚点,我们预测背景标签的N m分数,然后选择最高的作为其最终分数,如图4(b)所示。Max-out运算将一些局部最优解集成到我们的s3fd模型中,以降低小人脸的误报率
另外还采用了数据增强硬负样本挖掘等策略来提高小人脸的检测精度
Experiment
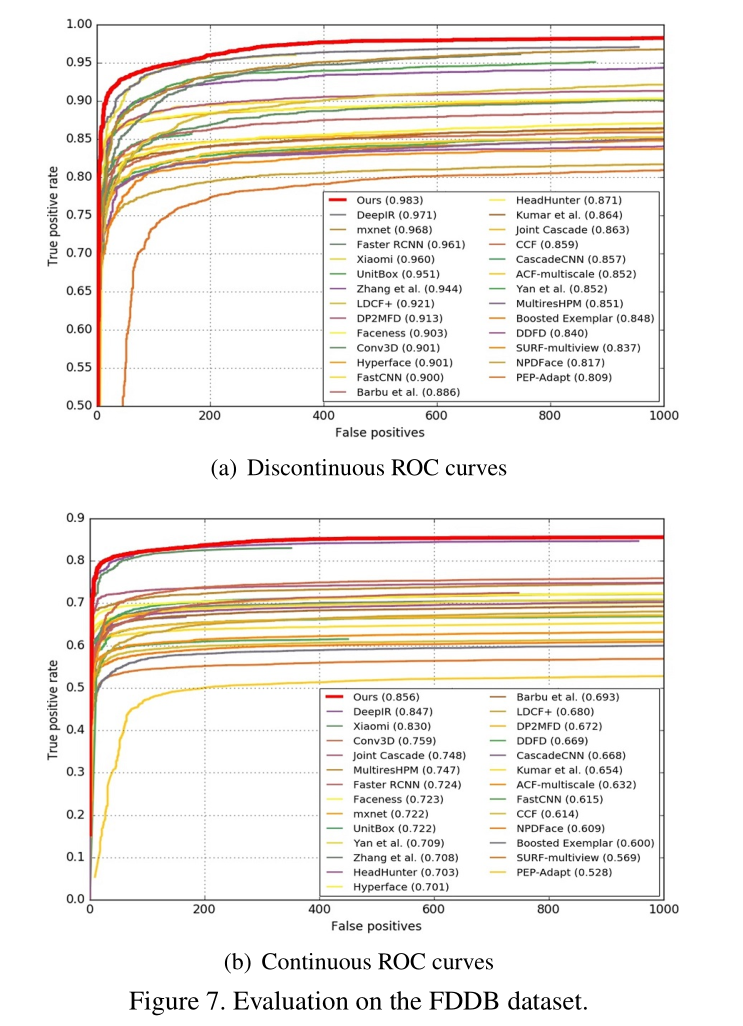
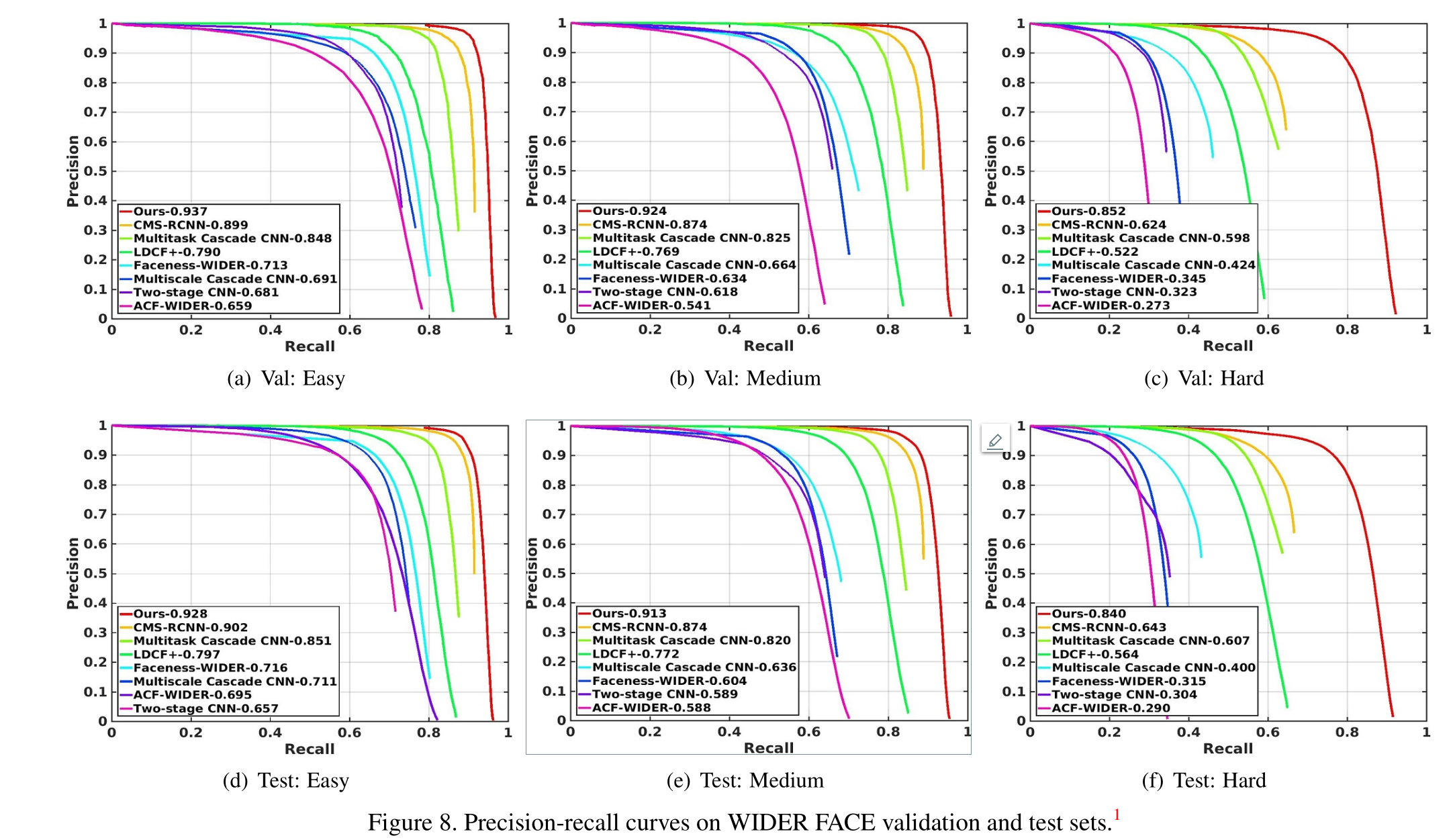
在AFW、PASCAL人脸、FDDB和WIDER face数据集上都取得了最先进的结果



Conclusion
针对基于锚点的人脸检测方法随着目标变小而性能急剧下降的问题,本文提出了一种新的人脸检测方法。我们分析了这一问题背后的原因,并提出了一个具有广泛锚关联层和一系列合理锚尺度的尺度均衡框架,以更好地处理不同尺度的人脸。此外,我们提出了尺度补偿锚匹配策略来提高小人脸的召回率,并提出了最大化背景标签来降低小人脸的误报率。实验表明,我们的三个贡献使得s^3fd在所有常见的人脸检测基准上都达到了最先进的性能,特别是对于小人脸。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!