Google ASPIRE框架:赋予大型语言模型(LLMs)自我评估的新动力
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/ 。?

在人工智能的飞速发展中,一个名为ASPIRE的新框架让大型语言模型(LLMs)的潜能再上一层楼。ASPIRE的核心在于教会LLMs不仅仅是回答问题,更重要的是,对这些答案进行自我评估,就像学生在教科书后面核对答案一样。该框架包括三个关键阶段:特定任务的调整、答案采样和自我评估学习。
首先是特定任务的调整。ASPIRE通过调整特定任务的参数(θp)来培训LLMs,同时保持模型本身的稳定。在这一阶段,LLMs通过使用一些参数效率高的调整技术,如软提示调整和LoRA,针对特定任务进行微调。这种微调不仅提高了模型的预测准确性,还增加了正确输出序列的可能性。
接下来是答案采样阶段。ASPIRE使用经过特定任务调整的LLMs为每个训练问题生成不同的答案,并为自我评估学习创建数据集。这里,束搜索算法被用于生成高可能性的输出序列,而Rouge-L度量则用于判断这些输出序列是否正确。
最后,是自我评估学习阶段。在为每个查询生成高可能性的输出后,ASPIRE通过添加可适应参数(θs)并仅对其进行微调来学习自我评估。冻结原始的θ和经过学习的θp参数可以确保在自我评估学习过程中不会改变LLM的预测行为。最终目的是优化θs,使得经过适应的LLM能够自行区分正确和错误的答案。
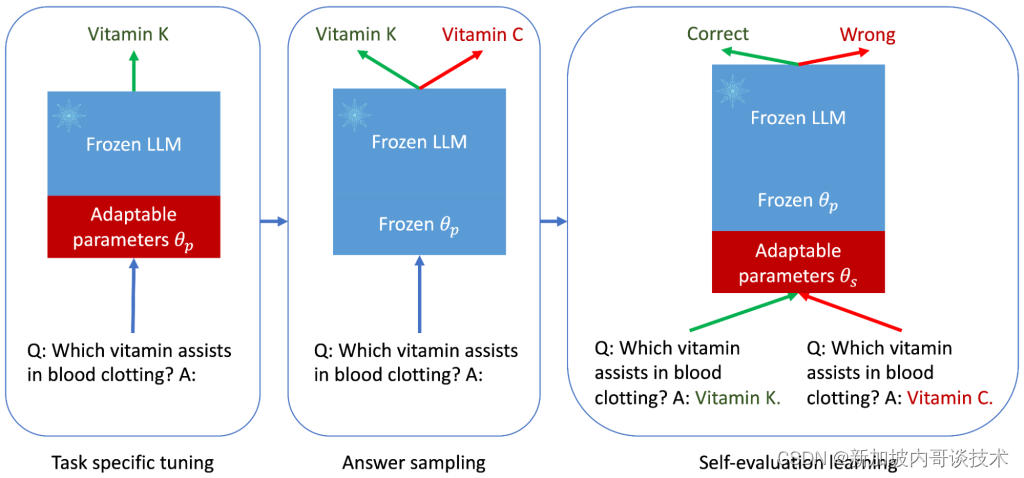
这个框架的实施主要是通过软提示调整来完成的。通过这种机制,可以学习“软提示”来使冻结的语言模型更有效地执行特定的下游任务。实验结果表明,使用ASPIRE调整后的LLMs在多个问答数据集上表现出色,例如CoQA、TriviaQA和SQuAD。在这些测试中,即使是比大型预训练模型更小的LLMs,也能通过ASPIRE实现类似甚至更高的准确性。
通过ASPIRE框架的应用,LLMs在选择性预测任务中的性能得到了显著提升,这不仅展示了LLMs在自我评估方面的潜力,也为未来AI在关键应用领域中的应用开辟了新道路。研究团队对ASPIRE的未来应用充满期待,并邀请社区共同参与这一激动人心的旅程。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!