java8 列表通过 stream流 根据对象属性去重的三种实现方法
发布时间:2024年01月19日
java8 列表通过 stream流 根据对象属性去重的三种实现方法
一、简单去重
public class DistinctTest {
/**
* 没有重写 equals 方法
*/
@Setter
@Getter
@ToString
@AllArgsConstructor
@NoArgsConstructor
public static class User {
private String name;
private Integer age;
}
/**
* lombok(@Data) 重写了 equals 方法 和 hashCode 方法
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class User2 {
private String name;
private Integer age;
}
@Test
public void easyTest() {
List<Integer> integers = Arrays.asList(1, 1, 2, 3, 4, 4, 5, 6, 77, 77);
System.out.println("======== 数字去重 =========");
System.out.print("原数字列表:");
integers.forEach(x -> System.out.print(x + " "));
System.out.println();
System.out.print("去重后数字列表:");
integers.stream().distinct().collect(Collectors.toList()).forEach(x -> System.out.print(x + " "));
System.out.println();
System.out.println();
List<User> list = Lists.newArrayList();
User three = new User("张三", 18);
User three2 = new User("张三", 18);
User three3 = new User("张三", 24);
User four = new User("李四", 18);
list.add(three);
list.add(three);
list.add(three2);
list.add(three3);
list.add(four);
System.out.println("======== 没有重写equals方法的话,只能对相同对象(如:three)进行去重,不能做到元素相同就可以去重) =========");
// 没有重写 equals 方法时,使用的是超类 Object 的 equals 方法
// 等价于两个对象 == 的比较,只能筛选同一个对象
System.out.println("初始对象列表:");
list.forEach(System.out::println);
System.out.println("简单去重后初始对象列表:");
list.stream().distinct().collect(Collectors.toList()).forEach(System.out::println);
System.out.println();
System.out.println();
List<User2> list2 = Lists.newArrayList();
User2 five = new User2("王五", 18);
User2 five2 = new User2("王五", 18);
User2 five3 = new User2("王五", 24);
User2 two = new User2("二蛋", 18);
list2.add(five);
list2.add(five);
list2.add(five2);
list2.add(five3);
list2.add(two);
System.out.println("======== 重写了equals方法的话,可以做到元素相同就可以去重) =========");
// 所以如果只需要写好 equals 方法 和 hashCode 方法 也能做到指定属性的去重
System.out.println("初始对象列表:");
list2.forEach(System.out::println);
System.out.println("简单去重后初始对象列表:");
list2.stream().distinct().collect(Collectors.toList()).forEach(System.out::println);
}
}
二、根据对象某个属性去重
0、User对象
/**
* 没有重写 equals 方法
*/
@Setter
@Getter
@ToString
@AllArgsConstructor
@NoArgsConstructor
public static class User {
private String name;
private Integer age;
}
1、使用filter进行去重
@Test
public void objectTest() {
List<User> list = Arrays.asList(
new User(null, 18),
new User("张三", null),
null,
new User("张三", 24),
new User("张三5", 24),
new User("李四", 18)
);
System.out.println("初始对象列表:");
list.forEach(System.out::println);
System.out.println();
System.out.println("======== 使用 filter ,根据特定属性进行过滤(重不重写equals方法都不重要) =========");
System.out.println("根据名字过滤后的对象列表:");
// 第一个 filter 是用于过滤 第二个 filter 是用于去重
List<User> collect = list.stream().filter(o -> o != null && o.getName() != null)
.filter(distinctPredicate(User::getName)).collect(Collectors.toList());
collect.forEach(System.out::println);
System.out.println("根据年龄过滤后的对象列表:");
List<User> collect1 = list.stream().filter(o -> o != null && o.getAge() != null)
.filter(distinctPredicate(User::getAge)).collect(Collectors.toList());
collect1.forEach(System.out::println);
}
/**
* 列表对象去重
*/
public <K, T> Predicate<K> distinctPredicate(Function<K, T> function) {
// 因为stream流是多线程操作所以需要使用线程安全的ConcurrentHashMap
ConcurrentHashMap<T, Boolean> map = new ConcurrentHashMap<>();
return t -> null == map.putIfAbsent(function.apply(t), true);
}
测试

①、疑惑
既然 filter 里面调用的是 distinctPredicate 方法,而该方法每次都 new 一个新的 map 对象,那么 map 就是新的,怎么能做到可以过滤呢
②、解惑
先看一下 filter 的部分实现逻辑,他使用了函数式接口 Predicate ,每次调用filter时,会使用 predicate 对象的 test 方法,这个对象的test 方法就是 null == map.putIfAbsent(function.apply(t), true)
而 distinctPredicate 方法作用就是生成了一个线程安全的 Map 集合,和一个 predicate 对象,且该对象的 test 方法为 null == map.putIfAbsent(function.apply(t), true)
之后 stream 流的 filter 方法每次都只会使用 predicate 对象的 test 方法,而该 test 方法中的 map 对象在该流中是唯一的,并不会重新初始化
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
2、使用Collectors.toMap() 实现根据某一属性去重(这个可以实现保留前一个还是后一个)
要注意 Collectors.toMap(key,value) 中 value 不能为空,会报错,key 可以为 null,但会被转换为字符串的 “null”
@Test
public void objectTest() {
List<User> list = Arrays.asList(
new User(null, 18),
new User("张三", null),
null,
new User("张三", 24),
new User("张三5", 24),
new User("李四", 18)
);
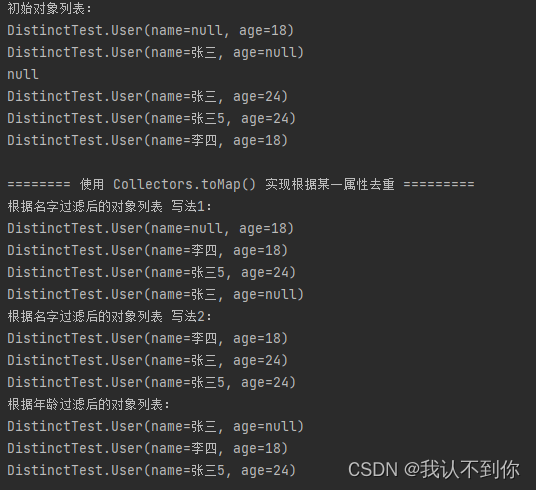
System.out.println("初始对象列表:");
list.forEach(System.out::println);
System.out.println();
System.out.println("======== 使用 Collectors.toMap() 实现根据某一属性去重 =========");
System.out.println("根据名字过滤后的对象列表 写法1:");
// (v1, v2) -> v1 的意思 两个名字一样的话(key一样),存前一个 value 值
Map<String, User> collect = list.stream().filter(Objects::nonNull).collect(Collectors.toMap(User::getName, o -> o, (v1, v2) -> v1));
// o -> o 也可以写为 Function.identity() ,两个是一样的,但后者可能比较优雅,但阅读性不高,如下
// Map<String, User> collect = list.stream().filter(Objects::nonNull).collect(Collectors.toMap(User::getName, Function.identity(), (v1, v2) -> v1));
List<User> list2 = new ArrayList<>(collect.values());
list2.forEach(System.out::println);
System.out.println("根据名字过滤后的对象列表 写法2:");
Map<String, User> map2 = list.stream().filter(o -> o != null && o.getName() != null)
.collect(HashMap::new, (m, o) -> m.put(o.getName(), o), HashMap::putAll);
list2 = new ArrayList<>(map2.values());
list2.forEach(System.out::println);
System.out.println("根据年龄过滤后的对象列表:");
// (v1, k2) -> v2 的意思 两个年龄一样的话(key一样),存后一个 value 值
Map<Integer, User> collect2 = list.stream().filter(Objects::nonNull).collect(Collectors.toMap(User::getAge, o -> o, (v1, v2) -> v2));
list2 = new ArrayList<>(collect2.values());
list2.forEach(System.out::println);
}
测试
2.2、Collectors.toMap() 的变种 使用 Collectors.collectingAndThen()
Collectors.collectingAndThen()函数 它可接受两个参数,第一个参数用于reduce操作,而第二参数用于map操作。也就是,先把流中的所有元素传递给第一个参数,然后把生成的集合传递给第二个参数来处理。
@Test
public void objectTest() {
List<User> list = Arrays.asList(
new User(null, 18),
new User("张三", null),
null,
new User("张三", 24),
new User("张三5", 24),
new User("李四", 18)
);
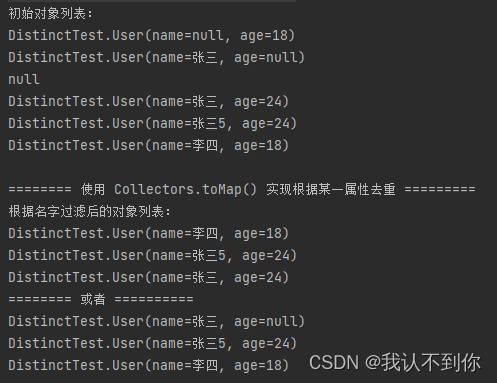
System.out.println("初始对象列表:");
list.forEach(System.out::println);
System.out.println();
System.out.println("======== 使用 Collectors.toMap() 实现根据某一属性去重 =========");
System.out.println("根据名字过滤后的对象列表:");
ArrayList<User> collect1 = list.stream().filter(o -> o != null && o.getName() != null).collect(
Collectors.collectingAndThen(Collectors.toMap(User::getName, o -> o, (k1, k2) -> k2), x-> new ArrayList<>(x.values())));
collect1.forEach(System.out::println);
System.out.println("======== 或者 ==========");
List<User> collect = list.stream().filter(o -> o != null && o.getName() != null).collect(
Collectors.collectingAndThen(Collectors.toCollection(
() -> new TreeSet<>(Comparator.comparing(User::getName))), ArrayList<User>::new));
collect.forEach(System.out::println);
}
测试
三、测试哪个方法比较快
@Test
public void objectTest() {
List<User> list = new ArrayList<>(Arrays.asList(
new User(null, 18),
new User("张三", null),
null,
new User("张三", 24),
new User("张三5", 24),
new User("李四", 18)
));
for (int i = 0; i < 100000; i++) {
list.add(new User((Math.random() * 10) + "", (int) (Math.random() * 10)));
}
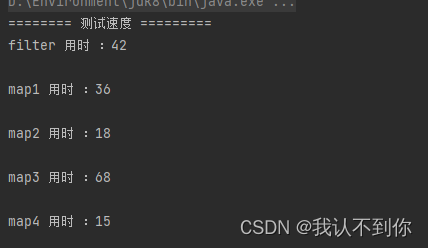
System.out.println("======== 测试速度 =========");
long startTime = System.currentTimeMillis();
List<User> list1 = list.stream().filter(o -> o != null && o.getName() != null)
.filter(distinctPredicate(User::getName)).collect(Collectors.toList());
long endTime = System.currentTimeMillis();
System.out.println("filter 用时 :" + (endTime - startTime));
System.out.println();
startTime = System.currentTimeMillis();
Map<String, User> map1 = list.stream().filter(o -> o != null && o.getName() != null)
.collect(Collectors.toMap(User::getName, o -> o, (v1, v2) -> v1));
List<User> list2 = new ArrayList<>(map1.values());
endTime = System.currentTimeMillis();
System.out.println("map1 用时 :" + (endTime - startTime));
System.out.println();
startTime = System.currentTimeMillis();
ArrayList<User> list3 = list.stream().filter(o -> o != null && o.getName() != null).collect(
Collectors.collectingAndThen(Collectors.toMap(User::getName, o -> o, (k1, k2) -> k2), x -> new ArrayList<>(x.values())));
endTime = System.currentTimeMillis();
System.out.println("map2 用时 :" + (endTime - startTime));
System.out.println();
startTime = System.currentTimeMillis();
List<User> list4 = list.stream().filter(o -> o != null && o.getName() != null).collect(
Collectors.collectingAndThen(Collectors.toCollection(
() -> new TreeSet<>(Comparator.comparing(User::getName))), ArrayList<User>::new));
endTime = System.currentTimeMillis();
System.out.println("map3 用时 :" + (endTime - startTime));
System.out.println();
startTime = System.currentTimeMillis();
Map<String, User> map2 = list.stream().filter(o -> o != null && o.getName() != null)
.collect(HashMap::new, (m, o) -> m.put(o.getName(), o), HashMap::putAll);
List<User> list5 = new ArrayList<>(map2.values());
endTime = System.currentTimeMillis();
System.out.println("map4 用时 :" + (endTime - startTime));
}
测试:
四、结论
1、去重最快:
ArrayList<User> list3 = list.stream().filter(o -> o != null && o.getName() != null).collect(
Collectors.collectingAndThen(Collectors.toMap(User::getName, o -> o, (k1, k2) -> k2), x -> new ArrayList<>(x.values())));
// 或者
Map<String, User> map2 = list.stream().filter(o -> o != null && o.getName() != null)
.collect(HashMap::new, (m, o) -> m.put(o.getName(), o), HashMap::putAll);
List<User> list5 = new ArrayList<>(map2.values());
2、其次
Map<String, User> map1 = list.stream().filter(o -> o != null && o.getName() != null)
.collect(Collectors.toMap(User::getName, o -> o, (v1, v2) -> v1));
List<User> list2 = new ArrayList<>(map1.values());
// distinctPredicate 是一个方法 本文中有 ,可以 ctrl + f 查找
List<User> list1 = list.stream().filter(o -> o != null && o.getName() != null)
.filter(distinctPredicate(User::getName)).collect(Collectors.toList());
3、最慢
List<User> list4 = list.stream().filter(o -> o != null && o.getName() != null).collect(
Collectors.collectingAndThen(Collectors.toCollection(
() -> new TreeSet<>(Comparator.comparing(User::getName))), ArrayList<User>::new));
文章来源:https://blog.csdn.net/qq_57581439/article/details/135699993
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python异常、模块和包
- DDD领域驱动设计(五)
- Vue的父子页面如何相互传值和调用方法
- js的继承方式
- 【网络安全】全网最全的渗透测试介绍(超详细)
- windows编程-网络编程快速入门(非常核心)
- 98. 验证二叉搜索树(LeetCode)
- C语言初始化效率问题以及关键字解释
- POE API 驱动 OpenAI API 依赖服务
- 多维时序 | Matlab实现CNN-BiLSTM-Mutilhead-Attention卷积双向长短期记忆神经网络融合多头注意力机制多变量时间序列预测