yolov8n 瑞芯微RKNN和地平线Horizon芯片仿真测试部署,部署工程难度小、模型推理速度快
发布时间:2024年01月12日
??特别说明:参考官方开源的yolov8代码、瑞芯微官方文档、地平线的官方文档,如有侵权告知删,谢谢。
??模型和完整仿真测试代码,放在github上参考链接 模型和代码。
??因为之前写了几篇yolov8模型部署的博文,存在两个问题:部署难度大、模型推理速度慢。该篇解决了这两个问题,且是全网部署难度最小、模型运行速度最快的部署方式。相对之前写的一篇【yolov8 瑞芯微RKNN和地平线Horizon芯片仿真测试部署】将DFL写在后处理中模型加速了,针对后处理进行优化后时耗略微增加。
1 模型和训练
??训练代码参考官方开源的yolov8训练代码。
2 导出 yolov8 onnx
?? 导出onnx增加以下几行代码:
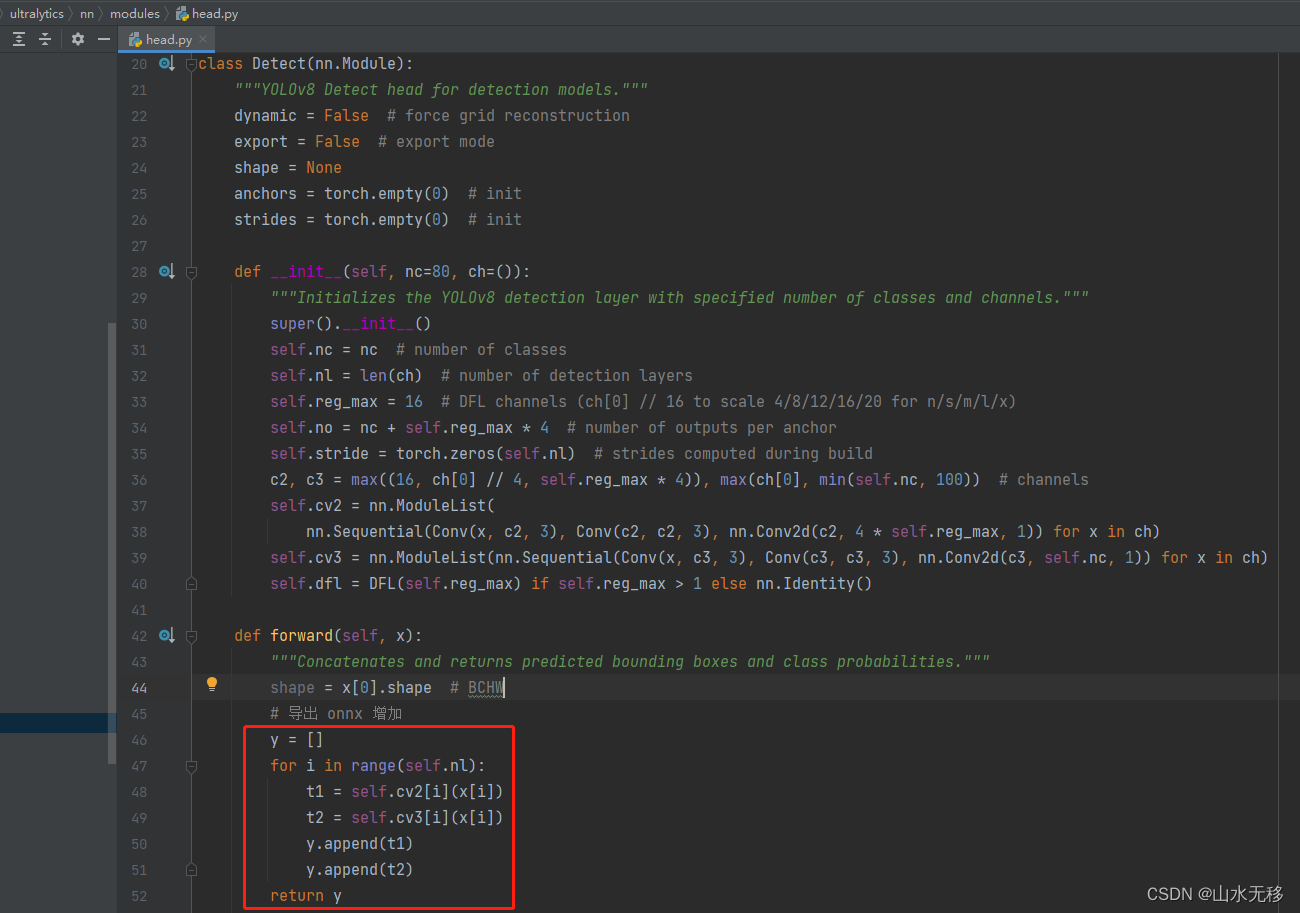
# 导出 onnx 增加
y = []
for i in range(self.nl):
t1 = self.cv2[i](x[i])
t2 = self.cv3[i](x[i])
y.append(t1)
y.append(t2)
return y
??增加保存onnx模型代码
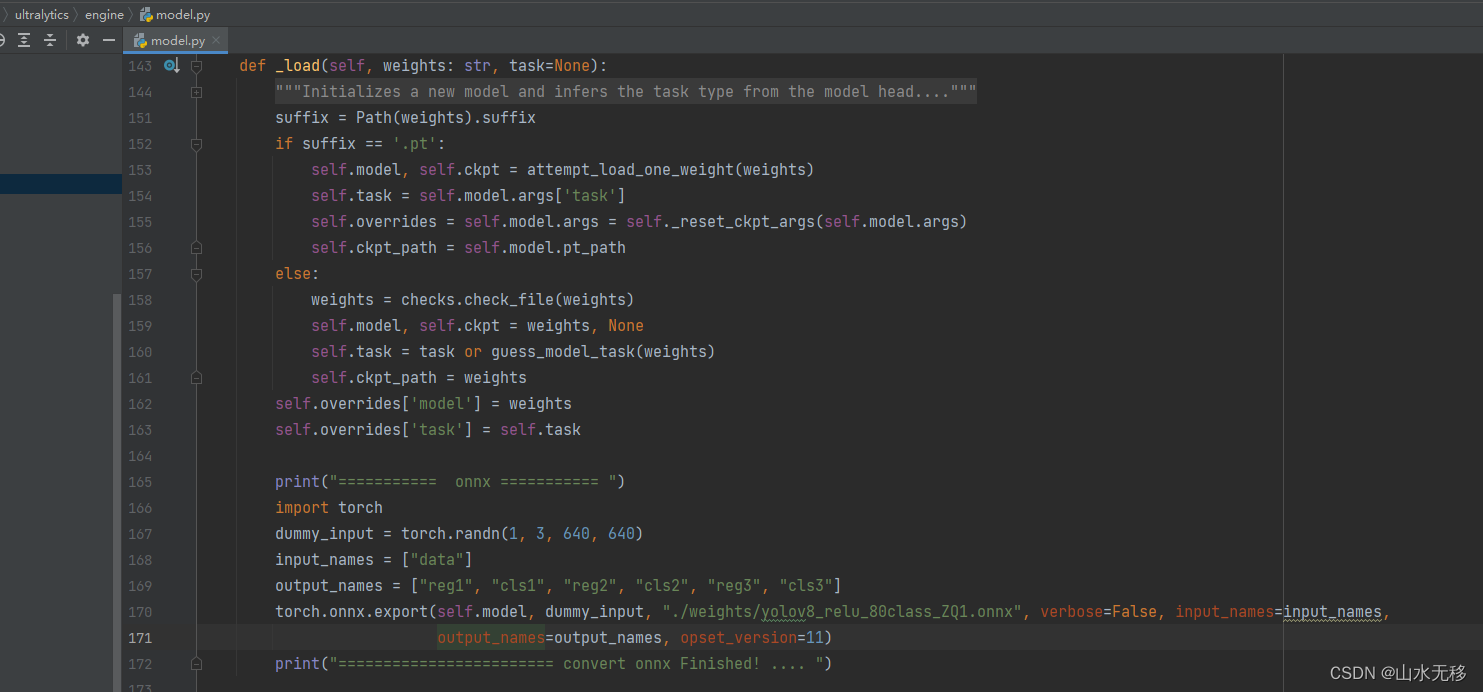
print("=========== onnx =========== ")
import torch
dummy_input = torch.randn(1, 3, 640, 640)
input_names = ["data"]
output_names = ["reg1", "cls1", "reg2", "cls2", "reg3", "cls3"]
torch.onnx.export(self.model, dummy_input, "./weights/yolov8_relu_80class_ZQ1.onnx", verbose=False, input_names=input_names, output_names=output_names, opset_version=11)
print("======================== convert onnx Finished! .... ")
??修改完以上两个地方,运行推理脚本(运行会报错,但不影响onnx文件的生成)。
from ultralytics import YOLO
# 推理
model = YOLO('./weights/yolov8n_relu_ZQ_80class.pt')
results = model(task='detect', mode='predict', source='./images/test.jpg', line_width=3, show=True, save=True, device='cpu')
3 yolov8 onnx 测试效果
??onnx模型和测试完整代码,放在github上代码。

4 tensorRT 优化前后时耗
??上一篇【yolov8 瑞芯微RKNN和地平线Horizon芯片仿真测试部署】tensorRT部署推理10000次的平均时耗(显卡 Tesla V100、cuda_11.0)
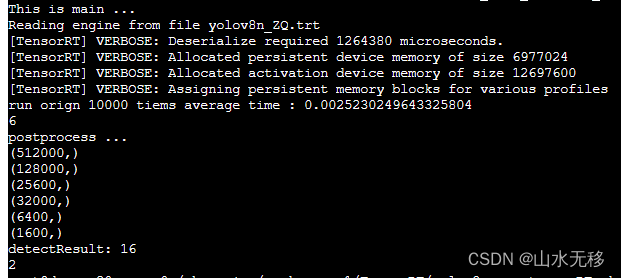
本篇tensorRT部署推理10000次的平均时耗(显卡 Tesla V100、cuda_11.0)

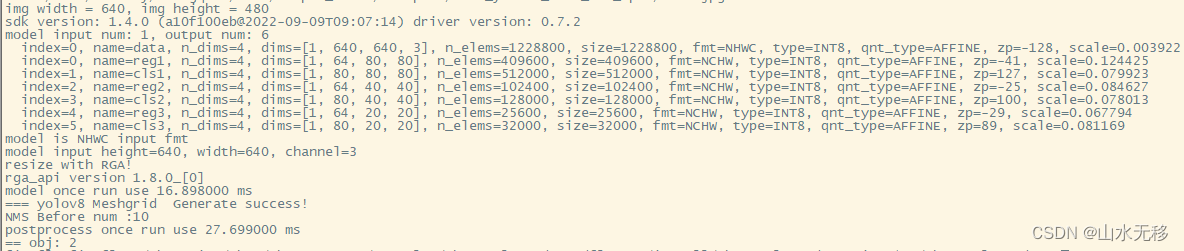
5 rknn 板端C++部署
??把板端C++代码的模型和时耗也给贴出来供大家参考,使用芯片rk3588。相对之前在rk3588上推理40ms,降到了17ms,后处理稍微有增加。
??上一篇【yolov8 瑞芯微RKNN和地平线Horizon芯片仿真测试部署】部署到rknn3588上的C++时耗
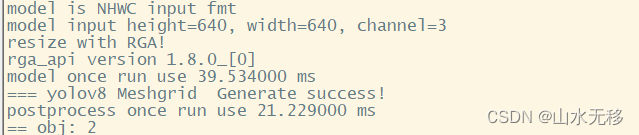
??本篇部署方法时耗
文章来源:https://blog.csdn.net/zhangqian_1/article/details/135523096
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 面试必备!机器学习常用十大算法的优缺点!
- linux网络配置
- LENOVO联想笔记本小新Pro 14 IRH8 2023款(83AL)电脑原装出厂Win11系统恢复预装OEM系统
- 作为Java程序员还不知道Spring中Bean创建过程和作用?
- 信号处理基础之噪声与降噪(一) | 噪声分类及python代码实现
- JVM初识
- 前端Vue日常工作中--Vue路由相关
- 【hyperledger-fabric】使用couchDB
- uniapp多组数组 搜索高亮效果demo(整理)
- “KBDROPR.DLL文件丢失,软件或游戏无法启动”,解决方法,亲测有效