《深入理解C++11:C++11新特性解析与应用》笔记六

第六章 提高性能及操作硬件的能力
6.1 常量表达式
6.1.1 运行时常量性与编译时常量性
大多数情况下,const描述的是运行时常量性,也即是运行时数据的不可更改性。但有时候我们需要的却是编译时的常量性,这是const关键字无法保证的。例如:

c++11使用constexpr关键字声明常量表达式,不仅限于函数,也可以作用于数据声明,以及类的构造函数。
6.1.2 常量表达式函数
在函数返回类型前加入关键字constexpr来使其称为常量表达式函数,另外还有几点要求:
1.函数体只有单一的return返回语句。
2.函数必须返回值。
3.在使用前必须已有定义。
4.return返回语句表达式中不能使用非常量表达式的函数、全局数据,且必须是一个常量表达式。
多条语句的写法一般无法通过编译,但是一些不会产生实际代码的语句在常量表达式函数中使用,不会引起编译错误,例如static_assert、using、typedef等。
6.1.3 常量表达式的值
由constexpr关键字修饰的变量就是所谓的常量表达式值。常量表达式值必须被一个常量表达式赋值,必须在使用前被初始化。
编译器可以不为常量表达式的值生成数据,仅将其当做编译器的值。
c++11允许编译时的浮点数常量表达式的值,标准要求编译时浮点常量表达式值的精度至少等于或高于运行时的浮点数常量的精度。
c++11标准中,constexpr关键字不能用于修饰自定义类型的定义。正确的做法是定义自定义常量构造函数。

常量表达式的构造函数也有两点约束:
1.函数体必须为空。
2.初始化列表只能由常量表达式来赋值。
虽然声明的是常量表达式构造函数,但编译时的常量性体现在类型上。


PRCfound的成员变量也具有编译时的常量性。
c++11不允许常量表达式作用于virtual的成员函数。
6.1.4 常量表达式的其他应用
常量表达式可以用于模板函数。c++11规定,当声明为常量表达式的模板函数后,当某个该模板函数的实例化结果不满足常量表达式的需求的话,constexpr会被自动忽略。实例化后的函数将成为一个普通函数。
常量表达式可以用于递归函数。例如:

基于模板的编译时期运算的编程方式,通常被称为模板元编程。例如:

并不是使用了constexpr,编译器就一定会在编译时期对常量表达式函数进行值计算。
6.2 变长模板
6.2.1 变长函数和变长的模板参数
c++11支持c99的变长宏。printf则使用了c语言的函数变长参数特征。例子:


变长函数的第一个参数表示的是变长参数的个数。而被调用者中,需要通过一个类型为va_list的数据结构ap来辅助地获得参数。首先使用va_start函数对ap进行初始化,使得ap称为被传递的变长参数的一个句柄。而后代码再使用va_arg函数从ap中将参数一一取出用于运算。
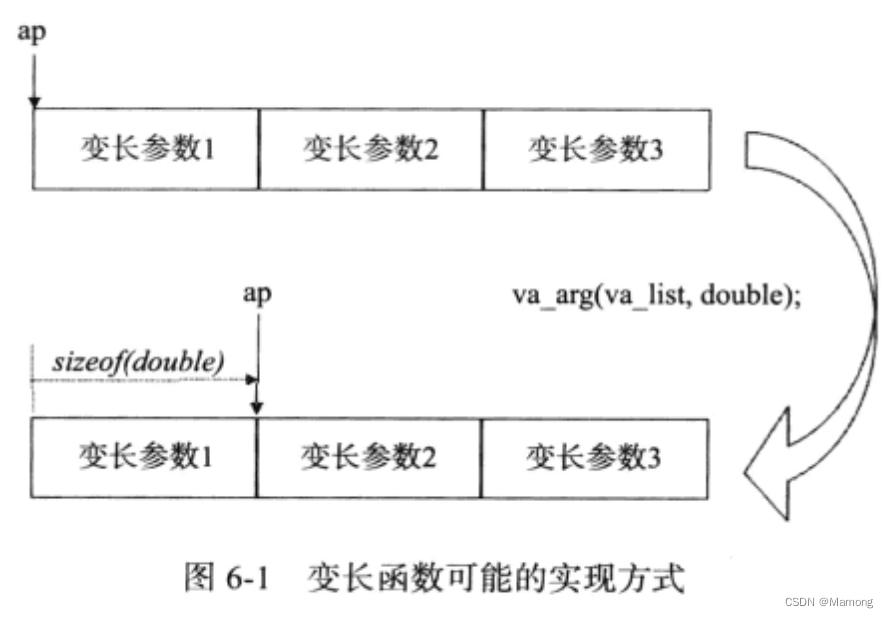
一方面,变长函数本身完全无法知道参数数量或者参数类型。另一方面,c++需要更为现代化的变长参数的实现方式,类型和变量同时能传递给变长参数的函数。一个好的方式就是使用c++的函数模板。c++98中标准要求函数模板始终具有数目确定的模板参数及函数参数。
类也需要不定长度的模板参数。c++98中没有变长模板,tuple能够支持的模板参数数量实际上是由标准库定义了多少个不同参数版本的tuple模板而决定的。c++11中tuple可以接受任意多个不同类型的元素的集合。
6.2.2 变长模板:模板参数包和函数参数包
c++11中的一个tuple变长类模板:template<typename ...Elements> class tuple;其中Elements被称为模板参数包(template parameter pack)。对于实例化的tuple模板类:tuple<int, char, double>,编译器可以将多个模板参数打包为单个的模板参数包Elements,即Elements在进行模板推导的时候,就是一个包含int、char和double三种类型的类型集合。
与普通的模板参数类似,模板参数包也可以是非类型的,比如:

一个模板参数包在模板推导时会被认为是模板的单个参数。为了使用模板参数包,总是需要将其解包,通常通过包扩展(pack expansion)的表达式来完成。
template<typename ...A> class Template:private B<A...>{};
这里的表达式A...就是一个包扩展,参数包会在包扩展的位置上展开为多个参数。比如:

这里类模板B总是接受两个参数的前提下,如果我们声明了一个Template<X,Y,Z>就会发生模板推导的错误。c++11中,实现tuple模板使用了递归的手段,使得模板参数包在实例化时能够层层展开,直到参数包中的参数逐渐耗尽或者到达某个数量的边界为止。

除了变长的模板类,在c++11中还可以声明变长模板的函数。除了声明变长个模板参数的模板参数包,也可以声明成函数参数包,比如:template<typename ...T> void f(T ...args);由于T是个变长模板参数,因此args是对应于这些变长类型数据,即函数参数包。c++11中标准要求函数参数包必须唯一,且是函数的最后一个参数,模板参数包没有这样的要求。
6.2.3 变长模板:进阶
标准定义了以下7种参数包可以展开的位置:
1.表达式
2.初始化列表
3.基类描述列表
4.类成员初始化列表
5.模板参数列表
6.通用属性列表
7.lambda函数的捕捉列表
语言的其他地方则无法展开参数包。在不同位置展开参数包会有不同的效果,例如:

类似情况也发生在函数声明上:


除了扩展外,c++11标准还引入了新的操作sizeof...,作用是计算参数包中的参数个数。
变长模板的参数也可以是模板。变长模板参数也可以用于完美转发。
6.3 原子类型与原子操作
6.3.1 并行变成、多线程与c++11
c++11之前,c/c++程序使用线程主要使用POSIX线程(pthread)和OpenMP编译器指令两种标称模型来完成程序的线程化。
c++11标准引入了多线程的支持。一个最为重要的部分是在原子操作中引入了原子类型的概念。
6.3.2 原子操作与c++11原子类型
原子操作就是多线程程序中最小的且不可并行化的操作。通常情况下原子操作都是通过互斥的访问来保证的。c++11标准之前,需要在c/c++代码中嵌入内联的汇编代码。如果想实现粗粒度的互斥,借助POSIX标准的pthread库中的互斥锁也可以做到:


c++11对并行编程更为良好的抽象,实现相同功能就简单多了:

c++11不需要为原子数据类型显式地声明互斥锁或调用加锁、解锁的API,线程就能够对变量互斥地进行访问。c++11标准定义的是原子类型,而传统面向过程编程语言里使用的是原子操作。
c++11与c11标准都支持原子类型。可以通过#include<cstdatomic>头文件来使用对应于内置类型的原子类型定义。
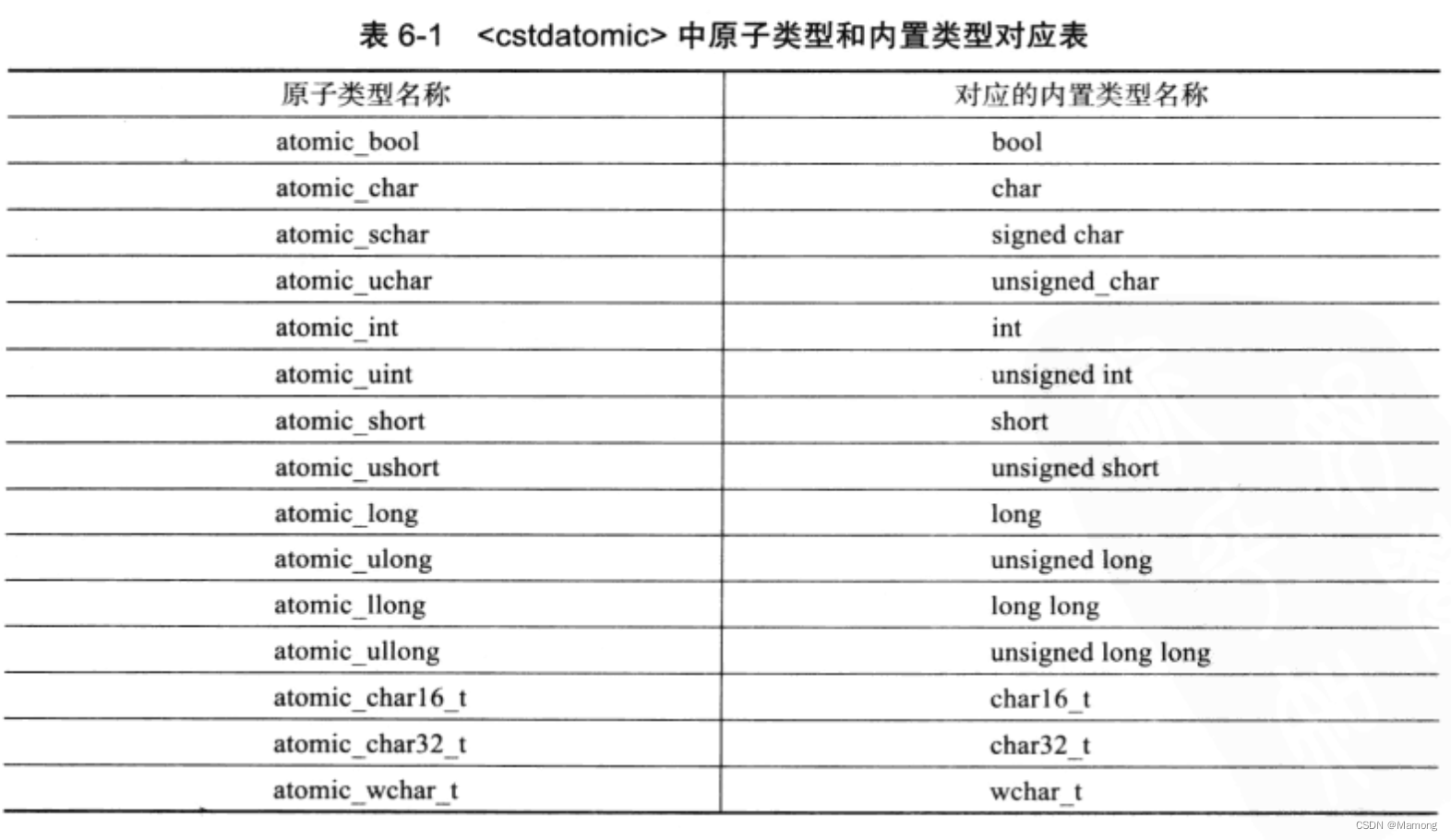
更为普遍地,可以使用atomic类模板定义任意的原子类型,例如:std::atomic<T> t;而c11则需要使用新关键字_Atomic来完成。
多个线程通常只能访问单个原子类型的拷贝,因此原子类型只能从其模板参数类型中进行构造,不允许原子类型进行拷贝构造、移动构造,以及使用operator=等,以防发生意外。
不过从atomic<T>类型的变量来构造其模板参数类型T的变量则是可以的。比如:

因为atomic类模板总是定义了从atomic<T>到T的类型转换函数。
原子类型能够在线程间保持原子性,主要还是因为编译器能够保证针对原子类型的操作都是原子操作。c++11标准将对原子操作定义为atomic模板类的成员函数,对于内置类型而言,主要是重载一些全局操作符来完成的。
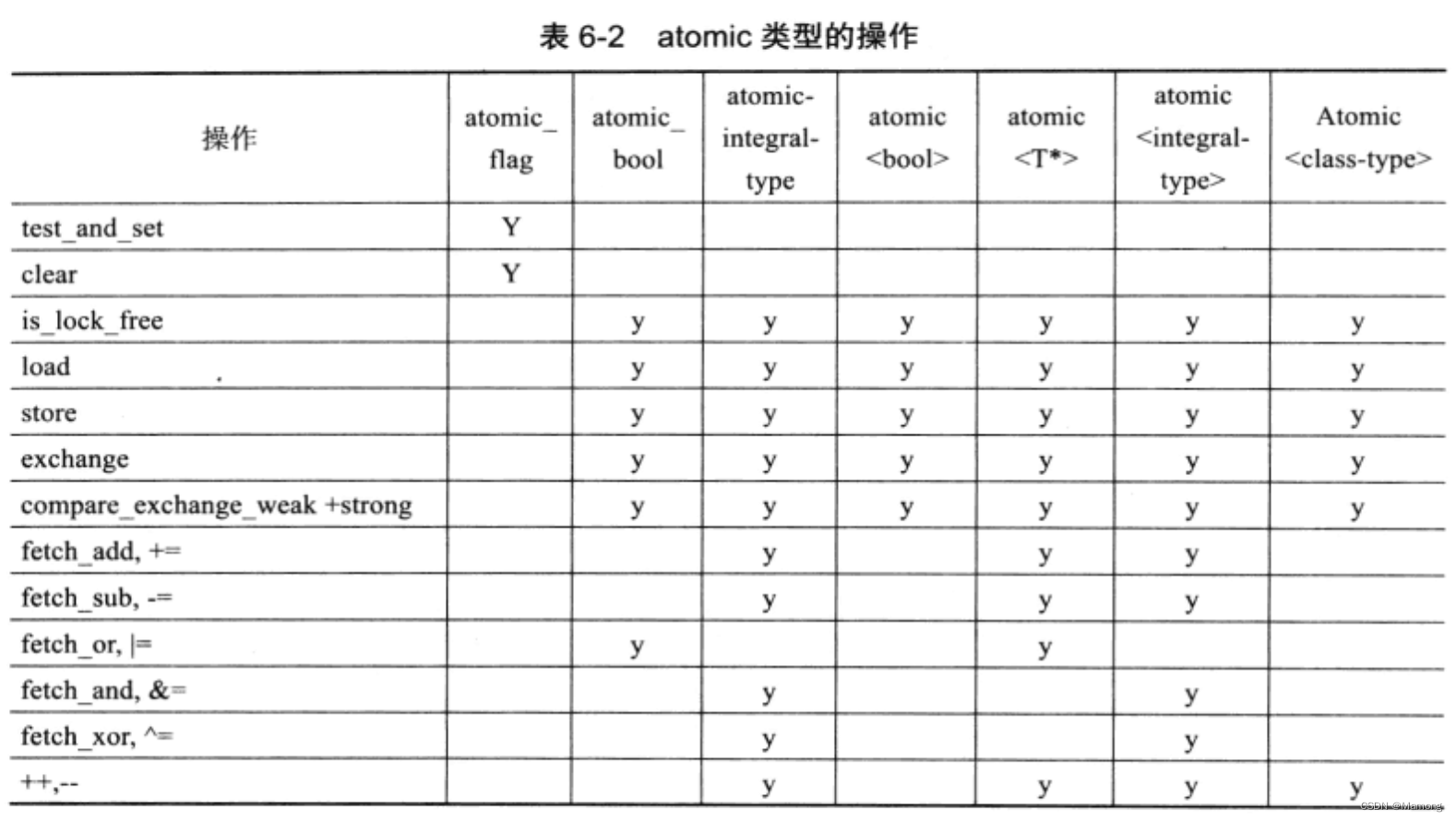
对于大多数原子类型而言,都可以执行读(load),写(store)、交换(exchange)、比较并交换(compare_exchange_weak/compare_exchange_strong)等操作。

atomic_flag是无锁的,
c++11原子操作还可以包含一个参数:memory_order。
6.3.3 内存模型,顺序一致性与memory_order
内存模型通常是一个硬件上的概念,表示的是机器指令是以什么样的顺序被处理器执行的。如果处理器的执行顺序总是按指令顺序,通常称这样的内存模型为强顺序的。反之,则为弱顺序的。如果允许编译器在单个线程中打乱指令的运行顺序,则可能提升并行程序的性能。弱顺序内存模型的平台,如果要保证指令执行顺序,通常要在汇编指令中加入一条所谓的内存栅栏指令。例如PowerPC中的sync指令迫使已经进入流水线中的指令都完成后处理器才执行sync以后的指令。
c++11中的内存模型,要保证代码的顺序一致性,必须同时做到:
1.编译器保证原子操作的指令间顺序不变,即保证产生的读写原子类型的变量的机器指令与代码编写者看到的是一致的。
2.处理器对原子操作的汇编指令的执行顺序不变。对于x86这样的强顺序的体系结构而言,并没有问题;而对于PowerPC这样的弱顺序的体系结构而言,则要求编译器在每次原子操作后加入内存栅栏。
c++11中,原子类型的成员函数总是保证了顺序一致性。对于x86平台来说,禁止了编译器对原子类型变量间的重排序优化;对于PowerPC这样的平台,不仅禁止了编译器优化,还插入了大量的内存栅栏。对于意图提高性能的多线程程序而言,无疑是一种性能伤害。
c++11中,设计者给出的解决方式是让程序员为原子操作指定所谓的内存顺序:memory_order。

(相关使用,未完待续。。。)
6.4 线程局部存储
线程局部存储变量,就是拥有线程生命期及线程可见性的变量。c++11使用thread_local修饰符声明线性局部存储变量。TLS变量的内存的静态/动态分配问题经常被讨论。而c++11标准只对语法做了统一,对其实现并没有做任何性能上的规定。如果想得到最佳的平台上的TLS运行性能,最好还是阅读代码运行平台的相关文档。
6.5 快速退出:quick_exit与at_quick_exit
有关终止的函数:
terminate:terminate函数式c++异常处理的一部分,包含在<exception>头文件里。没有被捕捉的异常就会导致terminate函数的调用。terminate函数在默认情况下,会调用abort函数,不过用户可以通过set_terminate函数来改变默认行为。
abort:abort函数不会调用任何析构函数,默认情况下,它会向合乎POSIX标准的系统抛出一个信号:SIGABRT。如果为信号设定一个信号处理程序的话,操作系统将默认地释放进程所有的资源,从而终止程序。
exit:exit函数会正常调动自动变量的析构函数,还会调用atexit注册的函数,属于正常退出的范畴。
main或者使用exit函数调用结束程序,会导致类的析构函数依次将零散的内存还给操作系统,这是意见费时的工作,实际上,这些内存将在进程结束时由操作系统统一回收。这种情况下,我们往往需要能够更快地退出程序。
在多线程情况下,我们要使用 exit 函数来退出程序的话,通常需要向线程发出一个信号,并等待线程结束后再执行析构函数、atexit 注册的函数等。这样的退出方式有的时候并不能够像预期那样工作,比如说线程中的程序在等待 I/O 行结束等。在一些更为复杂的情况下,可能还会遭遇到一些因为信号顺序而导致的死锁状况。一旦出现了这样的问题,程序往往就会被“卡死”而无法退出。
为此c++11标准引入了quick_exit函数,该函数不执行析构函数而只是使程序终止。quick_exit函数也属于正常退出。使用at_quick_exit注册函数也可以在quick_exit的时候被调用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!